- The paper proposes the novel DSC module that integrates a spatial RNN with attention to learn directional context for shadow detection.
- It achieves significant performance improvements, with up to 97% accuracy and a 38% reduction in BER on benchmark datasets.
- The approach utilizes end-to-end training with deep supervision, suggesting potential extensions to other image segmentation tasks.
Direction-aware Spatial Context Features for Shadow Detection
This paper proposes a novel approach to shadow detection based on analyzing image context in a direction-aware manner. The methodology involves a spatial recurrent neural network (RNN) enhanced with an attention mechanism that considers different directional contexts and embeds this into a convolutional neural network (CNN). The approach significantly improves shadow detection accuracy and balance error rate (BER).
Methodology
Architecture
The core innovation of the paper is the Direction-aware Spatial Context (DSC) module integrated into a CNN for shadow detection. The DSC module employs a spatial RNN to aggregate spatial context along four principal directions—left, right, up, and down—with the incorporation of attention weights to balance the contribution from each direction.
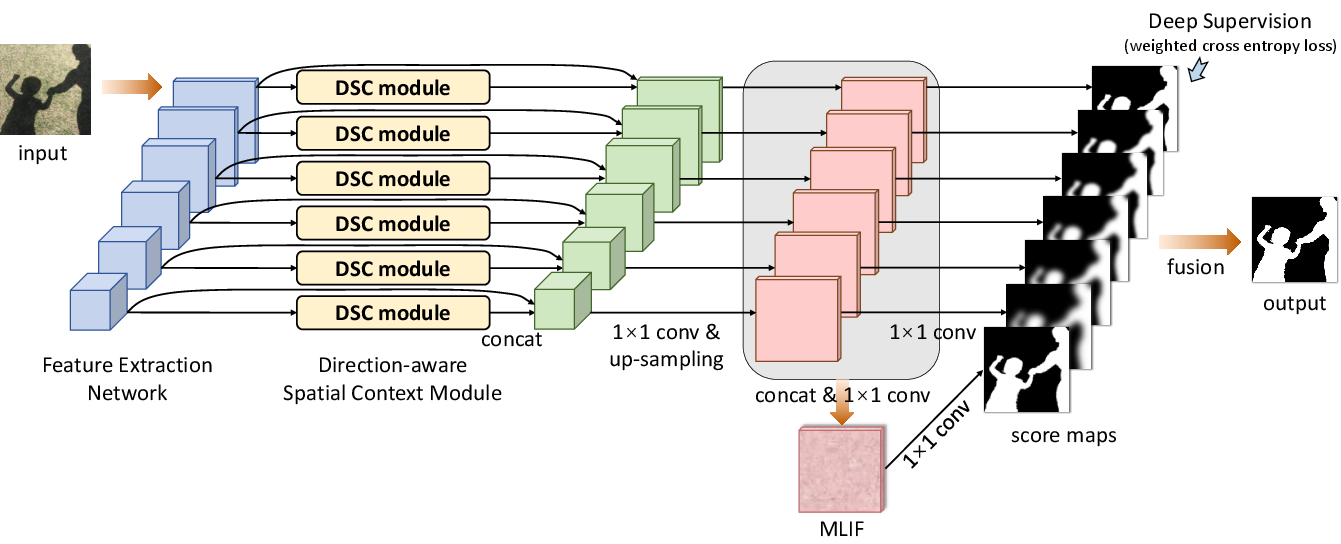
Figure 1: The schematic illustration of the overall shadow detection network.
The network architecture proceeds as follows:
- Feature Extraction: Utilize CNN layers to extract features at multiple scales from the input image.
- DSC Module Integration: Embed a DSC module to learn spatial context with directional variance.
- Feature Concatenation: DSC features are concatenated with convolutional features, upsampled, and fused to create a multi-level integrated feature (MLIF).
- Score Map Prediction: Use deep supervision to predict score maps for each layer, which are fused to generate the final shadow detection map.
The entire system is trained in an end-to-end manner using a weighted cross-entropy loss designed to prioritize both shadow and non-shadow regions effectively.
Direction-aware Spatial Context Module
The DSC module is built upon the spatial RNN concept, but differs by utilizing direction-aware attention. This attention mechanism selectively emphasizes spatial context features learned in different directions.
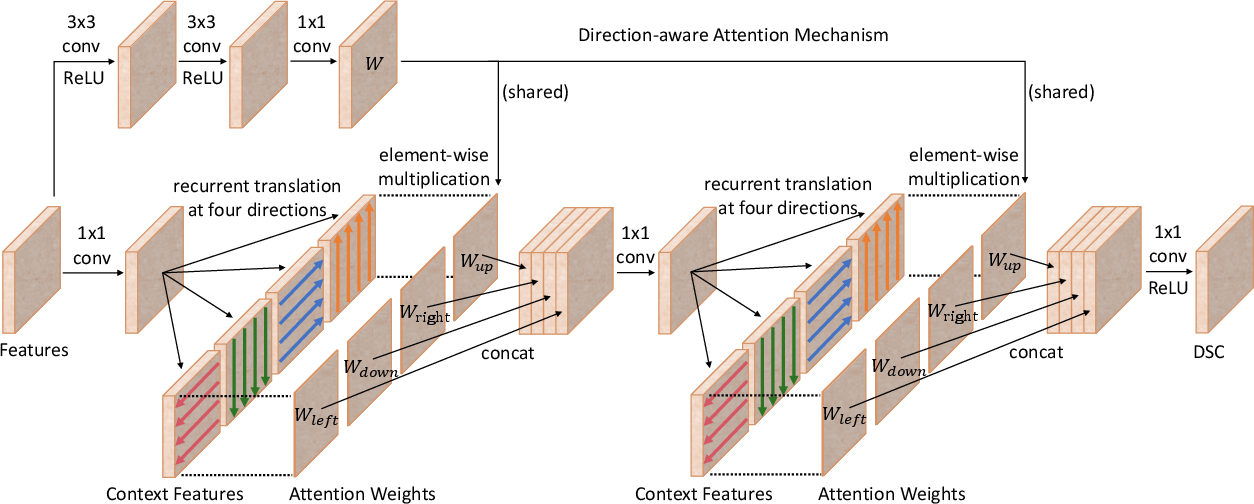
Figure 2: The schematic illustration of the {\em direction-aware spatial context module\/}.
The computation within each DSC module is structured as follows:
- Spatial RNN Aggregation: Propagate spatial context features twice to gather comprehensive directional information.
- Attention Mechanism: Assign learnable attention weights to each direction's aggregated spatial context.
- Feature Concatenation and Translation: Apply 1×1 convolutions for dimensionality reduction and further data translation.
Experimental Results
The proposed network was evaluated against state-of-the-art methods using two benchmark datasets, SBU Shadow Dataset and UCF Shadow Dataset. The results demonstrate superior accuracy and BER, notably achieving 97% accuracy and a 38% reduction in BER on common shadow detection benchmark datasets.









Figure 3: Visual comparison of shadow maps produced by our method and other methods against ground truths.
Table 1 summarizes the comparison between the proposed DSC approach and other methods in terms of accuracy and balance error rate. The DSC network consistently outperforms others in detecting complex shadow patterns, showing resilience against false positives often caused by black objects misrecognized as shadows.
| Method |
SBU Accuracy |
SBU BER |
UCF Accuracy |
UCF BER |
| DSC (ours) |
0.97 |
5.59 |
0.95 |
8.10 |
| scGAN |
0.90 |
9.10 |
0.87 |
11.50 |
| Stacked-CNN |
0.88 |
11.00 |
0.85 |
13.00 |
| Unary-Pairwise |
0.86 |
25.03 |
- |
- |
Conclusion
The paper introduces a highly effective network for single-image shadow detection that leverages direction-aware spatial context via a novel DSC module. The method enables finer discrimination between shadow and non-shadow regions by understanding and utilizing the directionality of spatial context features. The robust performance across different datasets indicates that this network architecture could be extended to other image segmentation tasks, such as saliency detection and semantic image segmentation. Future work may explore real-time applications and the detection of time-varying shadows in dynamic scenes.