- The paper proposes a fine-grained acceleration control method using TRPO to effectively manage autonomous intersection traffic.
- Methodology employs localized control zones and deep RL to optimize real-time vehicular decisions while ensuring collision avoidance.
- Evaluation shows reduced travel times and computational efficiency compared to conventional optimization techniques like MINLP and MIQP.
Autonomous Intersection Management using Deep Reinforcement Learning
Introduction
The paper "Fine-grained acceleration control for autonomous intersection management using deep reinforcement learning" (1705.10432) presents a novel approach to enhancing autonomous intersection management using Trust Region Policy Optimization (TRPO), a state-of-the-art Reinforcement Learning (RL) method. The authors address the limitations of existing methods by focusing on fine-grained acceleration control, aiming to minimize travel time and avoid collisions. Unlike traditional approaches that rely on high-level control, this paper proposes a localized control scheme that leverages deep learning capabilities to automatically adapt to intricate interactions between autonomous vehicles.
Problem Statement and Methodology
Autonomous intersection management (AIM) entails controlling vehicles' movements at intersections. Traditional methodologies often delegate the navigation task entirely to individual vehicles, reserving intersection slots, which is insufficient for local roads managed by stop signs. The proposed approach defines the AIM problem as encompassing both route planning and real-time acceleration control.
The AIM framework introduces zones, where each zone's agent collects real-time vehicular data and issues acceleration commands to optimize travel and prevent collisions. The realization of a cellular scheme facilitates the scalability and efficiency of the AIM system by maintaining spatial independence across zones. The formulation necessitates comprehensive data for motion planning and benefits from RL's model-free learning, which circumvents the complexity of explicit modeling.
The resolution of AIM using TRPO involves defining states as positions and speeds, actions as acceleration commands, and rewards as functions penalizing deviation from destinations. Collision avoidance is integrated into the environment, allowing RL to refine policies that sidestep such events through implicit learning cues rather than explicit penalization.
Reinforcement Learning Approach
The predominant RL framework in this paper relies on deep RL methods, transcending conventional RL's limitations in scalability and feature engineering. TRPO facilitates this through its robust policy optimization capabilities within large-scale, non-convex environments. Harnessing neural networks for policy approximation, TRPO adapts actions derived from stochastic distributions, ensuring smooth navigational decisions for autonomous vehicles.
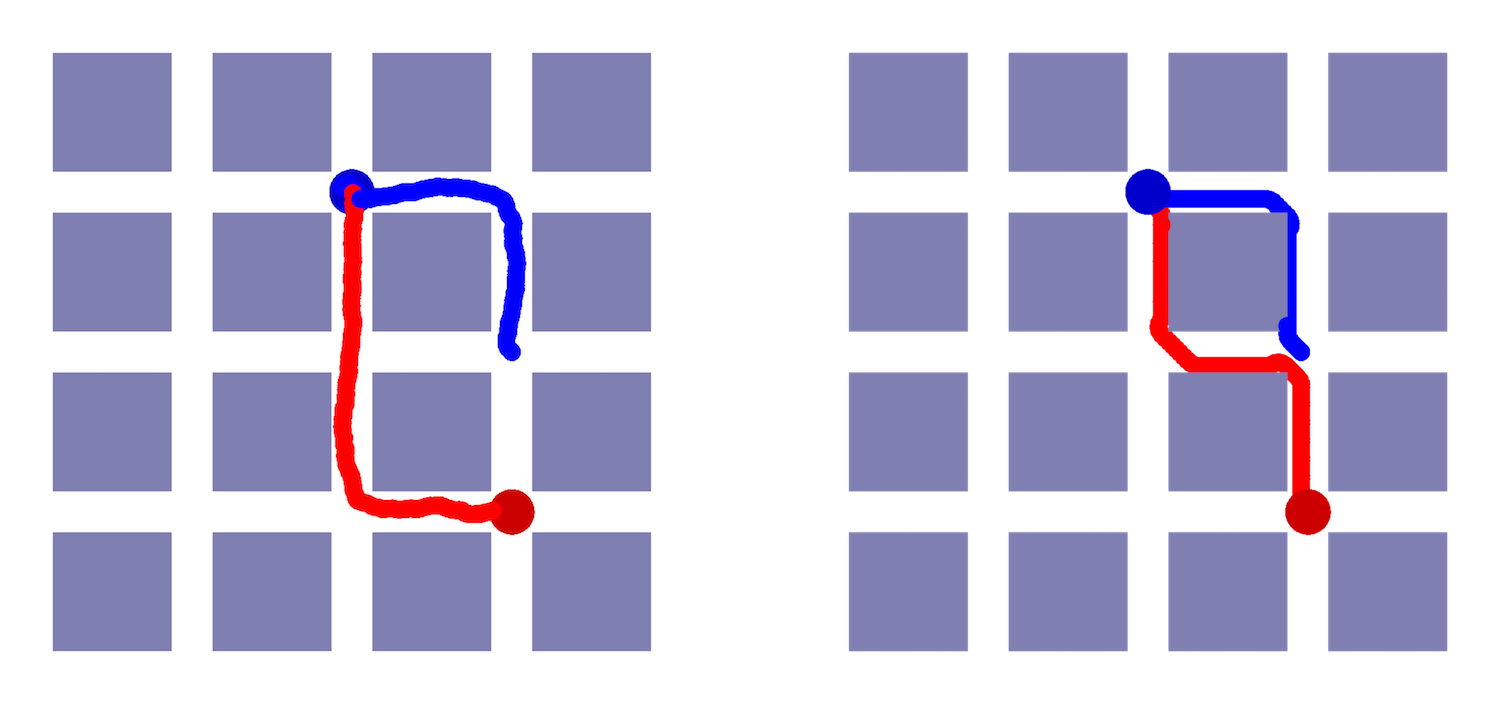
Figure 1: Learnt policy by (left)RL agent and (right)the baseline method for the small example.
Evaluation and Results
The paper evaluates the proposed method against conventional optimization techniques, notably Mixed-Integer Nonlinear Programming (MINLP) and Mixed-integer Quadratic Programming (MIQP), revealing significant reductions in computational complexity and enhanced performance metrics. Notably, real-world configurations defy traditional solutions, making RL-based approaches indispensable.
Simulation results demonstrate that RL competently manages larger grid settings deemed infeasible for conventional optimization. The RL agent achieved a travel time of 11.2 seconds in large examples, which starkly contrasts with traditional methods that failed to deliver solutions within practical bounds.
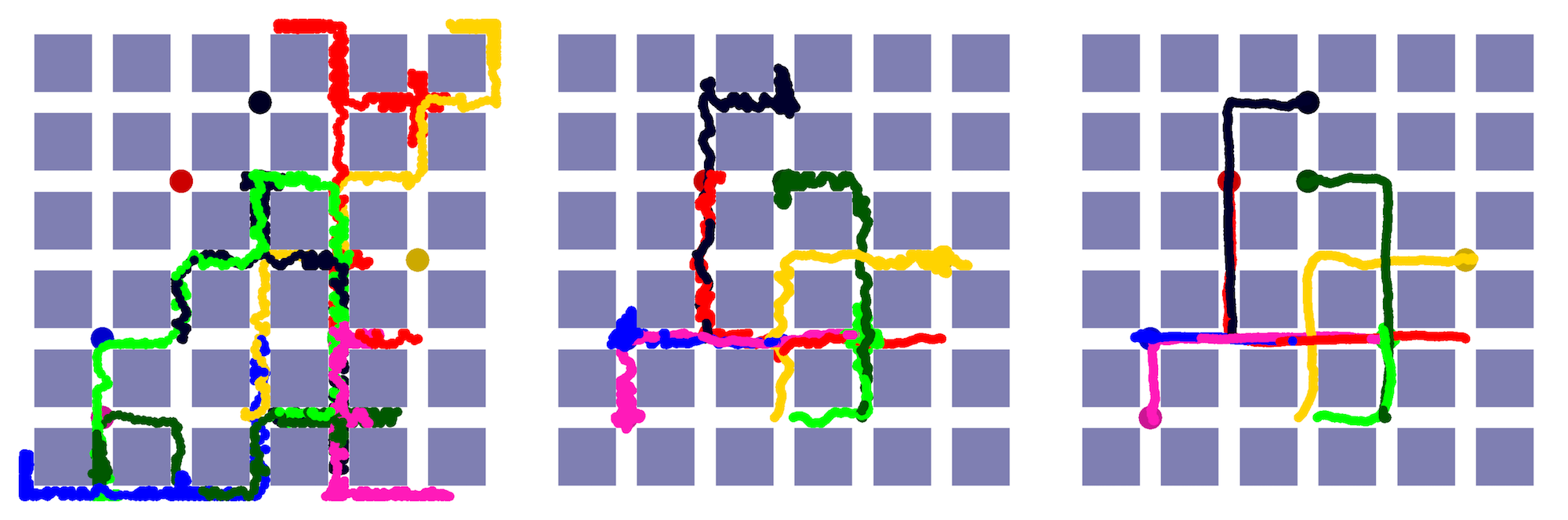
Figure 2: Learnt policy by the AIM agent at different iterations of the training. left: begging of the training, middle: just after the fast learning phase in Fig. \ref{fig:return.
Conclusion
This paper exemplifies the potential of Deep RL in transforming autonomous intersection management for local road contexts, emphasizing fine-grained control and adaptive motion planning. It showcases the computational efficiency of RL over traditional optimization paradigms while setting a foundation for future investigations into pre-training strategies for reducing learning latency in dynamic environments. While existing solutions exhibit practical limitations, RL represents a promising pathway towards scalable, intelligent intersection management systems. The implications extend to real-world applications where safety-critical autonomous systems can seamlessly integrate with urban infrastructure, offering responsive and optimized traffic management. Future directions may explore incorporating environmental factors like fuel consumption and broader traffic system interactions to further refine the AIM approach.