- The paper introduces a deconvnet method that visualizes feature activations of CNN layers, revealing the hierarchical nature of learned features.
- It demonstrates that early layers capture basic edges while higher layers represent complex and semantic object parts.
- The study highlights that improved visualization techniques can enhance model interpretability and provide diagnostic insights for network refinement.
Visualizing and Understanding Convolutional Networks
Convolutional Neural Networks (CNNs) have achieved remarkable success in challenging visual classification tasks, yet the underlying mechanisms contributing to their efficacy often remain opaque. The paper "Visualizing and Understanding Convolutional Networks" (1311.2901) offers insights into the functionality of CNNs via novel visualization techniques, demonstrating how the activations and structure across different layers correlate with performance. This essay delivers an expert review of the contributions, methodologies, and implications of the research presented.
Introduction to Convolutional Networks
Convolutional Networks (ConvNets) arose in the late 1980s with initial applications in tasks such as digit classification and face recognition. While early works underscored their potential, recent advances—bolstered by access to extensive datasets, significant computational power, and advanced regularization techniques—have expanded their application to more complex tasks, achieving unprecedented accuracy rates, as evidenced by Krizhevsky et al.'s performance on the ImageNet benchmark. However, a gap exists in comprehending why CNNs perform so well. This paper introduces advanced visualization techniques to bridge this gap, offering new revelations about CNN layer operations and the classifier itself.
Methodology and Visualization
Key to understanding CNNs is interpreting the activity across their layers. The authors employ a novel deconvolutional network (deconvnet) approach, developed by Zeiler and Fergus, to trace CNN feature activations back to the input pixel space. This method elucidates which stimulus patterns trigger feature map activations, allowing observers to discern how features are built through layers.
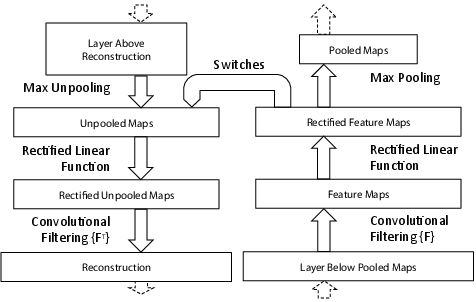
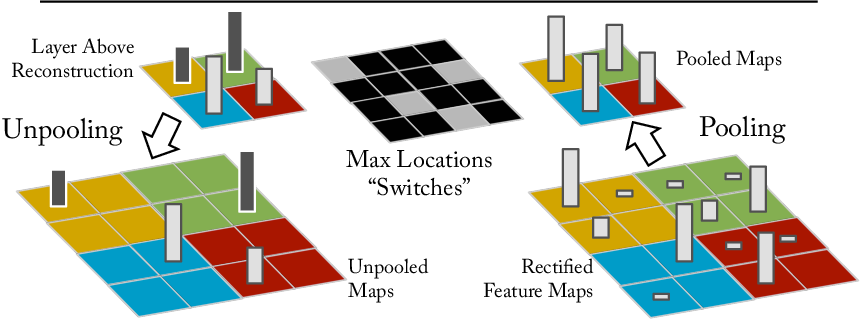
Figure 1: A deconvnet layer (left) attached to a convnet layer (right). The deconvnet will reconstruct an approximate version of the convnet features from the layer beneath.
This approach employs three operations within the deconvnet: unpooling (using switches that record locations of max activations during pooling), rectification (using ReLU non-linearities to ensure positive feature reconstructions), and filtering (inverting the convolutional filtering process). The visualizations reveal the hierarchical nature of feature maps: simple edges detected in initial layers progress to complex shapes and textures in subsequent layers.
Experimental Insights
The paper's experiments were broad and encompassed comprehensive analyses of CNN layers. A primary focus was architectural exploration and its impact on performance. The authors started with the CNN architecture proposed by Krizhevsky et al., subsequently refining it to enhance classification rates, particularly on ImageNet, thus achieving superior results over previous benchmarks.

Figure 2: Visualization of features in a fully trained model. We show the top activations across feature maps, projected back to pixel space.
The deconvnet visualizations depicted in Figure 2 show a conspicuous representation and interaction of features at varying depths. Lower layers capture fundamental edges and patterns, while higher layers reveal more semantic, recognizable parts of objects, underscoring that depth in architecture is a critical facet of effective feature representation.
Practical Implications and Future Directions
The practical utility of the visualization technique extends to both model refinement and understanding, offering a diagnostic tool to optimize networks efficiently. The research further demonstrated transferable features from CNNs pre-trained on ImageNet to other datasets (e.g., Caltech, PASCAL), showcasing their generalization capability—particularly where data scarcity is a concern.
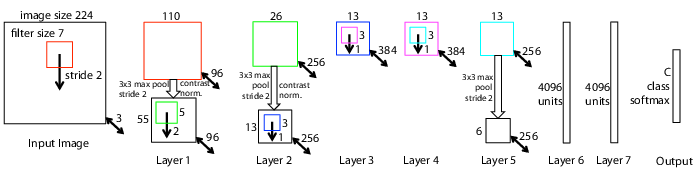
Figure 3: Architecture of our 8-layer convnet model with detailed layer operations.
Given these advancements, potential future work involves leveraging these visualizations to improve model interpretability and robustness. Specifically, more refined visualization techniques might address aspects like model fairness and bias probing, especially amid increasing requirements for transparency in AI systems.
Conclusion
"Visualizing and Understanding Convolutional Networks" brings forth a pivotal methodology for introspecting and optimizing CNN architectures. Through deconvnets, the study not only clarifies CNN operational mechanics but also extends their application by validating generalizability across traditional and novel datasets. Such work solidifies a foundational understanding for crafting more effective, interpretable, and general-purpose models in computer vision.