Communication-Avoiding Parallel Algorithms for Solving Triangular Systems of Linear Equations
Published 6 Dec 2016 in cs.DC and cs.DS | (1612.01855v2)
Abstract: We present a new parallel algorithm for solving triangular systems with multiple right hand sides (TRSM). TRSM is used extensively in numerical linear algebra computations, both to solve triangular linear systems of equations as well as to compute factorizations with triangular matrices, such as Cholesky, LU, and QR. Our algorithm achieves better theoretical scalability than known alternatives, while maintaining numerical stability, via selective use of triangular matrix inversion. We leverage the fact that triangular inversion and matrix multiplication are more parallelizable than the standard TRSM algorithm. By only inverting triangular blocks along the diagonal of the initial matrix, we generalize the usual way of TRSM computation and the full matrix inversion approach. This flexibility leads to an efficient algorithm for any ratio of the number of right hand sides to the triangular matrix dimension. We provide a detailed communication cost analysis for our algorithm as well as for the recursive triangular matrix inversion. This cost analysis makes it possible to determine optimal block sizes and processor grids a priori. Relative to the best known algorithms for TRSM, our approach can require asymptotically fewer messages, while performing optimal amounts of computation and communication in terms of words sent.
The paper introduces a parallel algorithm that leverages selective triangular inversion to reduce synchronization costs in TRSM.
It provides a detailed cost analysis using the α-β-γ model and offers optimal tuning parameters for various processor grid layouts.
The method generalizes traditional TRSM computations, improving scalability and numerical stability across different ratios of right-hand sides.
Communication-Avoiding Parallel Algorithms for Solving Triangular Systems of Linear Equations
This paper introduces a novel parallel algorithm for solving triangular systems with multiple right-hand sides (TRSM), a crucial subroutine in numerical linear algebra. The algorithm strategically employs triangular matrix inversion to achieve better theoretical scalability and numerical stability compared to existing methods. By inverting only the triangular blocks along the diagonal, the approach generalizes traditional TRSM computations and full matrix inversion, leading to efficiency across various ratios of right-hand sides to the triangular matrix dimension.
Background and Motivation
TRSM is extensively used in numerical linear algebra, particularly in factorizations such as Cholesky, LU, and QR, as well as for solving linear systems after decomposition. The paper focuses on dense linear equations in the form LX=B, where L is a lower-triangular matrix of size n×n, and B and X are dense matrices of size n×k. The communication cost complexity of two TRSM algorithm variants is analyzed for parallel execution on p processors with unbounded memory.
Core Algorithmic Contributions
The key innovation lies in using selective triangular inversion to reduce synchronization costs while maintaining optimal communication and computation costs. The algorithm begins by inverting triangular diagonal blocks of the L matrix, increasing the computational granularity of the solver's main part. Unlike general matrix inversion, triangular inversion maintains numerical stability and requires fewer synchronizations.
The algorithm is formulated iteratively rather than recursively, avoiding the overheads associated with known parallel recursive TRSM approaches. This reduces communication costs by a factor of Θ(log(p)) compared to recursive algorithms when the number of right-hand sides is relatively small and achieves a synchronization cost improvement over the recursive approach by a factor of Θ((kn)1/6p2/3) across a wide range of input parameters.
Technical Details and Implementation
The paper provides an algorithm for 3D matrix multiplication suitable for analyzing TRSM algorithms, operating efficiently with cyclically distributed input matrices on a 2D processor grid. The matrix multiplication algorithm leverages a p1×p2×p1×p2 processor grid, where p=p1p2 to transition from a distribution on a p×p processor grid to faces of a 3D p1×p1×p2 processor grid.
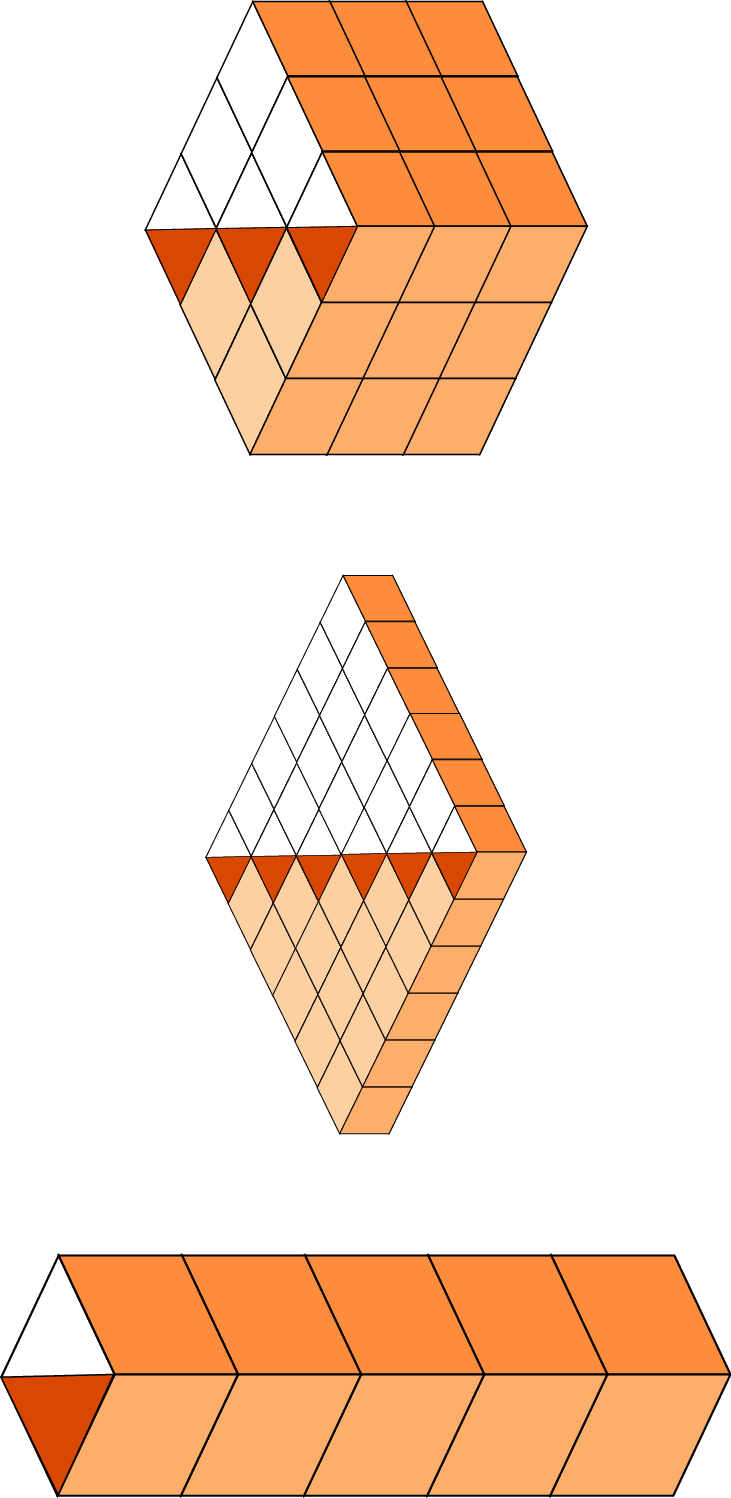
Figure 1: One-, two-, and three-dimensional layout dependent on relative matrix sizes; inverted blocks of the matrix in dark and input- and output of the right hand side on the left and right size of the cuboid.
The recursive TRSM algorithm solves LX=B recursively on a pr×pc processor grid, which is square (pr=pc) when n≥k and rectangular (pr<pc) when n<k. The algorithm starts by partitioning the processor grid and replicating the matrix L, computing a subset of columns of X on each. At a specified threshold n0, the algorithm stops recursing, gathers L onto all processors, and computes a subset of columns of X with each processor.
The iterative triangular solver leverages block-diagonal triangular inversion, where the initial matrix is cyclically distributed on the subgrid Π(∘,∘,1). The algorithm splits Π into n0n subgrids, each with dimensions r1×r1×r2, where r12r2=pnn0. Parallel inversions are then performed after transitioning from the original cyclic layout.
Performance Analysis and Optimization
The paper provides a detailed communication cost analysis using the α−β−γ model to calculate parallel execution time, considering floating-point operations (F), bandwidth (W), and latency (S). The analysis covers collective communication routines, matrix multiplication, triangular matrix solve for single right-hand sides, and recursive TRSM.
Optimal tuning parameters are provided for different relative matrix sizes to optimize performance. For a one-dimensional processor grid layout (n<p4k), the algorithm achieves a total cost of TIT1D(n,k,p)=O(α⋅(log2p+logp)+β⋅n2+γ⋅pn2k). For a two-dimensional layout (n>4kp), the total cost is $T_\mathrm{IT2D}(n,k,p) = \mathcal{O}\left(\alpha\left(\log^2 p + \left(\frac{n}{k}\right)^{3/4}\frac{1}{p^{1/8}\log p\right) + \beta\left(\frac{nk}{\sqrt{p}\right) + \gamma \left(\frac{n^2k}{\sqrt{p}\right)\right)$. For a three-dimensional layout (p4k≤n≤4kp), the total cost is $T_\mathrm{IT3D}(n,k,p) = \mathcal{O}\left(\alpha\left(\log^2 p + \max\left(\sqrt{\frac{n}{k},1\right) \log p\right) + \beta\left(\left(\frac{n^2k}{p}\right)^{2/3}\right) + \gamma \left(\frac{n^2k}{\sqrt{p}\right)\right)$.
Implications and Future Directions
The algorithm represents a significant advancement in parallel TRSM computation, offering better theoretical scalability and reduced synchronization costs. The fine-grained analysis and parameter tuning recommendations provide a robust and adaptable solution for various input configurations and processor architectures. This work paves the way for more efficient implementations of numerical linear algebra algorithms on high-performance computing platforms. Future research could focus on extending this approach to distributed memory systems and exploring its applicability to other linear algebra operations.
Conclusion
This paper presents a communication-avoiding parallel algorithm for solving triangular systems for multiple right-hand sides. The algorithm achieves better theoretical scalability than existing alternatives by a factor of up to (kn)1/6p2/3. The selective triangular matrix inversion reduces bandwidth cost and the cost analysis allows recommendations for asymptotically optimal tuning parameters. The pseudo-code facilitates a more efficient parallel TRSM implementation.