- The paper introduces efficient algorithms for computing persistence landscapes from birth-death pairs, optimizing their use in statistical analysis.
- It details merge-based averaging and robust L^p and L^∞ distance calculations, reducing computational overhead for TDA applications.
- Experimental validations demonstrate intrinsic dimension detection and superior performance compared to traditional methods.
Introduction to Topological Data Analysis
Topological data analysis (TDA) offers a multiscale analysis of quantitative data by leveraging tools from topology and geometry. The persistence landscape is a crucial tool in TDA that provides a topological summary of data, which can be effectively combined with statistical and machine learning techniques. This paper introduces efficient algorithms for calculating persistence landscapes, their averages, and distances between such averages, facilitating the integration of TDA with statistical and machine learning methodologies.
The persistence landscape, derived from persistence modules, offers a linear representation of data that simplifies operations like calculating averages, which traditionally posed challenges with barcodes and persistence diagrams. The persistence landscape lies within a Hilbert space, enabling application of standard machine learning techniques via associated kernels.
Algorithms and Implementation
Persistence Landscapes
Algorithms developed in this paper aim to streamline the computation of persistence landscapes from birth-death pairs. The first algorithm, operating in O(n2) time, efficiently computes persistence landscapes from a list of birth-death pairs. Another algorithm, optimized for scenarios where data points lie on a discrete grid, achieves O(mnlogn) complexity.
These algorithms address the unique challenges presented by topological summaries, enabling a stable and computationally feasible approach to persistence landscapes. The implementation provides a toolbox for exact computation and grid-based approximations, allowing users to switch between modes for efficiency optimization, depending on their data's characteristics.
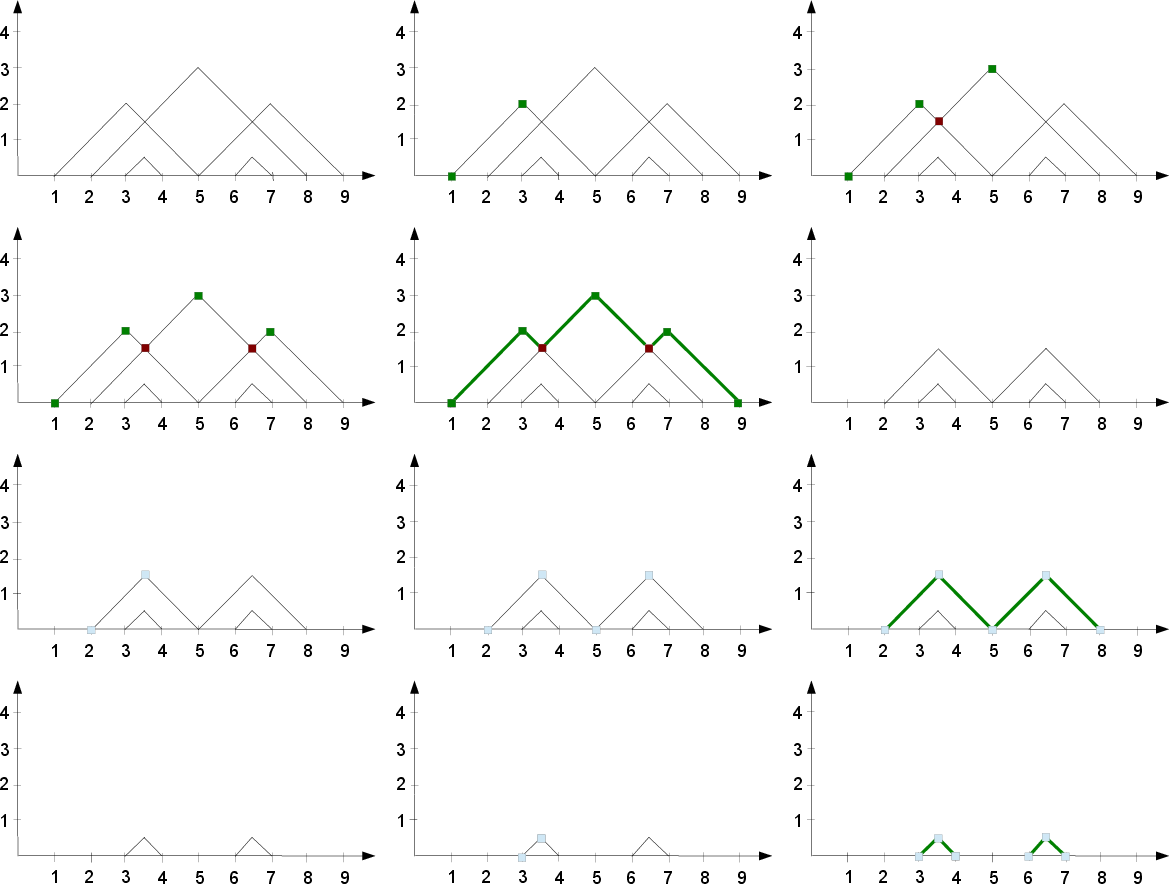
Figure 1: Algorithm~\ref{alg:landscapePoints}.
Average and Linear Combinations
The paper outlines procedures for computing averages of persistence landscapes via efficient algorithms employing binary tree merging strategies, significantly reducing computational overhead. The resulting average persistence landscapes facilitate topological statistics applications by providing interpretable summaries of shapes' intrinsic dimensions and facilitating hypothesis testing.
Furthermore, linear combinations of persistence landscapes are computed with complexity O(n2NlogN), supporting operations necessary for statistical analyses over TDA outputs.
Distance Calculations
The paper also details mechanisms for calculating Lp and L∞ distances between persistence landscapes, enabling practical applications in statistical inference and classification tasks. These distance measures offer robust solutions for quantitative comparisons between datasets within a topological framework.
Overall, the algorithms empower researchers to integrate persistence landscapes seamlessly into statistical methodologies, optimizing the utility of TDA in machine learning contexts.
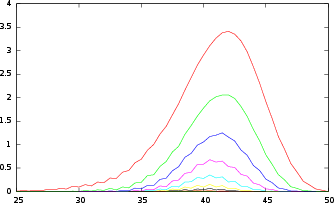
Figure 2: Average persistence landscapes in degree 2 of points sampled from Sd.
Experimental Validations
Intrinsic Dimension Detection
By performing experiments with data sampled from spheres and boxes of varying dimensions, the paper demonstrates the ability of persistence landscapes to discern intrinsic data dimensions. The consistency of detected dimensions across experiments reinforces the role of persistence landscapes in estimating data complexity and guiding decisions in high-dimensional settings.
Computational Efficiency
The presented computational benchmarks showcase significant performance improvements in distance calculation times between persistence landscapes compared to traditional methods like Bottleneck and Wasserstein distances. The results indicate that persistence landscapes offer a viable alternative with computational advantages, advocating their integration into large-scale TDA applications.
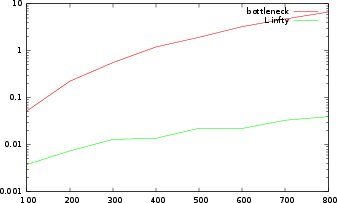
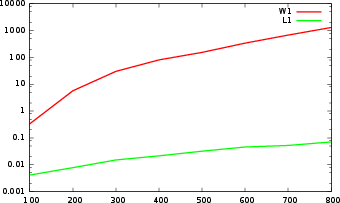
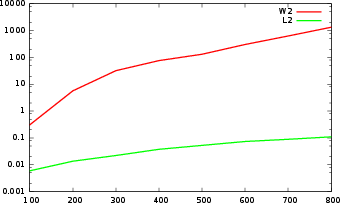
Figure 3: Comparison of time of distance computations: (a) Bottleneck versus L∞.
Practical Applications and Future Directions
The persistence landscapes toolbox, through its optimized algorithms and versatile implementation, positions itself as an essential resource for the statistical analysis of topological data. By enabling effective classification, hypothesis testing, and intrinsic dimension estimation, it enhances the applicability of TDA in machine learning and statistical contexts.
The paper suggests further development of persistence landscape algorithms and the exploration of alternative strategies for computing landscape features, underlining the potential for broader adoption and refinement of TDA methodologies in data-driven research.
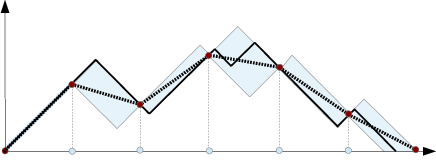
Figure 4: Exact versus grid-based estimate of the persistence landscape.
Conclusion
This paper contributes significantly to the field of topological data analysis by delivering efficient and implementable algorithms for calculating and using persistence landscapes in statistical applications. The implementation details provide a foundation for future innovations in TDA, driving integration with machine learning tools and facilitating high-dimensional data analysis with topological techniques. The approaches outlined herein set the stage for continued advancement in applying topology to real-world scientific challenges.


