- The paper introduces a novel recurrent self-attention mechanism that iteratively refines sequence representations using dynamic halting.
- The approach achieves state-of-the-art results on language tasks and a 0.9 BLEU improvement in machine translation benchmarks.
- The architecture generalizes on algorithmic tasks by adaptively managing per-token computation and enhancing context-sensitive reasoning.
The "Universal Transformers" paper introduces a novel architecture that enhances the Transformer model with computational universality by integrating recurrence across its layers. This approach addresses both practical shortcomings of fixed-depth models in generalizing on various algorithmic tasks and theoretical limits on expressivity of Transformers by using recurrent, self-attentive mechanisms that iterate over representations of each sequence element.
Recurrent Structure and Self-Attention
Universal Transformers refine vector representations of sequence positions iteratively through self-attention followed by a recurrent transition function applied across all time steps. This iterative refinement (Figure 1) leverages self-attention, ensuring global information exchange between sequence positions in every iteration.
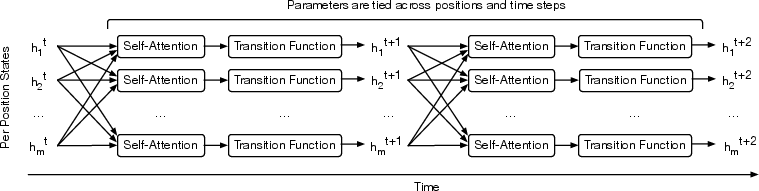
Figure 1: The Universal Transformer repeatedly refines a series of vector representations for each position of the sequence in parallel, by combining information from different positions using self-attention.
Dynamic Halting Mechanism
A dynamic per-position halting mechanism is introduced to regulate computational steps based on input complexity. Dynamic halting, inspired by ACT, allows the model to adaptively decide when sufficient processing is completed for each position, optimizing resource allocation (Figure 2).
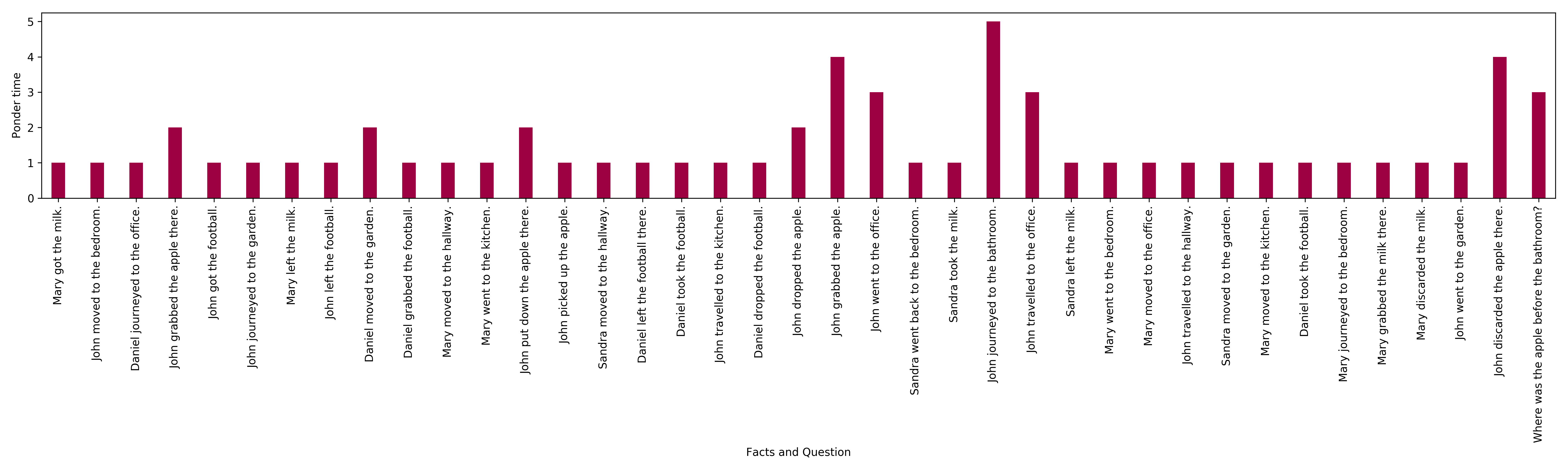
Figure 2: Ponder time of UT with dynamic halting for encoding facts in a story and question in a bAbI task requiring three supporting facts.
Experiments and Results
Algorithmic Tasks
Universal Transformers demonstrate superior generalization on algorithmic tasks such as copying, reversing, and addition over long sequences (Table 4). Their ability to learn iterative transformations allows them to outperform fixed-depth Transformers and LSTMs, showcasing potential for tasks demanding longer context reasoning.
Language Understanding Tasks
On language understanding tasks like bAbI and LAMBADA, Universal Transformers integrate broader contextual reasoning (Figures 5, 3), achieving new state-of-the-art results in complex problems like those requiring multiple supporting facts or broader discourse context. The attention mechanism within recurrent layers helps refine context-sensitive representations iteratively, improving accuracy.
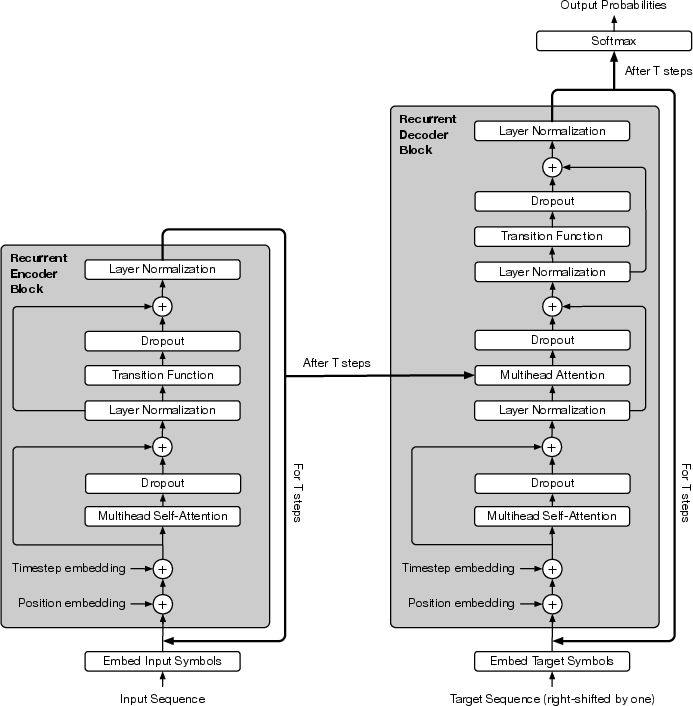
Figure 3: The Universal Transformer with position and step embeddings as well as dropout and layer normalization.
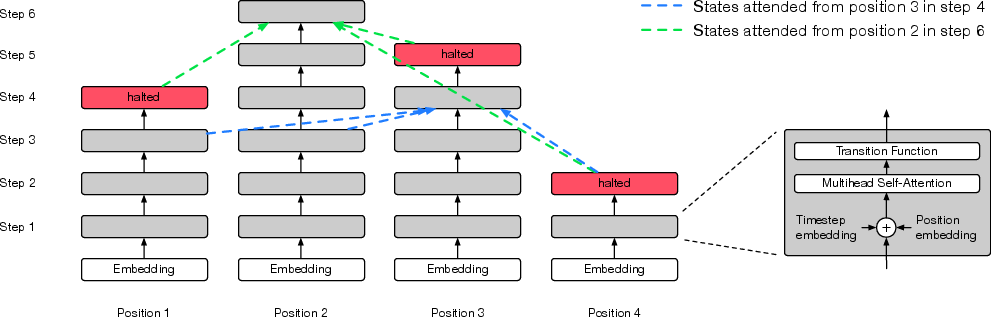
Figure 4: The Adaptive Universal Transformer (best viewed in colour).
Machine Translation
Universal Transformers yield 0.9 BLEU improvement over standard Transformers in the WMT14 En-De dataset, evidencing the practical advantage of their Turing-completeness and adaptive recurrence in capturing linguistic structures more effectively (Table 8).
Theoretical and Practical Implications
Universal Transformers bridge the gap between computationally universal models and practical architectures by integrating depth-wise recurrence and state refinement. They handle sequential processing in parallel, akin to automata, enabling complex function simulation, unlike conventional time-recurrent models, which lack sufficient per-symbol memory access during processing.
These enhancements imply significant improvements in both computational efficiency and capability to generalize across sequence lengths beyond those in training data—a step closer to achieving universal sequence learning models suited for diverse tasks and complexities.
Conclusion
Universal Transformers advance the field by augmenting foundational Transformer capabilities through recurrence and adaptive halting, achieving competitive performance across algorithmic and natural language tasks. Future developments could aim at refining these mechanisms, potentially exploring hybrid architectures that leverage universal sequence processing for more generalized AI solutions in varied real-world applications.