- The paper presents a novel statistical framework that models language-specific covariance structures through log-spectrogram analysis.
- It leverages functional data analysis and permutation tests to robustly quantify phonetic variations among French, Italian, Portuguese, and Spanish recordings.
- The study lays groundwork for phonetic transformation modeling, offering potential applications in speech synthesis and historical linguistics.
Statistical Analysis of Acoustic Phonetic Data: A Comprehensive Study on Romance Languages
The paper "The Statistical Analysis of Acoustic Phonetic Data: Exploring Differences Between Spoken Romance Languages" (1507.07587) presents a novel framework for analyzing acoustic phonetic data to explore phonetic variation and evolution among Romance languages. Using time-frequency representations, the authors focus on log-spectrograms of speech recordings to identify distinctive phonetic features. This essay provides an academic analysis of the methods, results, implications, and potential future avenues suggested by this research.
Methodology and Framework
The authors propose a statistical approach to model the acoustic properties of spoken words, emphasizing covariance functions as key features distinguishing languages. By leveraging functional data analysis, the paper outlines methods for estimating these covariance structures and explores the potential for transforming individual speaker recordings across different languages while preserving voice characteristics.
The study utilizes a dataset comprising audio recordings of digits from one to ten, pronounced by speakers of French, Italian, Portuguese, American Spanish, and Iberian Spanish. This real-world dataset highlights intra-language variability due to the non-laboratory conditions under which recordings were collected. The recordings are processed to generate log-spectrogram surfaces using local Fourier transforms, which are then smoothed and temporally aligned to eliminate noise and misalignment.
Estimation and Statistical Tests
One significant contribution is the assumption and verification that the covariance structure is language-specific but consistent across different words. The authors use permutation tests to substantiate this hypothesis, applying Procrustes reflection size-and-shape distances to evaluate discrepancies in estimated covariance operators across words for each language.
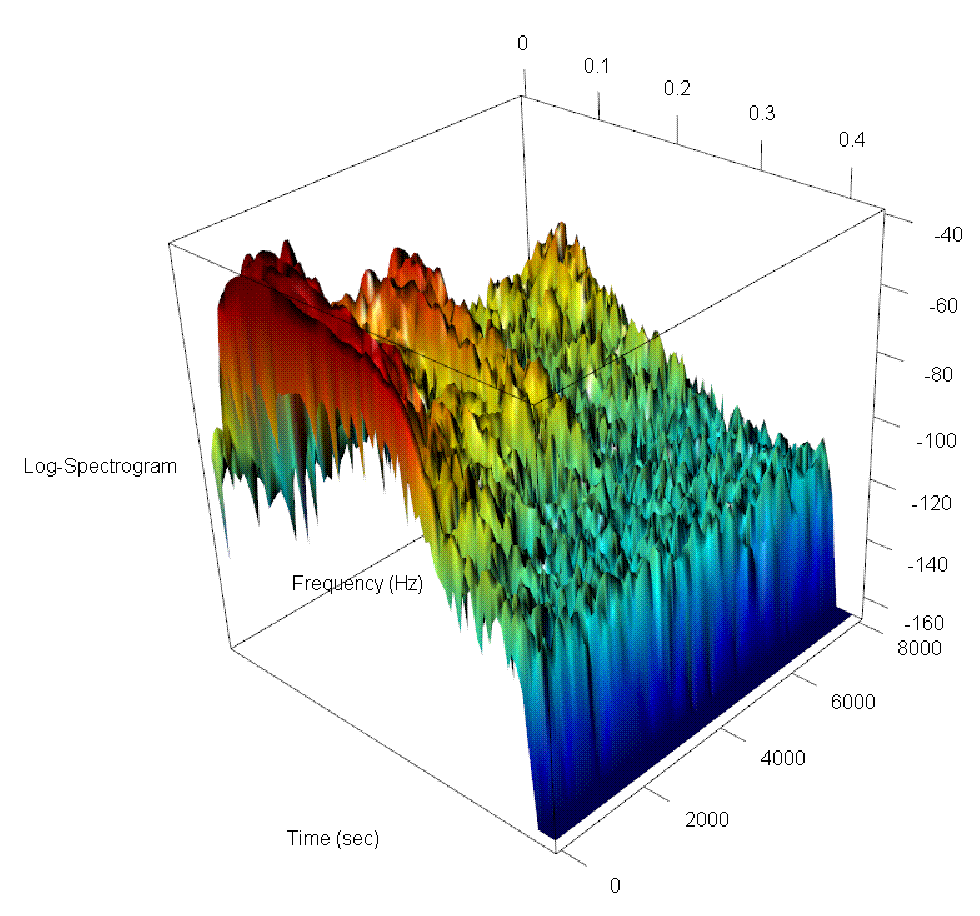
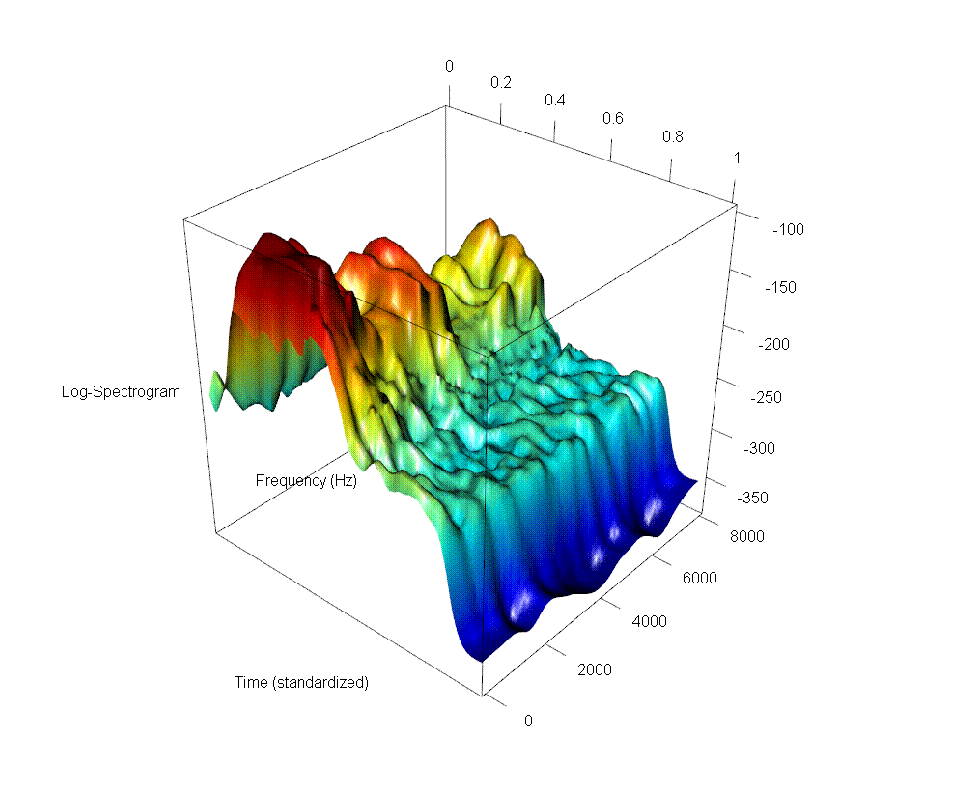
Figure 1: Raw record (top), raw log-spectrogram (bottom left), and smoothed and aligned log-spectrogram (bottom right) for a French speaker pronouncing the word "un" ("one").
Figures 2 and 3 (not displayed here) illustrate the estimated marginal covariance functions for frequencies and times, demonstrating clear language-specific patterns, particularly in frequency structures, which are critical in characterizing what a language "sounds like".
A core component of the study is the modeling of phonetic transformations that hypothesize how a speaker from one language would sound if speaking another language, using Gaussian process models to structure these changes. The authors introduce the concept of interpolating and extrapolating acoustic structures across languages, supported by geodesic interpolation for covariance estimation, offering pathways to reconstruct the historical phonetic paths between languages.
The authors visually and audibly track incremental changes in pronunciation through log-spectrogram interpolations, such as the transition from the French "un" to the Portuguese "um".
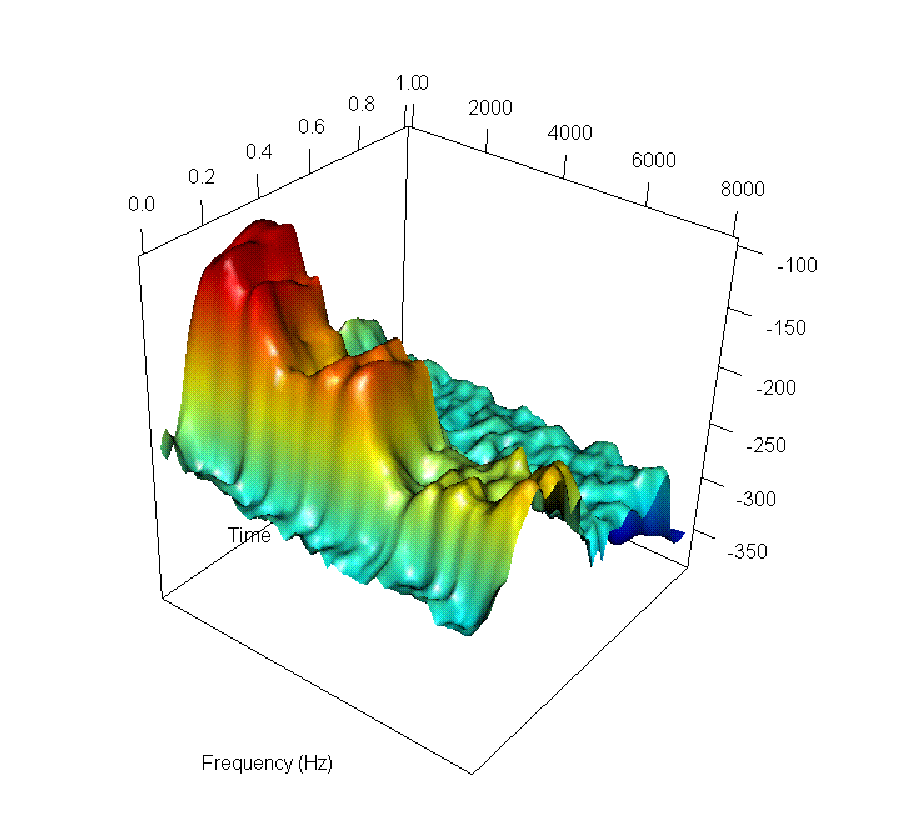
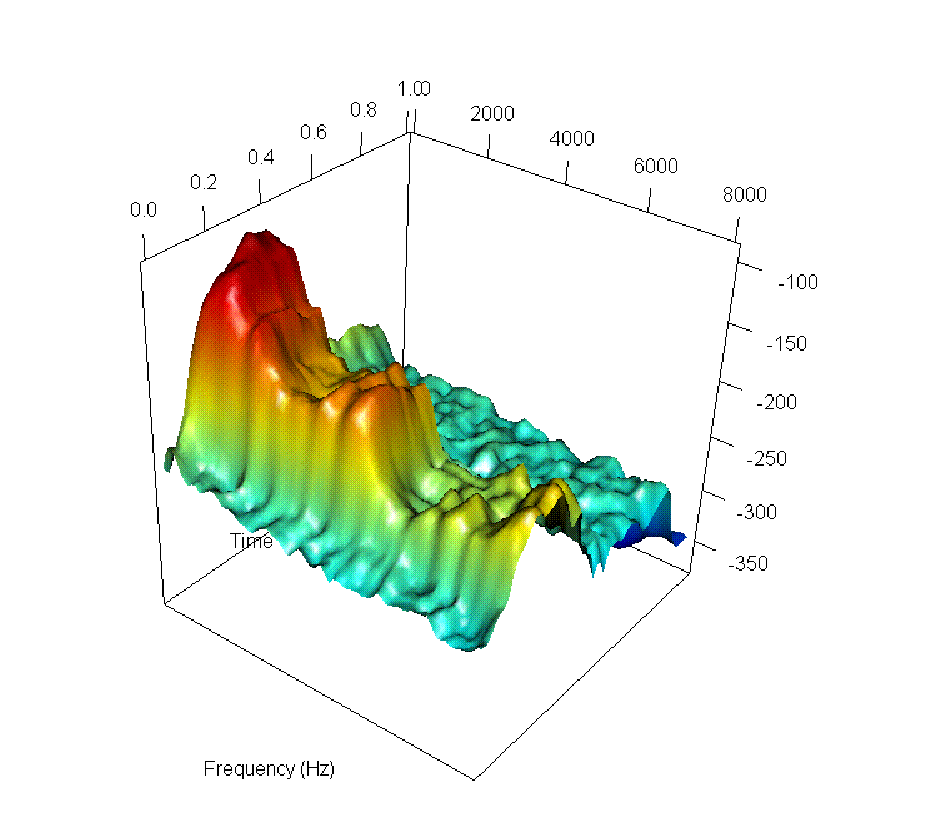
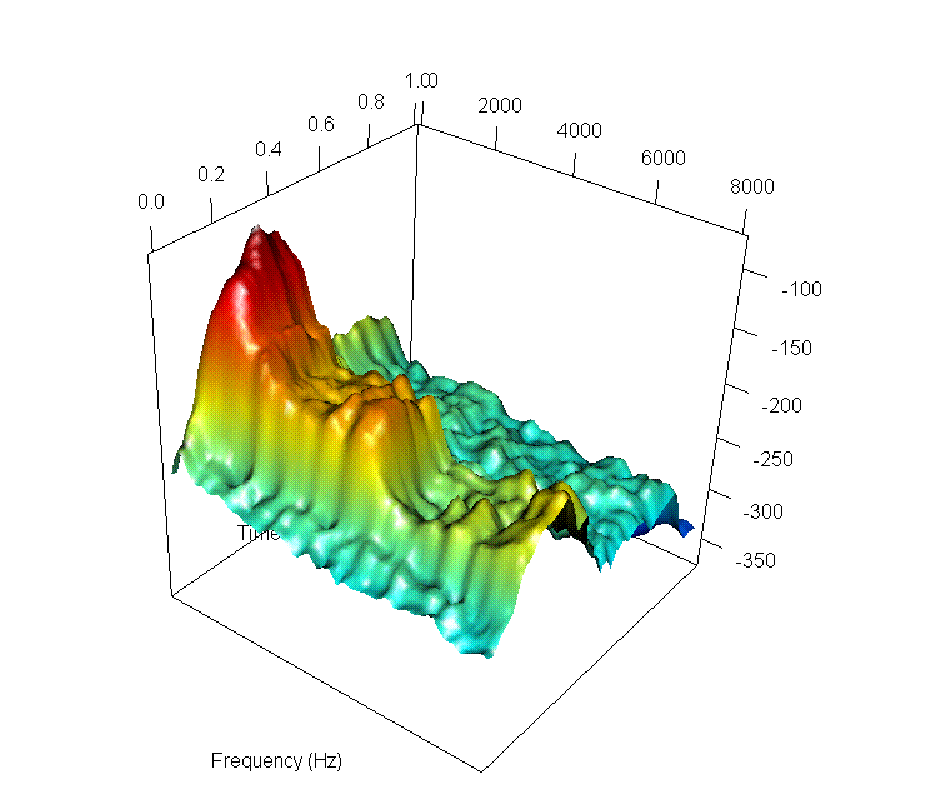
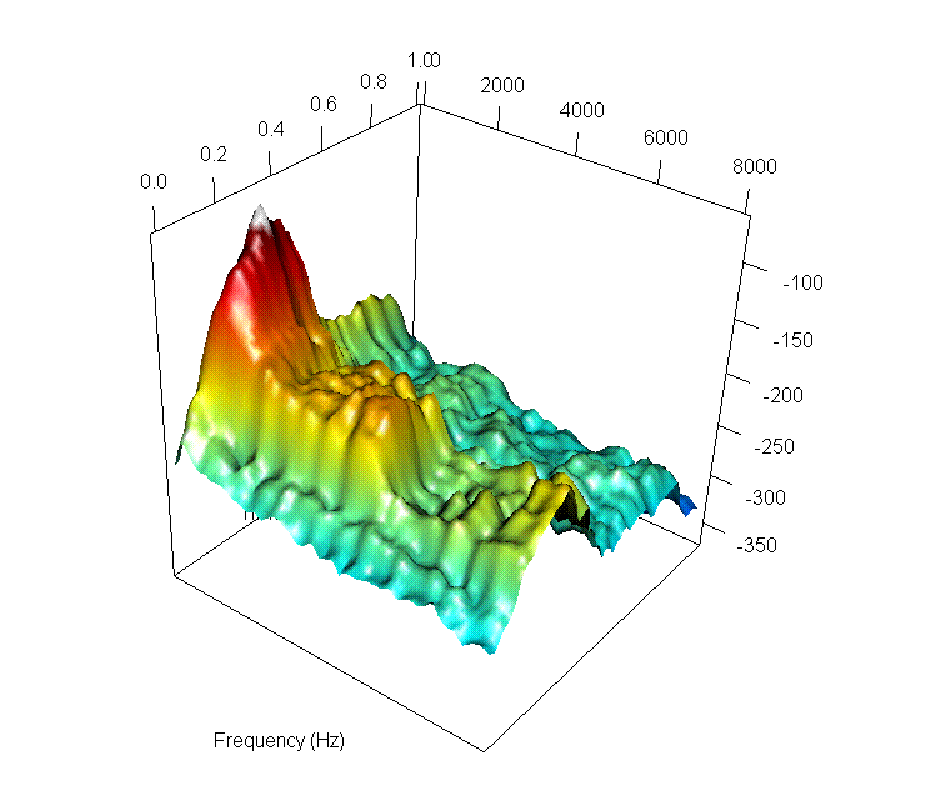
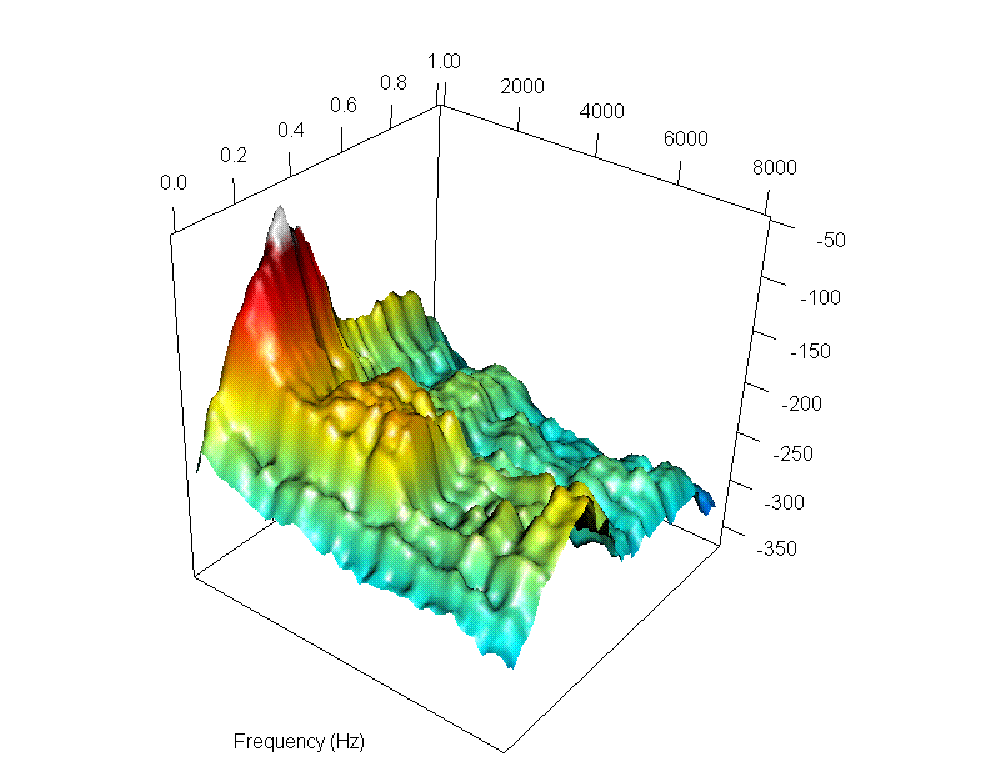
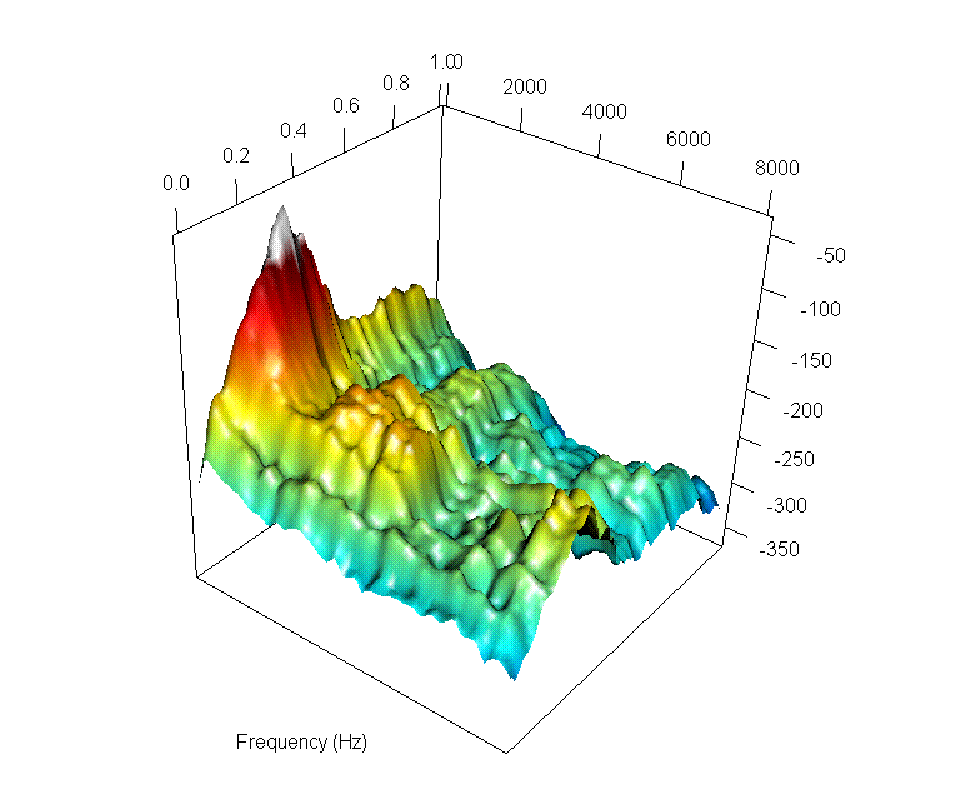
Figure 2: Six steps along the smooth path between the log-spectrogram for the word "un" ("one") as spoken by a French speaker (top left) and its representation in Portuguese (bottom right).
Implications and Future Directions
This research holds significant implications for comparative linguistics and speech synthesis. By providing a methodology to separate speaker-specific voice traits from language-specific pronunciation details, it opens new avenues for accurate language reconstruction and synthetic speech applications. This framework could enhance linguistic analysis by allowing data-driven exploration of phonetic evolution, supporting the broader endeavor to recreate proto-language sounds.
The paper suggests further research in integrating historical and geographic information into sound evolution models. Future studies may expand the corpus for greater representativeness and incorporate sophisticated models of linguistic change that reflect socio-cultural dynamics and contact-induced change.
Conclusion
The paper presents a rigorous approach to studying the acoustic characteristics of spoken Romance languages, leveraging statistical analysis as a powerful tool for phonetic exploration. By modeling phonetic variance and transformation, it lays the groundwork for significant advancements in understanding language history and speech processing technologies. The innovative methodologies proposed encourage further exploration into the evolving nature of human language, beyond the theoretical into practical applications of synthetic speech and linguistic archaeology.