- The paper presents the Mixtures of Experts framework where model parameters depend on covariates, enhancing the flexibility of mixture models.
- The paper employs both maximum likelihood estimation via the EM algorithm and Bayesian methods using MCMC, addressing key challenges like model identifiability.
- The paper applies the ME framework to diverse domains—including rank preference, time-series, and network data—demonstrating its practical versatility.
Mixtures of Experts Models (1806.08200)
Mixtures of Experts (ME) models represent a class of statistical models combining mixture models and regression, where both the outcome and model parameters are functions of covariates. ME models offer a flexible analytical framework applicable in various domains, from clustering and regression to handling time-series and network data. This essay discusses the ME framework, its application, its inference methods, and identifies consideration points such as model identifiability.
The Framework
ME models posit that observed data arise from a mixture of sub-models (the "experts"), with parameters that depend on associated covariates. An ME model is specified by allowing model parameters to be functions of covariates, facilitating conditional mixture models. A general ME model can be expressed as:
p(yi∣xi)=g=1∑Gηg(xi)fg(yi∣θg(xi))
Here, ηg(xi) represents the gating network determining the weight of each expert g, and fg(yi∣θg(xi)) represents the expert model itself.

Figure 1: A two-dimensional simulated data set from a G=2 ME model showing two clusters with different covariate influences.
The flexibility of ME models allows them to extend standard mixture models by incorporating covariates, thus providing more contextual insights into model parameters. This versatility is advantageous for performing clustering of data, regression analysis, and modeling time-series and network data, as demonstrated in various illustrative applications.
Statistical Inference
Inference for ME models can be conducted via several methodologies, including maximum likelihood estimation and Bayesian estimation:
Maximum Likelihood Estimation (MLE)
MLE is typically performed using the Expectation-Maximization (EM) algorithm, exploiting the decomposition of observed data into complete data by introducing latent variables. For example, in a Gaussian ME model, the EM algorithm iteratively updates parameter values by alternating between an expectation step (estimating latent variables) and a maximization step (updating parameters). The primary challenge in MLE is often the optimization of component weights, which is typically addressed using numerical methods.
Bayesian Estimation
Bayesian inference with ME models effectively utilizes Markov Chain Monte Carlo (MCMC) methods, such as Gibbs sampling and Metropolis-Hastings algorithms. These methods handle parameter estimation by sampling from posterior distributions, allowing complex dependencies modeled by ME frameworks to be captured. Bayesian estimation can provide more robust inferences in cases where performance is sensitive to parameter initialization.

Figure 2: A mosaic plot representation of component densities for rank preference data, illustrating distributional structure within clusters.
Applications
ME models have been applied successfully across multiple domains:
Rank Preference Data
In the context of election data, ME models can uncover voting patterns by modeling rank preferences with covariates, revealing influential factors such as age or government satisfaction. This helps identify voter blocs and their characteristic preferences.
Time Series and Network Data
ME models can also analyze time series by incorporating covariates into transition probabilities, capturing dynamics orthogonal to explicit covariates. In network analysis, ME models can uncover latent cluster structures influenced by node-specific covariates, offering insights into social processes within networks.
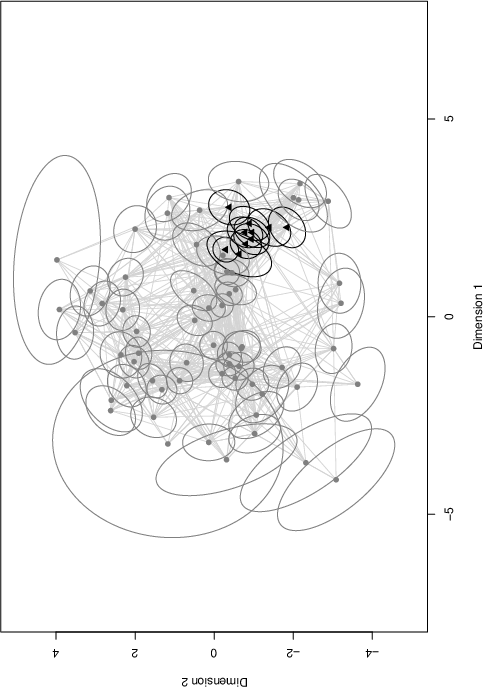
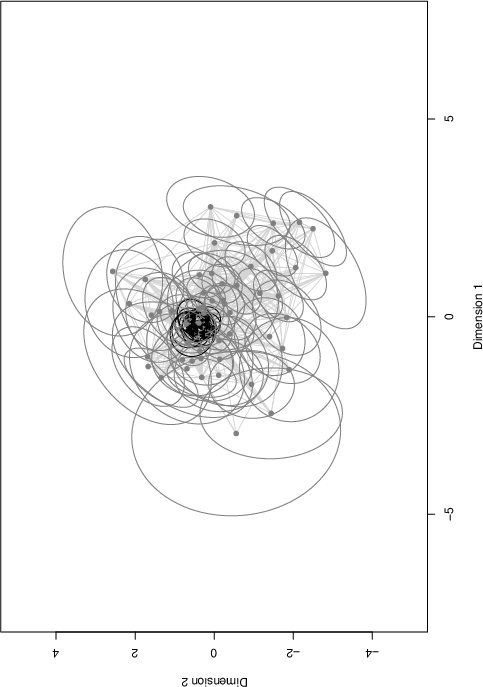

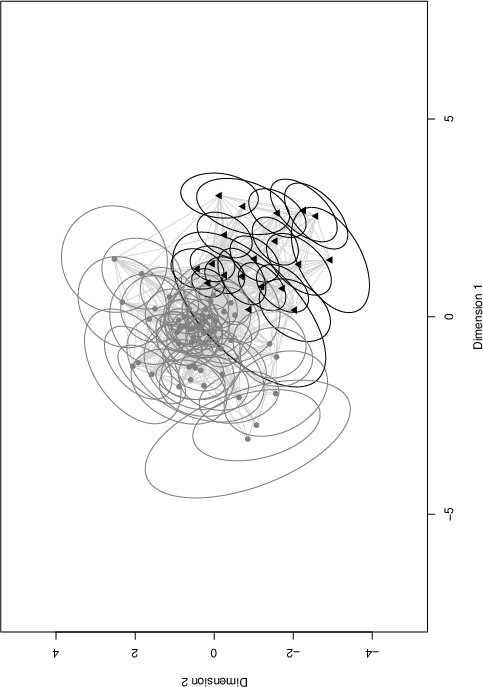
Figure 3: Latent positions and clusters inferred from network data, demonstrating covariate influences on implicit social structures.
Identifiability Considerations
Identifiability in ME models is an essential consideration, impacting model interpretation and inference validity. Identifiable models ensure parameters are recoverable from observed data, providing unique insights. However, as with many mixture models, ME models can suffer from non-identifiability, such as label switching and unidentifiable regression coefficients due to non-unique parameter values in the MNL model.
Identifiability in ME Models
ME models present unique challenges, particularly when covariates introduce high discriminative power between groups, potentially leading to overfitting or non-identifiable parameter settings. It's crucial to design experiments and select covariates ensuring identifiability, drawing lessons from coverage conditions and standard finite mixture identifiability rules.
Conclusion
Mixtures of Experts models provide a comprehensive framework for incorporating covariate-driven parameter dynamics into mixture model analyses. While offering broad applicability and flexibility, users must be aware of the identifiability conditions and appropriate inference techniques to fully leverage the ME framework. Future research in ME models could focus on improving identifiability tests and expanding potential applications in novel domains.