- The paper presents an adaptive caching algorithm that leverages Spark's DAG structure to intelligently optimize intermediate data storage.
- It formulates caching as a submodular optimization problem using greedy approximations to achieve near-optimal performance.
- The strategy demonstrates up to a 70% improvement in cache hit ratios and reduced recomputation time through simulations and real-world tests.
Introduction
The paper addresses the optimization of caching intermediate data in multi-stage, parallel big data frameworks like Apache Spark. The aim is to automate caching decisions to enhance the performance of machine learning applications by minimizing the total recomputation workload of Resilient Distributed Datasets (RDDs) compared to traditional caching mechanisms like LRU and FIFO. The proposed solution, an adaptive caching algorithm, intelligently decides which intermediate datasets to cache by leveraging the execution graph's Directed Acyclic Graph (DAG) structure (Figure 1).
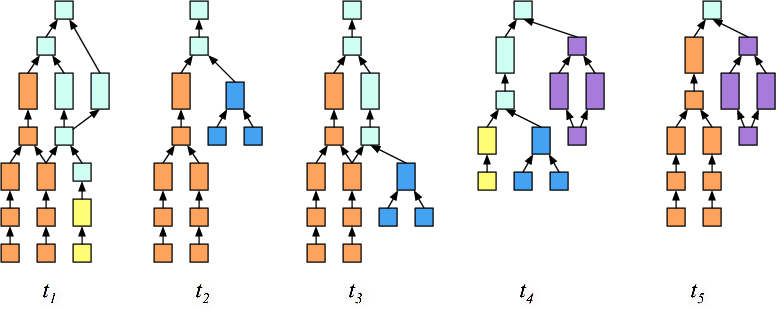
Figure 1: Job arrivals with computational overlaps demonstrated using DAGs in Spark.
Background and Motivation
Apache Spark uses RDDs to enable distributed in-memory caching, which improves the performance of iterative data processing tasks. However, the current caching mechanism relies on simplistic policies like LRU, which do not consider the intricate dependencies between operations represented in DAGs (Figure 2).
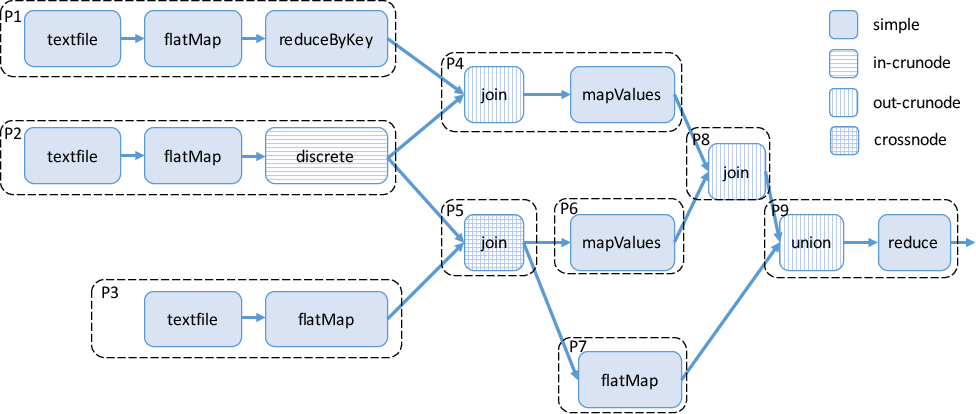
Figure 2: Job DAG example illustrating precedence and parallel execution of operations.
Algorithm Design
The proposed caching strategy utilizes the complete knowledge of Spark’s job DAGs to make informed caching decisions. RDDs are selectively cached based on their recomputation cost, size, and reuse frequency. This approach deviates from traditional cache algorithms that operate without detailed insights into computational dependencies or future access patterns. The key idea is to treat the caching decision as a submodular optimization problem, which can be approximated effectively using greedy algorithms with probabilistic guarantees of performance within a 1−e1 factor of the optimal solution.
Through numerical analysis, simulation, and real-world implementation in Apache Spark, the proposed algorithm demonstrates superiority over conventional methods in improving cache hit ratios and reducing recomputation time (Figure 3). Specifically, the adaptive caching algorithm adapts to varying workload patterns and efficiently leverages available memory space, achieving up to a 70% improvement in cache hit rates under various conditions.
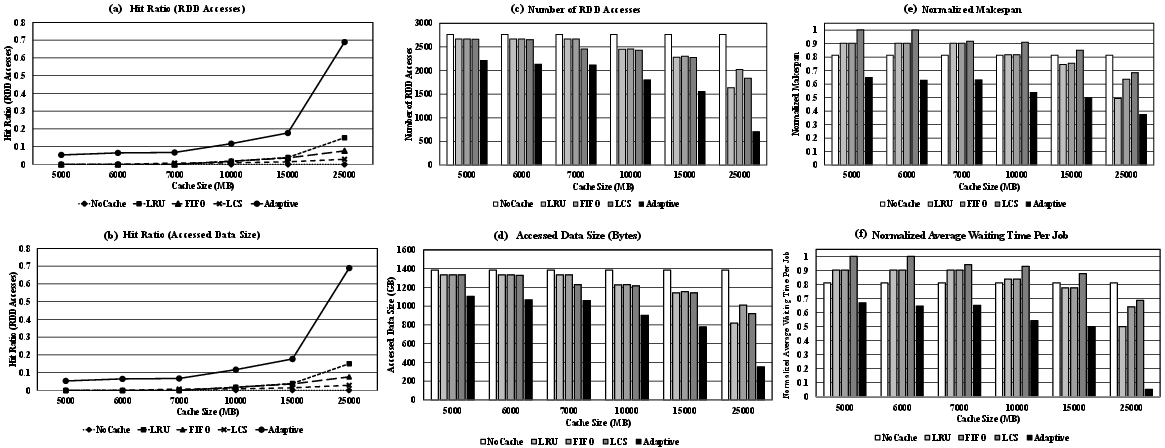
Figure 3: Hit ratio, access number, and total work makespan results of large-scale simulation experiments.
Implementation Considerations
Implementing this caching strategy involves extending Spark’s internal cache management to track the cost implications of caching particular RDDs. This entails modifications to recognize computational overlaps across different jobs and dynamically adjust caching decisions based on real-time execution statistics (Figure 4). The architecture of the Spark Unified Memory Manager is adapted to integrate the proposed RDDCacheManager, which coordinates cache updates across distributed worker nodes in the cluster.
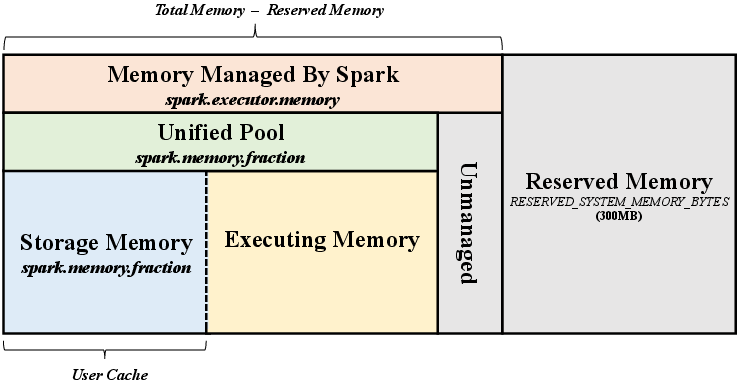
Figure 4: Architecture of Apache Spark Unified Memory Manager with integrated adaptive caching mechanisms.
Conclusion
The adaptive caching algorithm offers a significant advancement in optimizing memory usage in big data frameworks by intelligently managing intermediate data storage. By reducing reliance on suboptimal eviction policies like LRU and instead employing a principled, graph-aware caching strategy, the algorithm enhances the performance of data-parallel applications. Future work may focus on extending these concepts to other big data platforms beyond Spark, incorporating additional computational models and workloads.