- The paper presents deep learning-based end-to-end systems that significantly outperform traditional methods in detecting and recognizing scene text.
- It details innovative methodologies such as object detection adaptations and sub-text component approaches to robustly handle curved or irregular text.
- The study emphasizes the importance of synthetic data generation and weak supervision in overcoming annotation challenges and boosting performance metrics.
Scene Text Detection and Recognition in the Deep Learning Era: A Technical Overview
Introduction and Problem Scope
Scene text detection and recognition, the process of localizing and transcribing text in natural images, is a critical subfield of computer vision with applications in document digitization, autonomous navigation, instant translation, and content analysis. The task is characterized by significant challenges: high variability in text appearance (font, color, orientation, curvature), complex and cluttered backgrounds, and frequent image degradations (blur, low resolution, occlusion). The advent of deep learning has fundamentally transformed the methodology and performance landscape of this domain, enabling robust, end-to-end trainable systems that surpass traditional hand-crafted feature-based approaches.
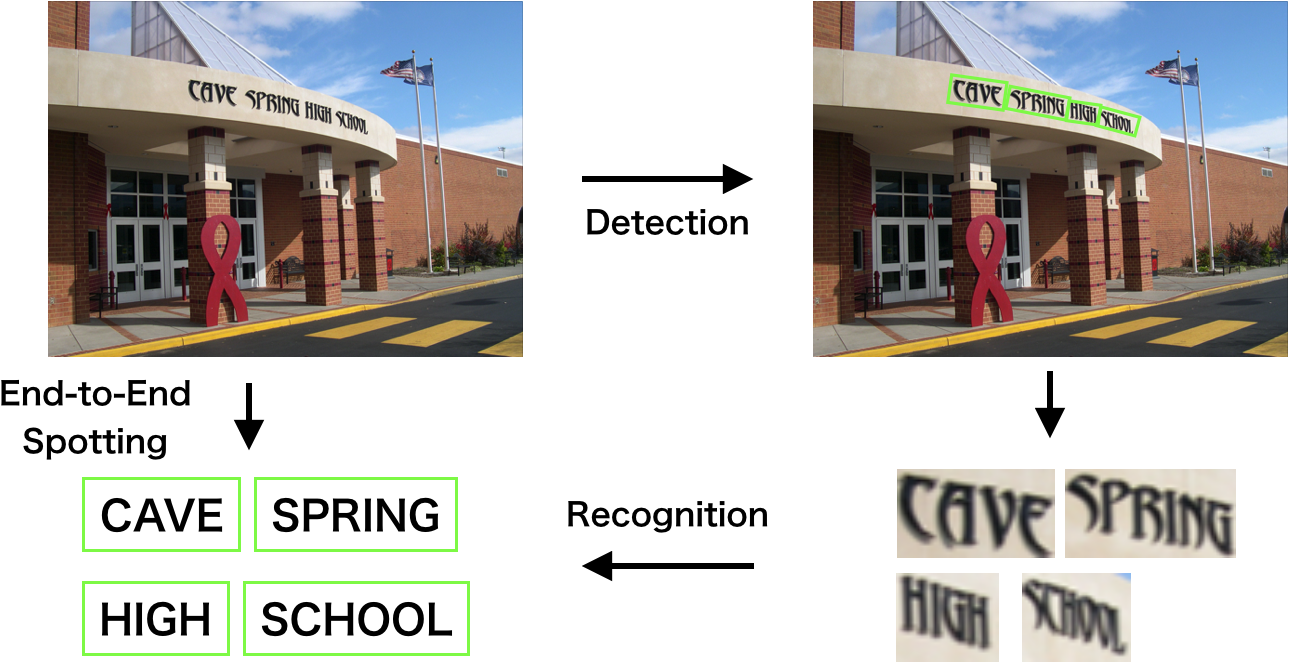
Figure 1: Schematic diagram of scene text detection and recognition, illustrating the pipeline from raw scene image to detected and recognized text regions.
Pre-Deep Learning Approaches
Prior to deep learning, scene text detection and recognition relied heavily on hand-crafted features and multi-stage pipelines. Detection methods were dominated by Connected Components Analysis (CCA) and Sliding Window (SW) classification, leveraging features such as Maximally Stable Extremal Regions (MSER) and Stroke Width Transform (SWT) for candidate extraction and filtering.

Figure 2: Illustration of traditional methods with hand-crafted features: (1) MSER, assuming chromatic consistency; (2) SWT, assuming consistent stroke width.
Recognition was typically decomposed into sub-problems: binarization, segmentation, character recognition, and word correction, with each stage requiring domain-specific heuristics. These approaches suffered from limited generalization, high sensitivity to noise, and complex, brittle pipelines.
Deep Learning Methodologies
The deep learning era introduced a paradigm shift, enabling automatic feature learning, end-to-end optimization, and significant performance gains. The field now encompasses four main system types: detection, recognition, end-to-end pipelines, and auxiliary techniques (e.g., synthetic data generation).
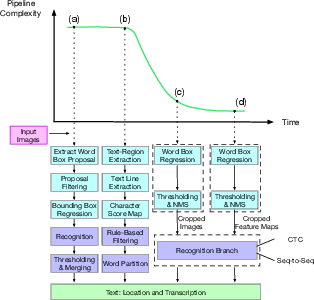
Figure 3: Representative scene text detection and recognition system pipelines, showing the evolution from multi-step to end-to-end architectures.
Detection: From Object Detection to Sub-Text Components
Object Detection-Inspired Methods
Early deep learning-based detectors adapted general object detection frameworks (e.g., SSD, YOLO, Faster R-CNN) to the text domain, modifying anchor box definitions and regression targets to accommodate the unique geometric properties of text (arbitrary orientation, extreme aspect ratios).
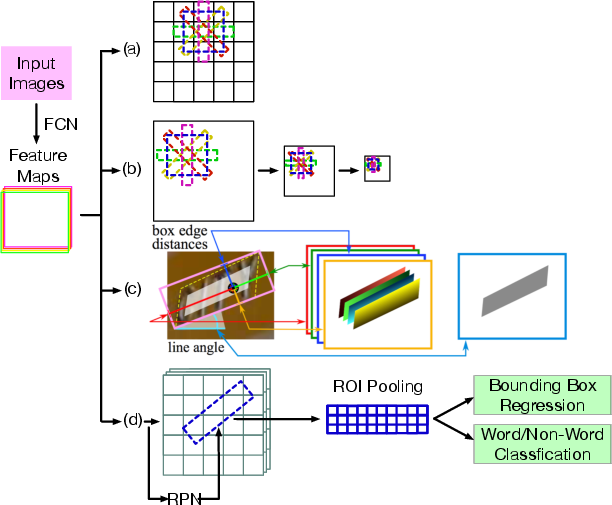
Figure 4: High-level illustration of methods inspired by general object detection: (a) YOLO-style regression; (b) SSD-style multi-scale prediction; (c) direct bounding box regression; (d) two-stage refinement.
Notable models include TextBoxes (SSD variant with quadrilateral anchors), EAST (U-Net backbone for direct geometry regression), and rotation-sensitive RPNs for arbitrary-oriented text. These approaches enabled real-time inference and simplified pipelines but struggled with highly curved or long text due to receptive field limitations.
Sub-Text Component-Based Methods
To address the limitations of bounding box-based detectors, a new class of methods emerged that model text as a composition of local elements—segments, pixels, or character centers—followed by grouping or linking strategies.
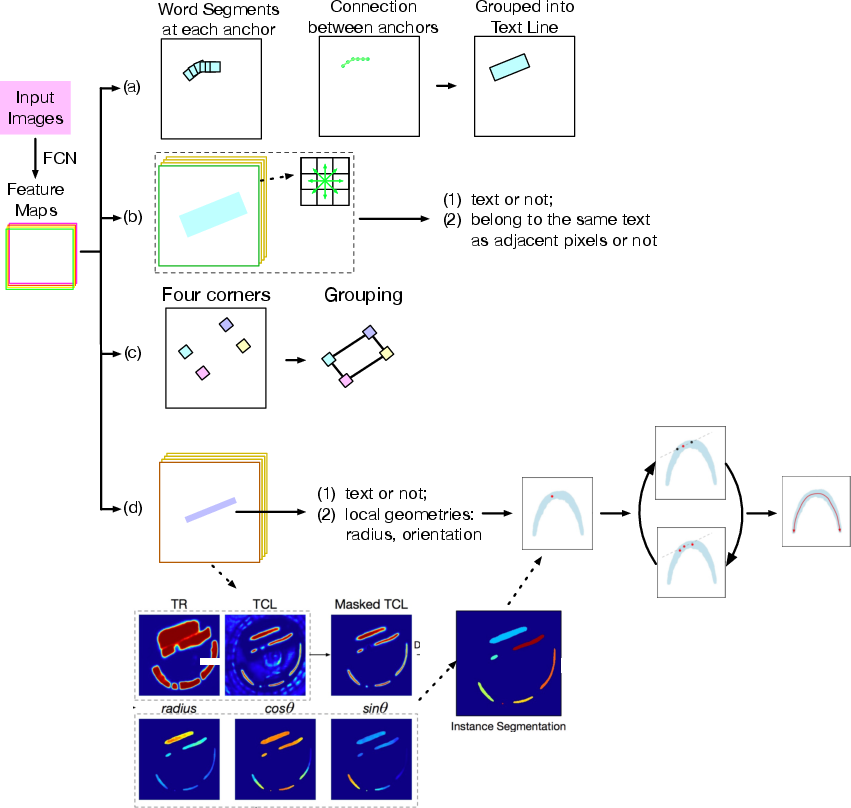
Figure 5: Representative methods based on sub-text components: (a) SegLink—segment detection and linking; (b) PixelLink—pixel-level instance segmentation; (c) Corner Localization—corner detection and grouping; (d) TextSnake—centerline and local geometry prediction.
Pixel-level methods (e.g., PixelLink, border learning) treat detection as instance segmentation, while component-level methods (e.g., CTPN, SegLink) predict and connect text segments. TextSnake introduces a flexible representation using sliding disks along the text centerline, achieving strong generalization to curved and irregular text, with up to 20% F1-score improvement on curved text benchmarks.

Figure 6: (a)-(c): Text represented as horizontal rectangles, oriented rectangles, quadrilaterals; (d): TextSnake's sliding-disk representation.
Character-level approaches (e.g., CRAFT) further refine granularity, predicting character centers and affinity links, but require weak or semi-supervised training due to annotation scarcity.
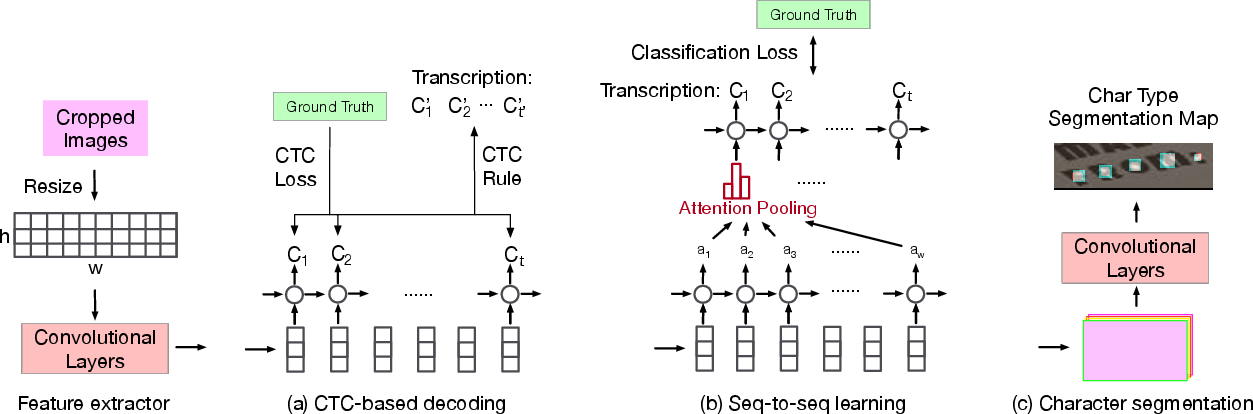
Recognition: Sequence Modeling and Irregular Text
Scene text recognition models typically operate on cropped word images. The dominant frameworks are:
Irregular text (curved, rotated, or perspective-distorted) presents a major challenge. Solutions include:
- Rectification modules: Spatial Transformer Networks (STN) or Thin-Plate-Spline transformations to normalize input geometry before recognition (e.g., ASTER, ESIR).
- 2D attention and character anchor pooling: Directly attending to 2D feature maps or extracting features along predicted centerlines.
- Segmentation-based recognition: Treating recognition as semantic segmentation, robust to shape but prone to single-character errors.
Empirical results show that rectification-based models, when trained with synthetic curved text, achieve state-of-the-art accuracy on irregular text datasets.
End-to-End Systems
Recent advances have produced unified, end-to-end trainable systems that jointly detect and recognize text, minimizing error propagation and enabling global optimization.
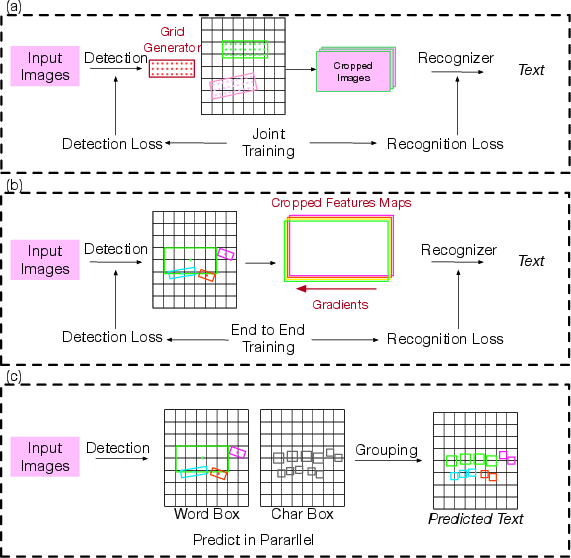
Figure 8: Mainstream end-to-end frameworks: (a) grid-based detection and cropping; (b) feature map cropping and recognition; (c) character-level detection and grouping.
Two-step pipelines detect and crop word regions for separate recognition, while two-stage and one-stage models (e.g., FOTS, Mask TextSpotter, Convolutional Character Networks) integrate detection and recognition branches, often sharing backbone features and enabling joint training.
Auxiliary Techniques: Synthetic Data and Weak Supervision
Synthetic data generation is critical for overcoming annotation scarcity. Methods such as SynthText and UnrealText leverage 2D and 3D rendering, semantic segmentation, and depth estimation to produce large-scale, realistic training data, significantly boosting both detection and recognition performance.
Semi-supervised and weakly-supervised learning strategies (e.g., bootstrapping character detectors from word-level annotations) further reduce reliance on costly manual labeling, enabling scalable dataset expansion.
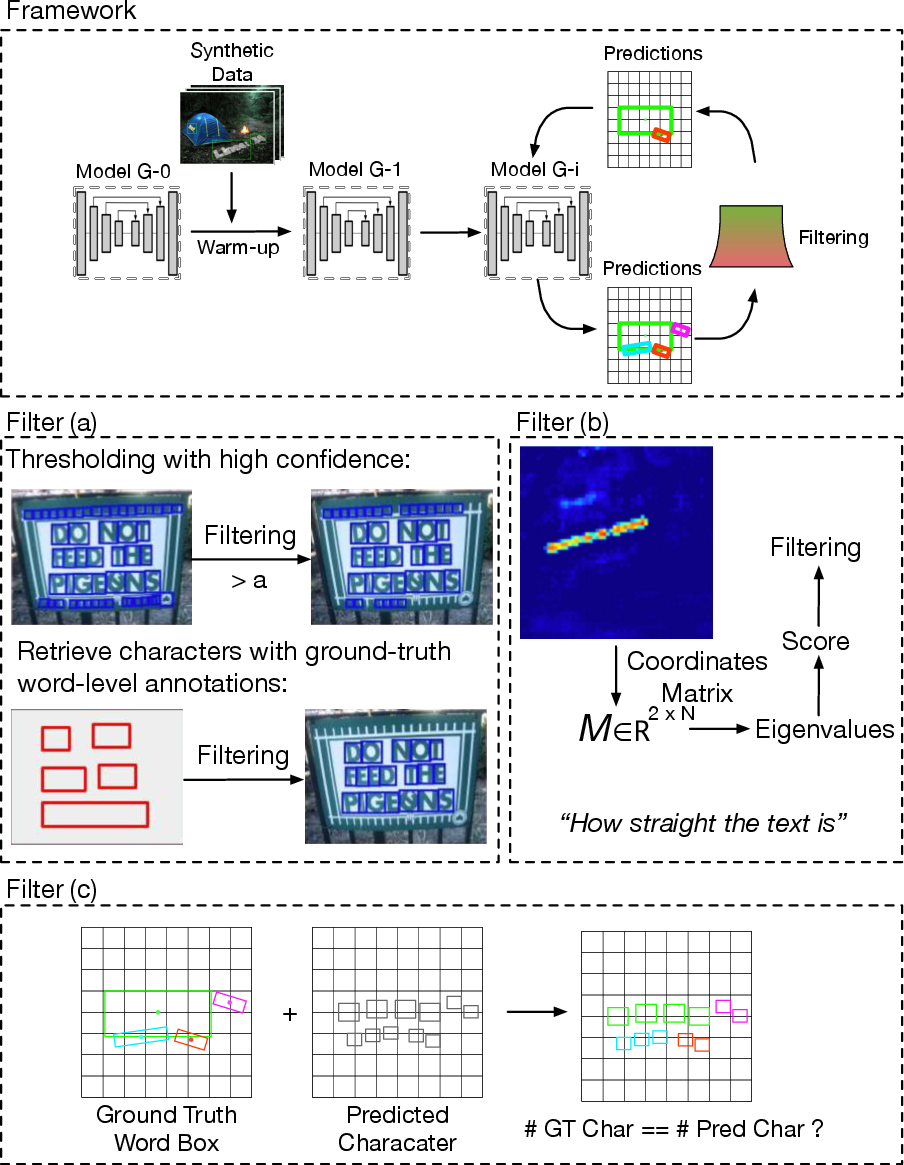
Figure 9: Overview of semi-supervised and weakly-supervised methods for character annotation bootstrapping.
Benchmark Datasets and Evaluation Protocols
The field has benefited from a proliferation of diverse datasets, each targeting specific challenges: ICDAR 2015 (blurred, small, multi-oriented text), Total-Text and CTW1500 (curved text), ICDAR MLT (multilingual), and LSVT/CTW (large-scale, character-level Chinese text). Evaluation protocols vary, with IOU-based and DetEval metrics for detection, and word/character-level accuracy or edit distance for recognition.
Empirical results demonstrate that deep learning-based methods consistently outperform traditional approaches, with F1-scores exceeding 90% on standard benchmarks for straight text, and substantial gains on irregular text datasets when using flexible representations and synthetic data pretraining.
Applications
Scene text detection and recognition systems are deployed in a wide range of applications:
- Automatic data entry: Digitization of forms, receipts, and identity documents.
- Identity authentication: Automated extraction of information from ID cards and passports.
- Augmented computer vision: Autonomous vehicles, instant translation, and assistive technologies for the visually impaired.
- Content analysis: Video and image content tagging, sentiment analysis, and moderation.
Challenges and Future Directions
Despite significant progress, several open challenges remain:
- Multilingual and large-vocabulary recognition: Most research focuses on English; robust models for languages with large character sets (e.g., Chinese, Japanese) are needed.
- Robustness and generalization: Models must handle unseen domains, degraded images, and imperfect detections.
- Evaluation metrics: Current metrics may not fully capture the impact of detection errors on recognition; tighter integration of detection and recognition evaluation is warranted.
- Synthetic data realism: Further advances in 3D rendering and domain adaptation are required to close the gap between synthetic and real-world data.
- Efficiency and deployment: Real-time inference on resource-constrained devices remains a bottleneck; model compression and lightweight architectures are active research areas.
- Dataset scale and annotation quality: Larger, more diverse, and better-annotated datasets are essential for continued progress.
Conclusion
The deep learning era has enabled substantial advances in scene text detection and recognition, with end-to-end trainable systems, flexible representations, and synthetic data generation driving state-of-the-art performance. Ongoing research is focused on improving robustness, generalization, and efficiency, as well as expanding coverage to more languages and challenging real-world scenarios. The field is poised for further integration with broader vision and language understanding systems, with implications for a wide array of practical applications.