- The paper introduces a Bayesian view on dropout, enabling model selection by optimizing dropout rates as weights in neural networks.
- It presents a variational approach that leverages fast dropout approximations to improve test accuracy, reaching performance near theoretical limits.
- The framework bridges Bayesian inference and regularization, providing practical strategies to mitigate overfitting in high-dimensional data scenarios.
A Bayesian Encourages Dropout: An Expert Overview
Introduction
The paper "A Bayesian encourages dropout" (1412.7003) offers a novel interpretation of the dropout technique, a regularization method essential for preventing overfitting in large-scale neural networks. It extends the traditional understanding of dropout beyond modified L2 regularization by providing a Bayesian perspective. This insight enables the optimization of dropout rates, enhancing parameter learning and predictions. The dropout method, pivotal for various tasks such as image recognition and NLP, has been traditionally viewed as an innovative input-invariant regularization approach. However, this paper reframes dropout as an approximate Bayesian model averaging approach, facilitating model selection through the optimization of dropout rates.
Bayesian Interpretation of Dropout
Model and Training
The paper presents a Bayesian viewpoint where dropout serves as a method for model selection through Bayesian averaging. The model selection problem implies choosing subsets from input features or hidden units in neural networks. Standard dropout stochastically mixes all potential models rather than selecting a specific mask. This approach aligns with the Bayesian model averaging concept, where inference post-training is seen as approximate Bayesian inference. To operationalize this, the paper introduces a Bayesian framework that optimizes dropout rates as model weights, improving marginal and predictive likelihood approximations.
Prediction and Optimization
For prediction, dropout is treated as a weighted average of model predictions, an approximate expectation using trial distributions over model masks. The approximation involves techniques such as 'fast dropout', which replaces the weighted random variable sum with a Gaussian equivalent, optimizing computational time and accuracy. This comprehensive Bayesian framework culminates in an algorithm for variably optimizing dropout rates, leading to superior Bayesian model approximations and parameter learning.
Experimentation and Results
The efficacy of optimizing dropout rates through this Bayesian methodology is validated via binary classification experiments. With a binary label target and a mix of informative and non-informative features, the experiments contrast the accuracy of various dropout strategies. Performance indices indicate that optimizing feature-wise dropout rates (DOR dropout) achieves test accuracies approaching theoretical limits, outperforming standard methods (Figure 1).
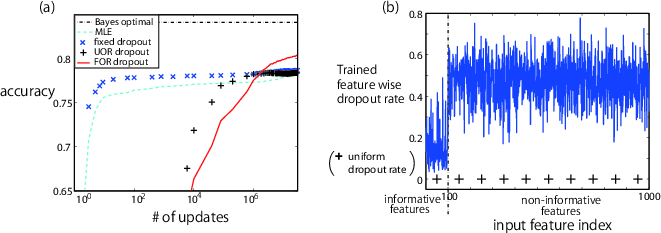
Figure 1: Experimental results (a) Test accuracy \quad (b) Dropout rate after learning.
Discussion
Theoretical Implications
The Bayesian framework reframes dropout as a method that better navigates the vast model space inherent in neural networks. The standard dropout algorithm is shown as an efficient approximation of Bayesian inference by constraining the posterior search over dropout rates. The paper discusses how neural network model selection aligns with Bayesian principles, offering mathematical grounding for dropout's regularization effects and bridging it with foundational statistical learning insights. This Bayesian approach delineates overfitting resistance not achievable by maximum likelihood estimates, providing a rationale for dropout's empirical success.
Practical Implications and Future Directions
Practically, the exploration of dropout's Bayesian implications could inform adaptive regularization strategies in machine learning models, particularly those dealing with high-dimensional data. The methodology offers pathways for innovative model selection processes, potentially optimized for task-specific requirements in large datasets. Future research could explore efficient algorithms for broader parameter distributions, and adaptive dropout mechanisms tailored to dynamic learning scenarios, further integrating Bayesian principles into complex real-world applications.
Conclusion
"A Bayesian encourages dropout" presents a significant step in interpreting and optimizing dropout techniques within neural networks. By integrating a Bayesian perspective, the paper offers a method to enhance learning and inference through dropout rate optimization. This work emphasizes the utility of Bayesian model averaging in addressing model selection problems and demonstrates the practical benefits of this approach in mitigating overfitting, potentially leading to more robust and adaptable neural network architectures.