- The paper presents the FederatedAveraging algorithm that significantly reduces communication rounds while maintaining model accuracy.
- It demonstrates that local SGD updates, when aggregated from decentralized devices, effectively handle non-IID and unbalanced data.
- Experimental results on datasets like CIFAR-10 and MNIST show that FedAvg achieves competitive performance with up to 100 times less communication compared to standard SGD.
Overview of Federated Learning for Deep Networks on Decentralized Data
The paper "Communication-Efficient Learning of Deep Networks from Decentralized Data" (1602.05629) introduces Federated Learning as a pragmatic approach to training machine learning models on data distributed across multiple devices, such as mobile phones, without requiring centralized data storage. The primary contribution is the "FederatedAveraging" algorithm, which facilitates efficient model training in a decentralized manner. This essay examines the paper, detailing its methods, results, impacts, and potential future developments in AI.
Federated Learning Framework
Motivation and Problem Addressed
This research identifies the unique challenge of leveraging data from ever-increasing mobile devices while respecting user privacy and sidestepping data centralization. The specific problem addressed is the training of models on protected or large datasets, where traditional centralized data center-based training would expose sensitive individual data to privacy risks. Federated learning deploys the client-server structure where the server aggregates locally computed model updates from several clients, which remain decentralized. This model not only respects privacy constraints but also utilizes computational power at the edge of the network.
FederatedAveraging Algorithm
The "FederatedAveraging" (FedAvg) algorithm, an extension of stochastic gradient descent (SGD), addresses the unique characteristics of federated optimization such as non-IID, unbalanced data, massively distributed clients, and constrained communication. The approach hinges on local SGD execution followed by averaging updates on a central server for model aggregation.
The central computation of the FedAvg algorithm involves each client executing local SGD for E epochs over its local data and then sending the computed update, rather than the raw data, back to the server, which averages these updates to refine the global model.
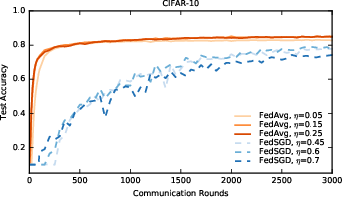
Figure 1: Test accuracy versus communication for the CIFAR10 experiments. FedSGD uses a learning-rate decay of 0.9934 per round; FedAvg uses B=50, learning-rate decay of 0.99 per round, and E=5.
Privacy Implications
In the federated setting, the privacy of the clients' data sets remains protected, as only the necessary model updates, devoid of irrelevant information, are communicated. This mechanism reduces the attack surface to individual devices while aligned with differential privacy can further reinforce data protection. It represents a strategic shift from reliance on data centralization toward data minimization.
Experimental Evaluation
The empirical analysis involves different model architectures: MLPs, CNNs, and LSTMs, across four datasets including MNIST, Shakespeare, and CIFAR-10, each chosen to reflect real-world decentralized data scenarios. The research highlights the robustness of federated learning on both IID and non-IID data distributions. Notably, FedAvg exhibited significant communication efficiency, requiring 10--100 times fewer communication rounds than conventional SGDs for model convergence.
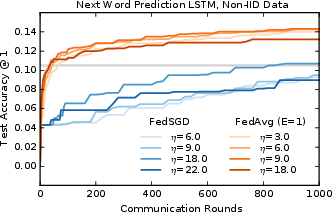
Figure 2: Monotonic learning curves for the large-scale LLM word LSTM.
The non-IID, unbalanced, and communication-constrained nature of federated optimization demands specific algorithmic solutions. FedAvg stands out by reducing communication rounds while maintaining robust accuracy. However, challenges such as data heterogeneity and reliability of client participation emerge as areas for further exploration.
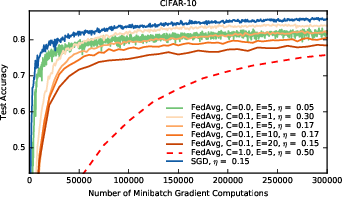
Figure 3: Test accuracy versus number of minibatch gradient computations (B=50). The baseline is standard sequential SGD, as compared to FedAvg with different client fractions C (recall C=0 means one client per round), and different numbers of local epochs E.
Conclusions and Future Directions
The study validates federated learning as a viable method for developing deep learning models without traditional data center dependence. Results underscore FedAvg's ability to scale effectively to decentralized environments. Future work may explore enhanced privacy guarantees using differential privacy and secure multiparty computation, alongside adaptations to optimize model architectures or learning algorithms to further improve performance and communication efficiency.
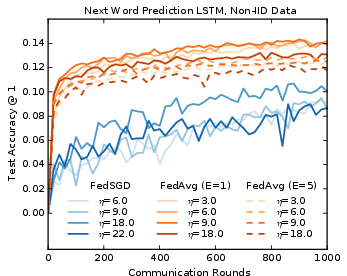
Figure 4: Learning curves for the large-scale LLM word LSTM, with evaluation computed every 20 rounds. FedAvg actually performs better with fewer local epochs E (1 vs 5), and also has lower variance in accuracy across evaluation rounds compared to FedSGD.