- The paper introduces a Multi-Scale Frame-Synthesis Network that unifies interpolation and extrapolation via a novel transitive consistency loss.
- It leverages parameter sharing across pyramid levels to reduce computational cost while scaling dynamically for various temporal synthesis tasks.
- Experimental results show that the network achieves competitive performance with fewer parameters compared to traditional optical flow–based methods.
Multi-Scale Video Frame-Synthesis Network with Transitive Consistency Loss
Introduction
The paper "Multi-Scale Video Frame-Synthesis Network with Transitive Consistency Loss" addresses the problem of video frame synthesis, encompassing interpolation and extrapolation, through a unified neural network framework. The proposed approach seeks to overcome the limitations of traditional methods that rely heavily on optical flow estimation, which can introduce artifacts if the flow estimation is inaccurate. Recent approaches have leveraged autoencoders and direct convolution methods, but they often specialize in specific frame synthesis settings and require sizeable computational resources, limiting their real-world applicability, particularly on constrained mobile devices.
Network Architecture
The core of the proposed method is the Multi-Scale Frame-Synthesis Network (MSFSN), which is capable of reconstructing frames at specified temporal positions dynamically, whether the need is for interpolation or extrapolation. The architecture is illustrated as a sequence of interconnected sub-networks arranged in a multi-scale structure (Figure 1). Each level within this multi-scale representation functions independently as a sub-network comprised of residual blocks. Importantly, parameter sharing across pyramid levels is implemented to reduce the model size significantly while maintaining flexibility in handling various temporal tasks. This design allows the model to be both compact and scalable, catering to higher capacities by simply increasing pyramid levels as needed.
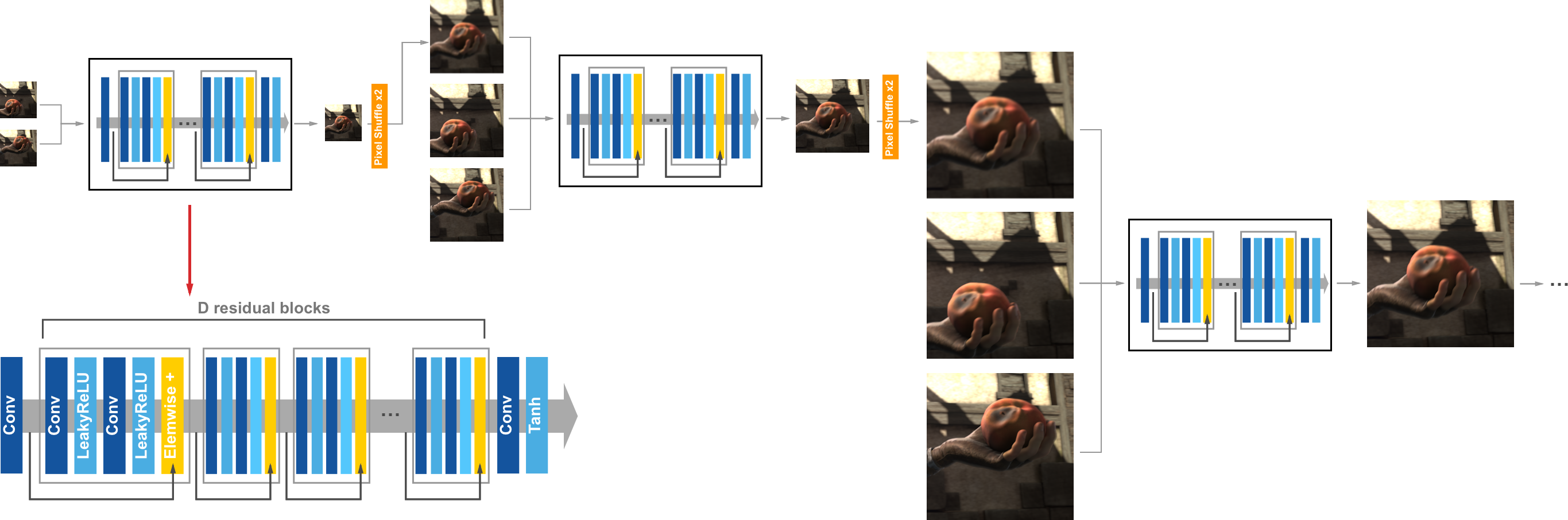
Figure 1: Example of our multi-scale network. Each level is a sub-network consisting of D residual blocks.
Loss Functions
To train the network effectively, a composite loss function is devised. It includes pixel reconstruction, feature reconstruction, adversarial, and transitive consistency losses. The transitive consistency loss is particularly novel in this context, as it enforces the logical consistency of predictions by requiring that the generated frames maintain temporal coherence in both forward and backward directions within a video sequence (Figure 2). This loss stabilizes the training process and improves the generalization of the model across diverse synthesis scenarios.
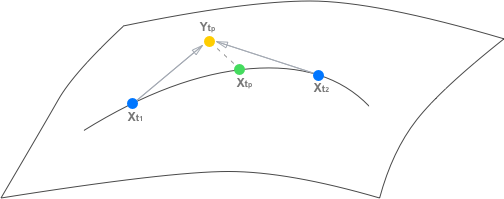
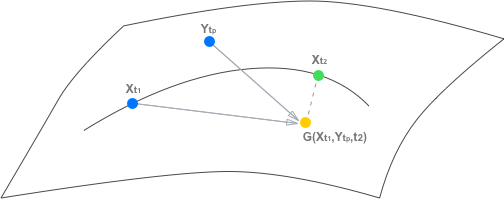
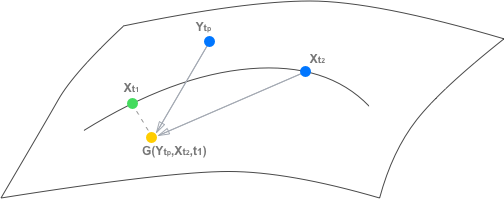
Figure 2: Example of transitive property. We aim to learn the frame synthesis mapping G:S×S×T→S.
Model Analysis
The paper provides a comprehensive analysis of the model's performance with respect to various configurations of pyramid depth and network depth. As discussed, deeper networks perform better but at the expense of computational efficiency. It was observed that the transitive consistency loss significantly enhances convergence and results in less oscillation during training. Extensive experiments demonstrate that greater pyramid depth generally leads to better handling of large motion tasks, thanks to improved downsampled image processing.
Experimental Results
The proposed MSFSN was rigorously evaluated on benchmark datasets such as UCF-101 and THUMOS-15. The approach was compared against leading methods, including optical flow-based methods like EpicFlow and FlowNet2, as well as frame synthesis methods DVF and AdapSC. Quantitatively, the proposed network achieves competitive performance with significantly fewer parameters, indicating both high efficiency and effectiveness.
For interpolation tasks, MSFSN demonstrates superior capabilities in rendering sharp results and maintaining structural integrity across interpolated frames (Figure 3). In extrapolation tasks, the network effectively extends sequences while preserving motion consistency without needing retraining. These capabilities are further validated through user studies, where MSFSN outputs were consistently favored over alternative methods, highlighting the model's practical robustness and adaptability.






Figure 3: Example of frame interpolation on UCF-101 dataset.
Discussion and Conclusion
The paper acknowledges some limitations, such as a tendency toward generating blurrier images compared to methods heavily reliant on correspondence estimation. Future work could further integrate correspondence-based advantages into the unified framework to leverage both strategies effectively. Furthermore, expanding the understanding of motion variation within the network's predictive capacity remains a compelling research avenue.
In conclusion, the Multi-Scale Video Frame-Synthesis Network proposes a compact, flexible, and scalable solution that excels in various video frame synthesis tasks across multiple datasets. This contributes toward advancing video processing technology, making it feasible for more portable and practical applications where computational resources are limited.