- The paper demonstrates that adding similar flankers significantly reduces recognition accuracy due to pooling integration effects.
- It compares classical DCNNs with eccentricity-dependent models, highlighting improved robustness in architectures mimicking primate vision.
- The study indicates that perception-inspired architectural designs can overcome the limitations of clutter training for robust object recognition.
Do Deep Neural Networks Suffer from Crowding?
This essay discusses the research findings on the effects of crowding in Deep Neural Networks (DNNs) as seen in the paper titled "Do Deep Neural Networks Suffer from Crowding?" (1706.08616). The investigation includes both standard Deep Convolutional Neural Networks (DCNNs) and eccentricity-dependent models to analyze crowding effects in artificial systems, paralleling phenomena observed in human visual perception.
Introduction to Crowding in DNNs
Crowding is a phenomenon where an object recognizable in isolation becomes indistinguishable when adjacent to similar objects. This paper explores whether DNNs trained for object recognition suffer from crowding, analogous to the human visual effect. The study incorporates clutter into images to assess how it affects the recognition capabilities of DNNs.
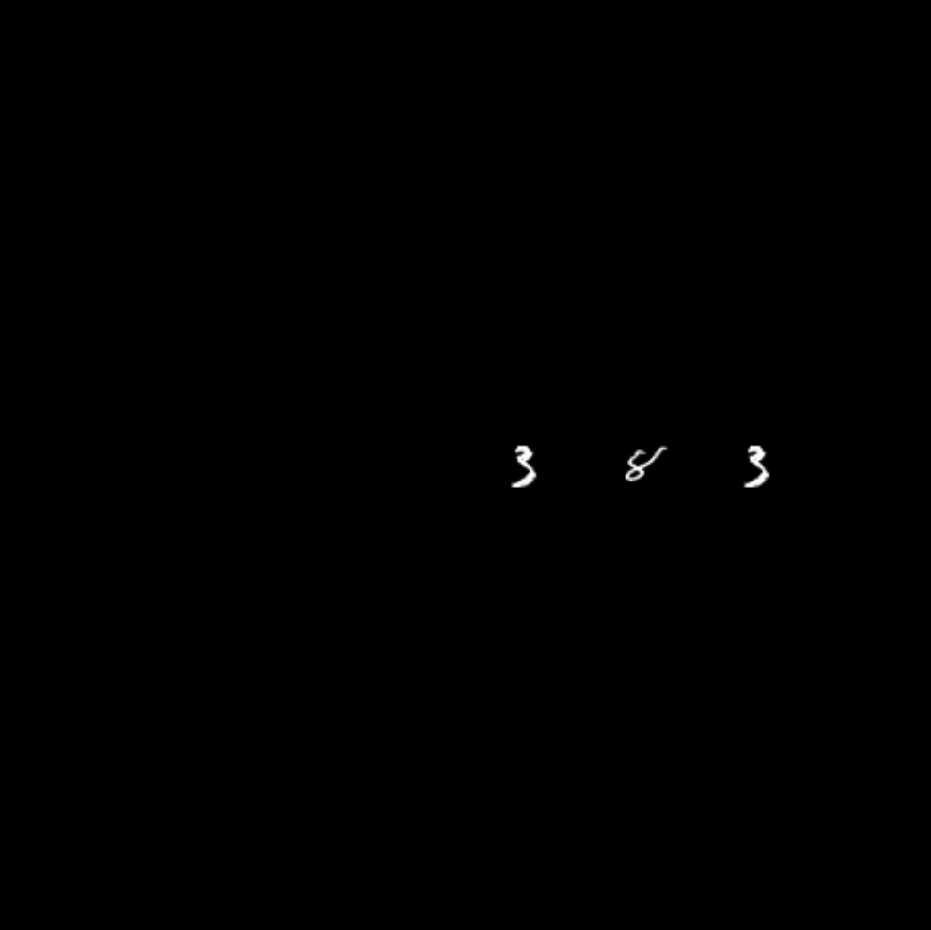
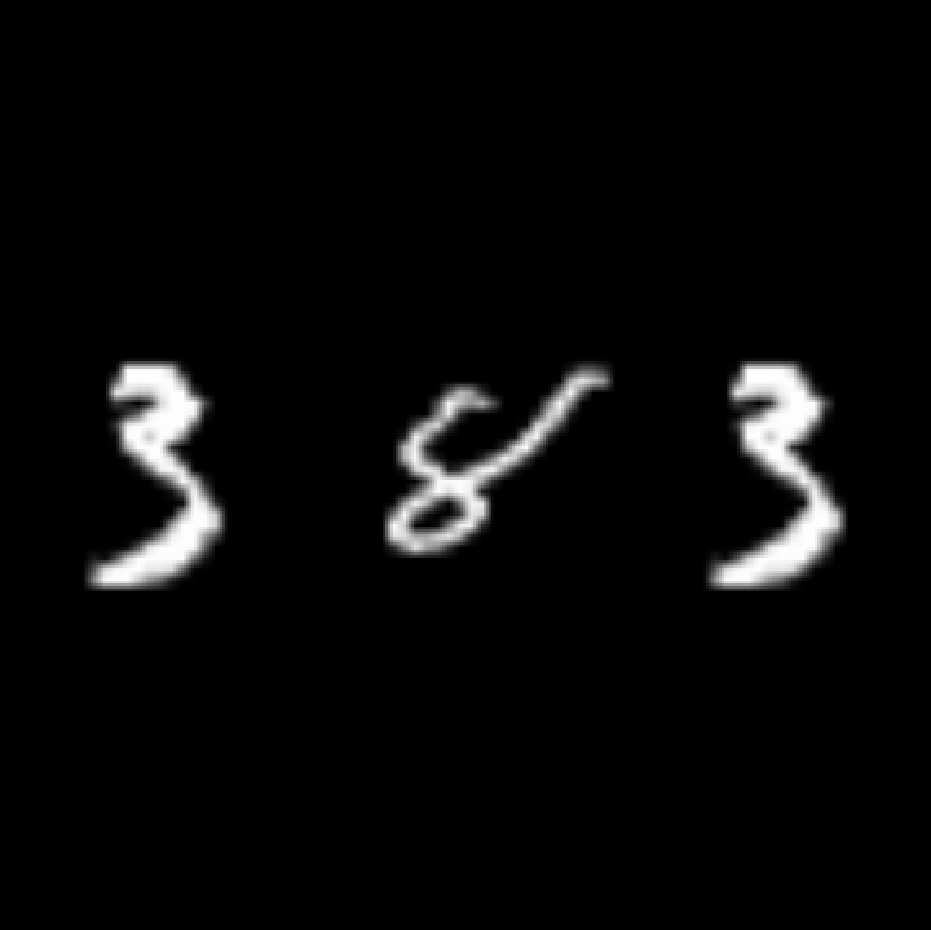



Figure 1: Example image used to test the models, with even MNIST as target and two odd MNIST flankers.
The eccentricity-dependent model introduced in this paper mimics the primate visual cortex by incorporating multi-scale levels where convolution filter sizes increase with eccentricity from the center of fixation. This model aims to achieve object recognition robustness in cluttered environments.
Models Under Experimentation
Classical DCNNs
The study examines DCNN architectures with varying pooling strategies across spatial domains. Three pooling configurations are analyzed: no total pooling, progressive pooling, and at end pooling. These configurations differ in how rapidly they decrease feature maps across layers.
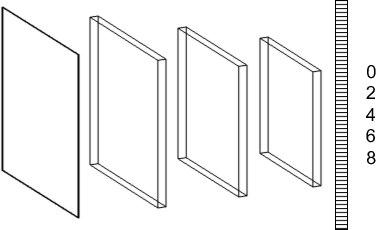
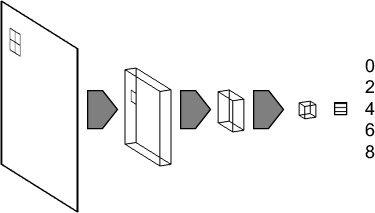
Figure 2: DCNN architectures with three convolutional layers and one fully connected layer, investigating the role of pooling in crowding.
Eccentricity-Dependent Models
Inspired by biological systems, these models increase in scale and are defined by an inverted pyramid-shaped sampling hierarchy where receptive field sizes grow with eccentricity. This structure aims for scale and translation invariance in object representation.
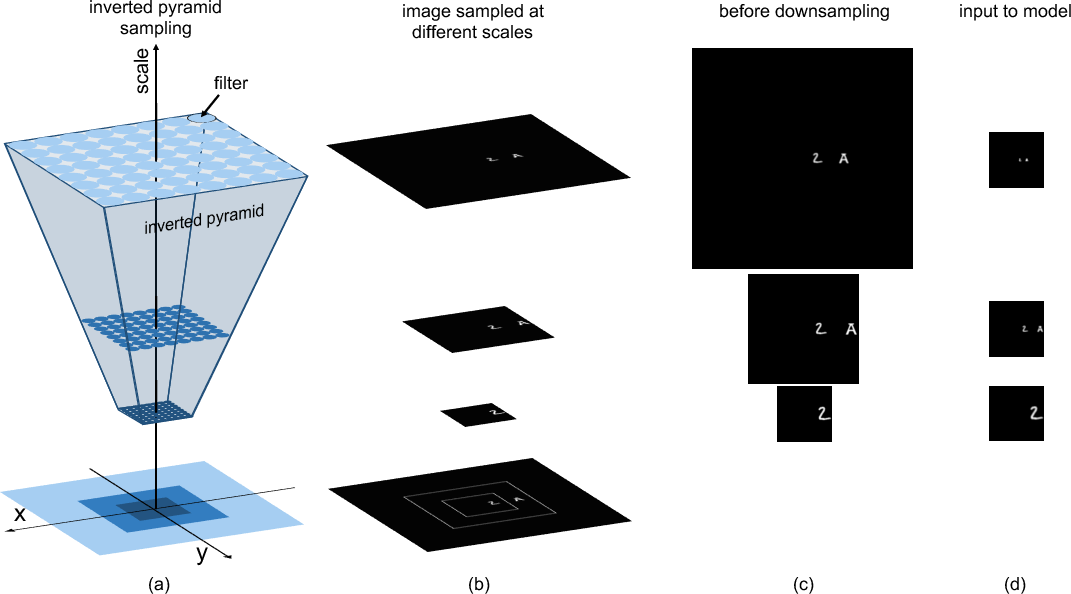
Figure 3: Eccentricity-dependent model inverted pyramid with sampling points, each representing a different receptive field size.
Experimental Setup and Results
Training with Isolated Targets
The models were first trained with isolated target objects. Testing involved introducing varying numbers and configurations of flankers to observe recognition accuracy. The results demonstrated that as flankers were added, especially when similar to target objects, recognition diminished significantly due to pooling integration effects.
Impact of Pooling and Flanker Configurations
The study highlights that configurations such as at end pooling in eccentricity-dependent models offered significant robustness to clutter. Models with pooling configurations that allowed early integration of multiple scales showed reduced performance against flankers. Incorporation of training data including cluttered environments failed to generalize, justifying the need for robust architecture designs rather than exhaustive training datasets.
Practical and Theoretical Implications
The research concludes that while training with clutter does not inherently improve robustness, architectural insights from human perception, such as eccentricity dependency, can lead to more resilient models. The findings suggest advantages in coupling an eccentricity-dependent model with a system for dynamic fixation (eye-like movements) to improve practical applications in variable clutter conditions.
Conclusion
The exploration of crowding effects in DNNs reveals significant insights related to model architecture and perception-inspired designs. This study emphasizes architectural enhancements as a preferable means over extensive clutter data-training. Future research may focus on integrating fixation mechanisms for improved recognition in complex real-world environments.