- The paper presents a two-player zero-sum game framework between a Learner and an Auditor to enforce subgroup fairness in classifiers.
- The research develops FTPL and Fictitious Play algorithms that demonstrate theoretical convergence and practical efficiency in mitigating fairness gerrymandering.
- Empirical evaluations on the Communities and Crime dataset show that randomized classifiers can balance error and subgroup unfairness effectively.
Preventing Fairness Gerrymandering: Auditing and Learning for Subgroup Fairness
The paper "Preventing Fairness Gerrymandering: Auditing and Learning for Subgroup Fairness" (1711.05144) addresses potential shortcomings in common fairness definitions used in machine learning, such as statistical parity and equal opportunity constraints. It introduces new perspectives on subgroup fairness and offers rigorous exploration of solutions through auditing and learning, thereby addressing the problem of fairness gerrymandering in classifiers—a situation where apparent fairness on individual groups masks violations within structured subgroups.
Statistical and Individual Fairness
Statistical fairness notions usually enforce approximate parity of a chosen statistic (false positives/negatives, positive classification rate) across pre-defined demographic groups (e.g., race or gender-specific groups). While these definitions are useful because they do not assume characteristics about the population distribution, they are susceptible to fairness gerrymandering. This is when classifiers appear fair on major protected groups but violate fairness on certain combinations of protected attribute values, as illustrated by the given example where a classifier appears to satisfy parity for individual protected attributes but discriminates based on a combination of attributes (Figure 1).
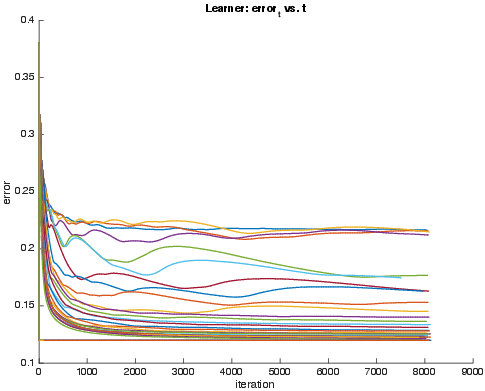
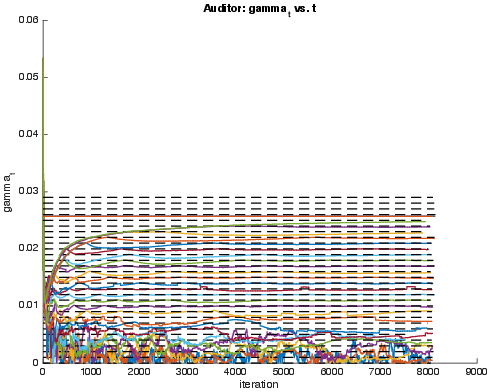
Figure 1: Evolution of the error and unfairness of Learner's classifier across iterations, for varying choices of gamma. (a) Error t of Learner's model vs iteration t. (b) Unfairness gamma_t of subgroup found by Auditor vs. iteration t, as measured by Definition~\ref{fp-fair}.
Subgroup Fairness Challenge
This paper proposes associating fairness constraints with exponentially many structured subgroups defined by a class of functions instead of solely pre-defined demographic groups (e.g., based on race or gender). The work introduces a two-player zero-sum game framework between a Learner and an Auditor to find optimal subgroup-fair classifiers for large classes of decision rules, with the aim of enforcing fairness for a broader range of subgroups.
The computational problem of auditing a classifier for subgroup fairness is proven equivalent to weak agnostic learning for the family of group indicator functions, indicating worst-case computational hardness for simple natural classes such as boolean conjunctions and linear threshold functions. However, the reduction implies that practical heuristics employed in efficient machine learning can be used to solve the problem in practice, which presents opportunities for implementing approximate fair classifiers that are effective in real datasets.
Algorithm Development
The paper develops two algorithms for achieving subgroup fairness:
- Follow the Perturbed Leader (FTPL):
- Uses a strategy where a Learner plays the no-regret FTPL algorithm.
- The Auditor plays best response against the mixed strategy of the Learner.
- Theoretical guarantees are staged for convergence within a polynomial number of iterations, assuming the existence of CSC oracles.
- Fictitious Play Algorithm:
- Solves Fair ERM problem using iterative best responses by Learner and Auditor where each player best-responds to the empirical distribution of play over previous rounds.
- More practical due to simplicity and faster convergence in practice.
Empirical Evaluation
The practical application of these algorithms is demonstrated using the Communities and Crime dataset (Figure 2).
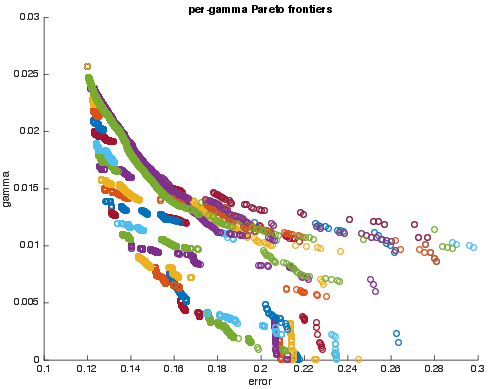
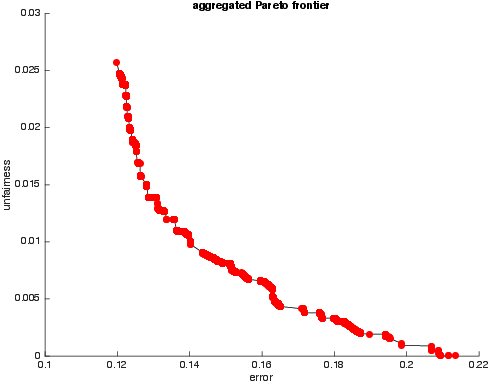
Figure 2: (a) Pareto-optimal error-unfairness values, color-coded by varying values of the input parameter gamma. (b) Aggregate Pareto frontier across all values of gamma. The gamma values cover a dense range for smoothing.
Empirical evaluation using Fictitious Play indicated effective computational performance on real datasets. The results suggested a convergence to a collection of randomized classifiers achieving a Pareto frontier of error-unfairness trade-offs (Figure 2). The paper postulates frequent occurrences in datasets of classifiers that pass one-dimensional statistical fairness tests while failing against richer multi-dimensional subgroup tests.
Figure 2: (a) Pareto-optimal error-unfairness values, color-coded by varying values of the input parameter gamma. (b) Aggregate Pareto frontier across all values of gamma. Here the gamma values cover the same range but are sampled more densely to get a smoother frontier. See text for details.
Conclusion
The study outlines a rigorous methodology to confront fairness gerrymandering in machine learning algorithms. By presenting subgroup fairness as a two-player zero-sum game between a Learner and an Auditor, the research not only highlights theoretical and computational challenges but also suggests pragmatic methods for achieving subgroup fairness. The effectiveness of these methods in real datasets promises significant applicability in various domains, pushing toward more equitable machine learning applications.