- The paper introduces Gradient-weighted Class Activation Mapping (Grad-CAM) to visualize CNN predictions using gradient information.
- It employs a general, architecture-agnostic approach to generate class-discriminative localization maps without re-training models.
- Results demonstrate improved performance in weakly-supervised tasks and provide insights into failure modes, aiding error diagnosis and bias detection.
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Introduction
Convolutional Neural Networks (CNNs) have become integral to numerous tasks within computer vision, such as image classification, object detection, and visual question answering, largely due to their superior accuracy. However, a significant challenge associated with these models is their interpretability, as understanding the decision-making process of deep CNNs remains opaque to both developers and end-users. The paper "Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization" (1610.02391) addresses this concern by introducing Gradient-weighted Class Activation Mapping (Grad-CAM), a method designed to provide visual explanations for model predictions, enhancing the transparency of CNNs while maintaining their architectural integrity and performance.
Methodology
Grad-CAM leverages the gradient information flowing into the last convolutional layer of a network to produce a localization map that highlights important regions in the input image concerning a specific class label. Unlike prior techniques that modify the network structure or require re-training, Grad-CAM is a general approach applicable to a wide range of CNN architectures, including those used in tasks with structured outputs, multi-modal inputs, or reinforcement learning, such as image captioning and visual question answering.
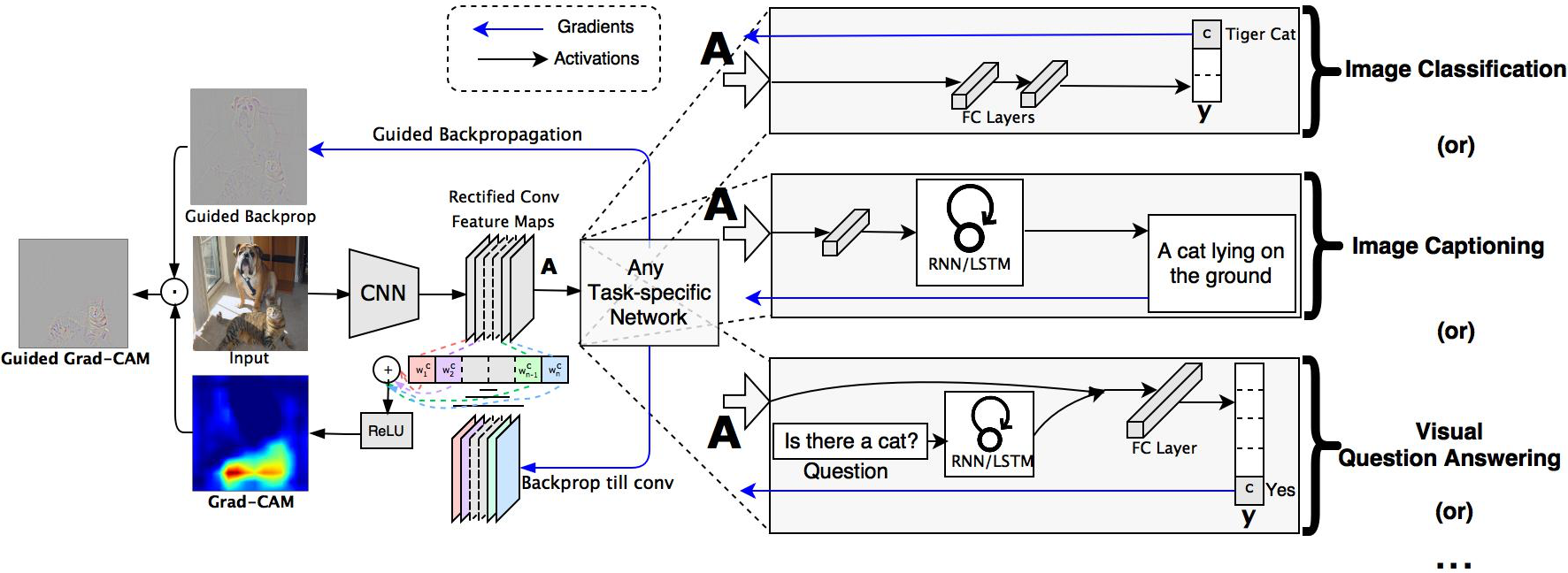
Figure 1: Grad-CAM overview: Given an image and a class of interest, we forward propagate the image through the CNN and then through task-specific computations to obtain a raw score for the category.
Grad-CAM is computed by taking the derivatives of the output score for a class with respect to feature map activations, pooling these gradients across the spatial dimensions to obtain class-specific weights, and then performing a weighted combination of these feature maps followed by a ReLU operation to highlight regions contributing positively to the prediction.
Applications and Results
Grad-CAM was evaluated across several tasks, including image classification and image captioning, and showed improved class-discriminative localization over existing methods like Class Activation Mapping (CAM). In weakly-supervised localization tasks, Grad-CAM achieved superior performance on the ILSVRC-15 dataset without sacrificing classification accuracy.
In the context of image captioning and visual question answering, Grad-CAM enabled the visualization of spatial attention, offering insights into which parts of an image most influenced specific words of the caption or answers to questions.
For image captioning models, Grad-CAM demonstrated its utility in assessing failure modes, providing insights into data bias and model predictions by visualizing the decision focus within an image, as seen in its successful correct localization of relevant objects despite adversarial noise.

Figure 2: PASCAL VOC 2012 Segmentation results with Grad-CAM as seed for SEC.
Implications and Future Work
The development of Grad-CAM has substantial implications for enhancing the interpretability of deep learning models in computer vision. By providing reliable visual explanations that are both class-discriminative and high-resolution, it empowers end-users and researchers to better trust and understand AI systems.
Additionally, Grad-CAM can serve as a tool for diagnosing model errors and biases, offering a means for identifying dataset biases and refining models for more equitable and accurate AI systems, which is especially critical as these models increasingly influence decision-making in society.
Looking forward, Grad-CAM presents exciting opportunities for extending interpretability tools to other domains of AI, including natural language processing and reinforcement learning, suggesting a broad potential for integrating explainability into various AI systems.
Conclusion
Grad-CAM provides a significant step toward transparent AI by delivering detailed visual explanations of model predictions while maintaining the performance and versatility of CNN architectures. Its ability to elucidate CNN decision processes across disparate tasks establishes it as a vital tool for researchers and practitioners aiming to deploy more understandable and reliable AI systems. As AI continues to pervade aspects of human decision-making, methods like Grad-CAM will likely play a critical role in fostering trust and safety in AI technologies.