- The paper presents that plain MLPs can exceed state-of-the-art denoising baselines and even surpass established theoretical performance bounds.
- It employs a patch-based approach with multi-layer perceptrons trained via SGD on vast noisy-clean datasets, achieving notable PSNR improvements.
- Experimental results show MLPs perform exceptionally on images with irregular structures and diverse noise types, though with limitations on highly regular patterns.
Introduction and Motivation
This paper presents a comprehensive study on image denoising using plain multi-layer perceptrons (MLPs) trained on large datasets of noisy-clean patch pairs, with an emphasis on a systematic empirical comparison against engineered algorithms and an analysis relative to established theoretical denoising bounds (1211.1544). The core research hypothesis is that, with sufficient representational capacity and data, feedforward neural networks can match or surpass the state-of-the-art in image denoising, even without explicit modeling of image priors or self-similarity.
The denoising task is formalized as learning a high-dimensional, non-linear mapping from noisy image patches to clean counterparts. The approach adopts patch-based decomposition and reconstruction, enabling both computational tractability and comparisons with prior methods. The study uniquely positions itself through a thorough aggregation of quantitative results across test sets, noise types, and a critical examination of model assumptions underlying previous "theoretical limits" in denoising research.
MLP Architecture, Training, and Implementation
The authors deploy large-capacity, fully connected feedforward neural networks with up to five hidden layers, using tanh activations. The patch sizes are chosen according to the noise regime: larger patches are used at higher noise levels to capture sufficient context for reliable denoising.
MLP parameters are trained via SGD with backpropagation, using mean-squared error (MSE) loss, which is monotonically related to PSNR—facilitating direct quantitative benchmarking. Standard training heuristics such as weight normalization, data normalization, and layer-wise adaptive learning rates are utilized. Training examples are generated on the fly by corrupting randomly-sampled clean patches from ImageNet with controlled noise, ensuring essentially infinite noise diversity.
Performance constraints are addressed via GPU-accelerated implementations; denoising an image of moderate size takes less than five seconds on modern hardware, which, while not as fast as BM3D, is significantly faster than dictionary learning methods such as KSVD and NLSC.
The patch selection and overlapping strategy for reconstructing full images from denoised patches is tuned for a favorable trade-off between quality and computational overhead.
Empirical Evaluation: Comparison with SOTA Algorithms
Quantitative Results on Standard Datasets
A series of experiments rigorously evaluate the trained MLPs against leading algorithms, including BM3D, NLSC, EPLL, and KSVD, across six carefully selected test sets (including "standard" images, BSDS500, Pascal VOC, McGill, and held-out ImageNet). The focus is additive white Gaussian (AWG) noise at multiple noise levels (σ=10,25,50,75,170).
The main findings can be summarized as follows:
- At medium to high noise levels (σ=25,50,75), MLPs outperform BM3D and NLSC on over 90% of images, with an average PSNR improvement of up to $0.36$dB.
- The gains are most pronounced on images with smooth surfaces and non-repetitive, irregular structures, whereas BM3D/NLSC retain an edge on highly regular, self-similar textures (Figure 1).
- At extremely high noise, the margin over BM3D and NLSC increases further, contradicting earlier claims that priors offer diminishing value in such regimes.









Figure 1: The MLP achieves superior denoising on images with irregular structure compared to BM3D, which excels on regular textures.
- At the lowest noise level (σ=10), the PSNR advantage of MLPs is minor (≈0.1 dB over BM3D), suggesting diminishing returns as the SNR increases.
These results are visually supported by per-image error maps and reconstructions, highlighting the structural contexts in which MLPs provide the largest gains.

Figure 2: Error map showing regions where MLP denoising exceeds BM3D on a complex image.
Further, the evaluation includes an extensive dataset-level analysis, confirming the robustness of the empirical findings beyond cherry-picked imagery.
Comparison Across Noise Types
Beyond AWG noise, the methodology is flexibly adapted to less conventional settings: mixed Poisson-Gaussian (photon-limited) noise, salt-and-pepper noise, structured (stripe) noise, and JPEG quantization artifacts. For these scenarios, MLPs trained specifically on noisy-clean pairs reflecting the corrupting process outperform specialized classical baselines in most cases.

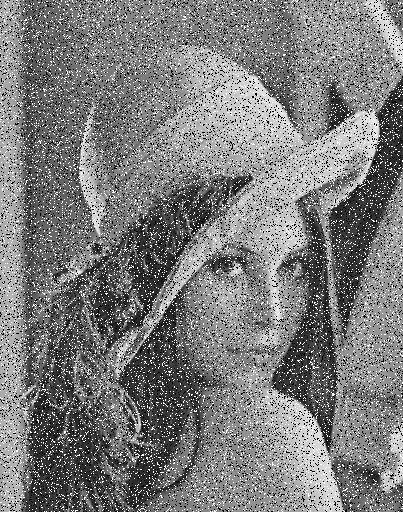







Figure 3: MLP-based denoising outperforms BM3D and median filtering on structured, salt-and-pepper, and JPEG artifact noise.
On mixed Poisson-Gaussian noise, the MLP approach yields especially strong results at high noise (low photon-count regime), outperforming state-of-the-art transformation-based and PURE-LET methods.






Figure 4: MLP denoising vs. GAT+BM3D on photon-limited images: stronger performance of MLP, especially at low peak signal.
Examination of Theoretical Denoising Limits
This work makes a strong empirical claim that the performance "bounds" derived under patch clustering and Bayesian modeling assumptions are not intrinsic barriers. The MLP-based denoisers systematically exceed these limits, particularly on images with complex structure, by relaxing the single-patch cluster assumption and employing higher-capacity function approximation.
Empirical reconstructions of downsampled/cropped images (e.g., "Peppers") at high noise levels outperform both the best analytical bound for fixed patch size and outpace BM3D by a non-negligible margin.

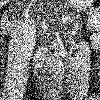

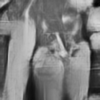
Figure 5: On downsized Peppers (σ=75), MLP denoising yields PSNR $0.34$ dB above BM3D, exceeding the theoretical improvement predicted for finite patch sizes.
Analysis of recent Bayesian bounds extrapolated to infinite patch size suggests that MLPs account for up to half of the remaining improvement possible over BM3D, with the gap narrowing as noise increases and patch size grows—supporting the view that large capacity models provide superior exploitation of available information.
Block-Matching MLPs and Architectural Refinements
Given BM3D's strength on images with strong self-similarity, the authors develop a hybrid variant: block-matching MLPs that consume not just the reference patch but also its closest neighbors (in terms of ℓ2 distance) as additional input. This modification yields PSNR gains on images with regular patterns (e.g., "Barbara", "House") but impacts performance on smooth surfaces due to smaller patch sizes and context window limitations.
The average performance gain across all datasets is marginal (+0.01dB), and the increased computational complexity and task specificity limit the practical value of block-matching MLPs compared to the plain MLP architecture.


Figure 6: Visualization of regions where block-matching MLPs improve over plain MLPs; gains are concentrated in regular structures.
Discussion and Future Directions
This work demonstrates that sufficiently large plain MLPs, trained on vast and representative datasets of noisy-clean patch pairs, can compete with or surpass meticulously engineered image denoisers—even without incorporating explicit prior knowledge of patch similarity or handcrafted features. The flexibility of the training regime allows adaptation to a wide range of noise models by simply modifying the data generating process.
Strong empirical results, particularly in surpassing previously established theoretical denoising bounds, challenge the received wisdom regarding the limits of patch-based denoising. The authors argue that critical model assumptions—such as the limited expressivity of cluster-based denoising or the sufficiency of small patches—do not account for the potential representational power unlocked by large neural networks with sufficient training resources.
However, the work also identifies persistent weaknesses: the MLP approach, while robust, does not dominate in all image classes, especially those with highly regular, repetitive patterns that benefit from self-similarity aggregation. Attempts to rectify this via block-matching input structures bring only partial, context-dependent improvement.
The practical implication is that ensemble or cascaded denoising strategies combining multiple algorithmic paradigms may achieve the most consistently high performance—motivating subsequent research into meta-denoising and adaptive frameworks.
Conclusion
The paper provides compelling evidence that patch-based MLPs, when optimally scaled in layer depth, width, and training data, transcend both algorithmic and theoretical barriers posited by prior denoising literature. The methodology delivers state-of-the-art denoising performance, robust adaptability to diverse noise models, and exposes the limitations of prevailing theoretical analyses on denoising bounds. Future work in low-level vision and other imaging modalities stands to benefit from these insights, with open questions remaining on joint architectures, unsupervised domain adaptation, and the design of universally optimal denoisers.