- The paper introduces a sparse convolution operator that normalizes using a spatial validity mask to effectively handle irregular, sparse inputs.
- It demonstrates improved performance in depth upsampling with faster convergence and strong cross-dataset generalization compared to dense baselines.
- The method proves practical for robotics and sensor fusion by operating robustly under dynamically changing sparsity without reliance on dense guidance.
Introduction and Motivation
The paper "Sparsity Invariant CNNs" (1708.06500) addresses the problem of processing sparse and irregular input data with CNNs, focusing primarily on the task of depth map completion using projected 3D LiDAR scans. Traditional CNN architectures exhibit severe performance degradation when confronted with highly sparse inputs, even when equipped with a validity mask channel. This shortfall stems from the inefficiency of conventional convolutions, which are agnostic to input sparsity patterns and thus require the network to learn invariance to a combinatorial explosion of missing-data scenarios. The motivation, therefore, is to construct a convolutional operator and network architecture explicitly leveraging input sparsity for improved robustness and generalization.
Sparse Convolutional Layer: Methodology
The proposed sparse convolution operation modifies the standard discrete convolution by incorporating a spatial validity mask at each receptive field location. Each filter operates only on observed pixels, and the result is normalized by the count of valid elements (plus a small ϵ to avoid division by zero):
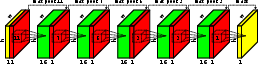

Figure 1: The proposed network architecture features input channels for sparse depth and a validity mask, with sparse convolution layers of decreasing kernel size; on the right, the logic of the sparse convolution operation is depicted.
For an input patch xu,v and corresponding binary mask ou,v, the output at each location (u,v) is:
fu,v=∑i,jou+i,v+j+ϵ∑i,jou+i,v+jxu+i,v+jwi,j+b
Successive network layers receive both the feature outputs and the updated validity mask, propagated via a max-pooling operation over the binarized mask. Skip connections and merge operations are also implemented in a mask-normalized manner, ensuring visibility-aware fusion throughout the network.
Large-Scale Dataset for Sparse Depth Completion
The authors introduce a large-scale dataset derived from raw and accumulated KITTI LiDAR scans. The dataset comprises 93k frames of real urban scenes, with high-density, semi-automatically cleaned ground truth depth maps. Outlier removal leverages consistency checks between accumulated LiDAR and stereo-based (SGM) reconstructions. This new resource enables training deep high-capacity models for depth upsampling and forms a significant contribution for benchmarks in sparse data regimes.
Empirical Evaluation
Sparsity Invariance and Cross-Dataset Generalization
The sparse convolutional architecture demonstrably surpasses standard CNNs—both with and without validity mask concatenation—across all levels of input sparsity. When networks are trained and evaluated at mismatched sparsity levels, dense and mask-augmented baselines degrade catastrophically, while the proposed sparse convolutions maintain consistent performance.
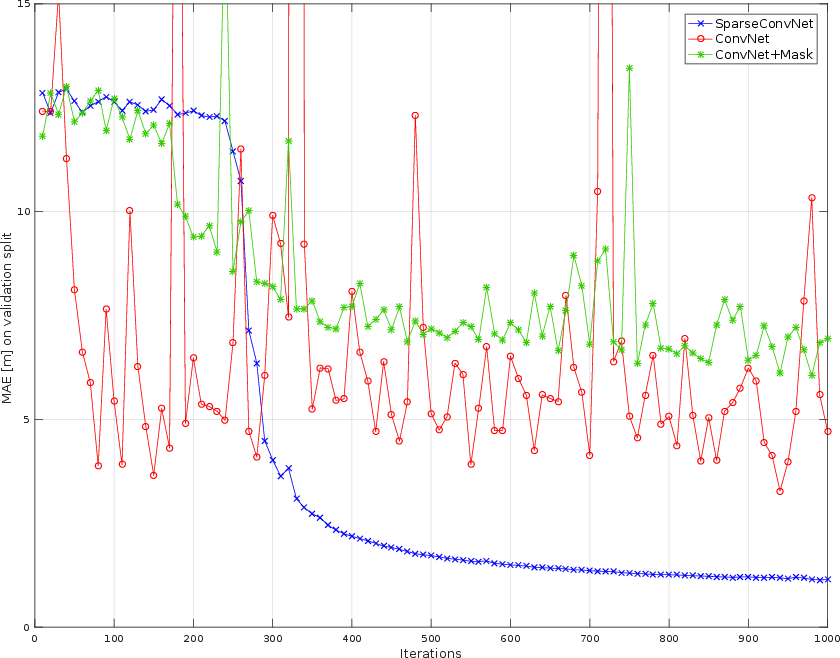
Figure 2: Training convergence curves on sparse Synthia data show the proposed sparse convolutions converge faster and more stably than dense and mask-augmented baselines.
The architecture’s sparsity invariance enables robust cross-dataset generalization. When trained on synthetic (Synthia) scenes at a given sparsity and tested on real KITTI data of a different sparsity, sparse convolutions yield MAE in the range of 0.72–0.73 m, while the best dense baseline errors are an order of magnitude larger.
Comparison to Guided and Unguided Upsampling
The method achieves competitive results on KITTI compared to state-of-the-art guided upsampling techniques that utilize dense RGB images—even outperforming several, despite only using sparse depth as input. This establishes the efficacy of the sparse convolutional mechanism and its ability to eschew reliance on auxiliary guidance in practical robotics where RGB modalities may be unreliable.
Semantic Labeling from Sparse Depth
By replacing convolutions in VGG16 with sparse convolutions, the architecture yields a mean IoU of 31% on Synthia Cityscapes using only 5% sparse depth, compared to 6–7% for dense baselines. The mask-based handling of missing spatial support is crucial for propagating semantic evidence through the network.
Convergence Properties
Sparse convolutions significantly accelerate convergence in training relative to their dense counterparts, particularly in regimes of high input sparsity, attributed to the explicit exclusion of invalid regions from the updates.
Theoretical and Practical Implications
From a theoretical standpoint, the paper demonstrates that incorporating spatial sparsity into the convolution operator itself is necessary for learning robust representations in highly incomplete observation regimes. The invariance properties are not a mere artifact of data augmentation or mask-channel concatenation, but a result of algorithmically enforcing support-aware feature extraction.
Practically, these results suggest that models employing sparse convolutions are better suited for scenarios with dynamically varying input sparsity, prevalent in multi-sensor fusion (heterogeneous LiDAR sensors, event cameras, depth cameras) and in-the-wild robotics applications. The method is directly extensible to 3D CNNs and can facilitate robust perception pipelines without retraining when hardware or environmental constraints reduce information density.
Future Developments
The authors suggest potential synergies between their support-aware convolutions and structured neural network compression techniques, leading to efficient and robust models, especially in very large-scale 3D domains. Further extensions to handle sparsity within the network and input-driven adaptive computation are natural future directions.
Conclusion
Sparsity Invariant CNNs systematically overcome the deficiencies of standard convolutional architectures in processing sparse visual data by embedding explicit validity-aware mechanisms directly into the convolutional process. This yields robust, sparsity-agnostic models with state-of-the-art performance on challenging depth upsampling and semantic tasks, without the need for dense guidance. The large-scale annotated KITTI-derived dataset enhances the empirical foundation and will likely serve as a benchmark for further research in sparse vision, sensor fusion, and network architecture design.