- The paper quantifies gender bias by comparing model outputs on gendered occupation terms, revealing bias amplification during training.
- The adoption of counterfactual data augmentation (CDA) effectively mitigates bias, outperforming traditional word embedding debiasing techniques.
- Experimental results indicate that combining CDA with WED reduces bias optimally while maintaining model accuracy.
Gender Bias in Neural Natural Language Processing
Introduction
The paper "Gender Bias in Neural Natural Language Processing" (1807.11714) investigates the presence of gender bias in neural NLP systems, specifically focusing on tasks such as coreference resolution and language modeling. These tasks are cornerstone applications in NLP that underpin various practical systems including information extraction, text generation, speech recognition, and machine translation. Given their reliance on human language data, it is imperative to understand if these systems inherit historical biases or propagate them further. The research defines methodologies for quantifying and mitigating such biases, offering actionable insights into how these biases manifest during model training and proposing strategies to counteract them effectively.
Gender Bias Quantification
The central methodology proposed for measuring gender bias is a benchmark that assesses the disparity in model outputs based on gendered associations with occupations. This benchmark is based on causal testing, leveraging matched pairs of sentences differing only in gender to observe differential treatment in model predictions. For example, the paper measures bias in coreference resolution by comparing the coreference likelihood between words like "doctor" and pronouns such as "he" and "she." For LLMs, it assesses bias through the disparities in word emission probabilities given gendered sentence prefixes.
Mitigation Strategies
A major contribution of the study is the introduction of Counterfactual Data Augmentation (CDA), a technique that augments training datasets with intervention-based modifications. This method creates semantically equivalent paired instances differing only in targeted attributes like gender, thus encouraging models to generalize beyond these biases. The efficacy of CDA is compared against Word Embedding Debiasing (WED), a previously established method aimed at mitigating bias within embeddings. The combination of these methods shows an appreciable reduction in gender bias with minimal to no impact on model accuracy. Notably, CDA alone is shown to be highly effective, making it a compelling approach for practitioners seeking bias mitigation without significant overhead.
Experimental Findings
The authors provide a rigorous empirical assessment using state-of-the-art models for coreference resolution and language modeling. Key findings include:
- Bias Propagation: Throughout training, gender bias intensifies as the model loss minimizes, suggesting optimization processes inherently favor biased solutions (Figure 1).
- Reduction via CDA: Applying CDA significantly diminishes gender bias without detracting from model performance, outperforming WED, especially when embeddings are co-trained with model parameters.
- Combination Effects: For models using pre-trained embeddings, CDA combined with WED yields optimal bias reduction, showcasing the cumulative potential of these methods.
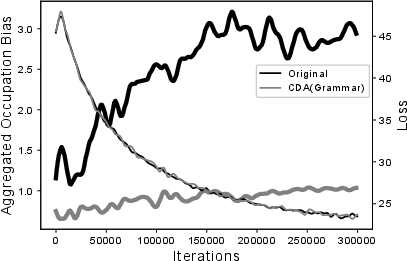
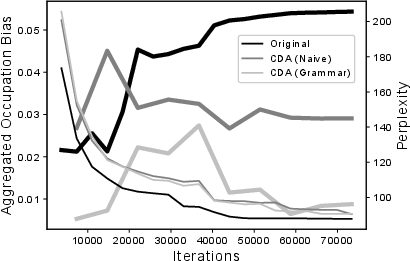
Figure 1: Performance and aggregate occupation bias during training phases for coreference resolution with model of [lee2017end].
Implications and Future Research
The findings highlight the nuanced nature of gender bias in neural NLP models and underscore the importance of CDS-based interventions in maintaining model neutrality. These insights are pivotal for domains heavily reliant on unbiased machine learning models, ensuring fair and equitable performance across demographic attributes.
Future research directions include exploring similar biases in more complex tasks like neural machine translation and implementing real-time bias detection mechanisms. Additionally, the development of interpretability tools to dissect the internal states of neural networks could illuminate underlying reasons for bias manifestation, potentially guiding the creation of preemptive bias mitigation techniques embedded within model architectures.
Conclusion
The comprehensive analysis presented in this paper advances the understanding of gender bias in NLP models, providing a robust framework for both detection and mitigation. By blending novel methodologies such as CDA with established techniques like WED, the research paves the way for developing more equitable and performant NLP systems. The findings serve as a clarion call for continuous vigilance and innovation in AI ethics, particularly as the deployment of NLP models becomes ubiquitous across various sectors.