- The paper introduces practical methods for integrating ASR toolkits such as Kaldi, FAVE-align, and Montreal Forced Aligner to enhance phonetic analysis.
- The paper details step-by-step procedures for setting up acoustic models and aligning phonetic boundaries, making advanced techniques accessible to non-engineering researchers.
- The paper emphasizes the democratization of computational tools for robust linguistic studies, paving the way for improved speech recognition systems.
An Expert Overview of "Corpus Phonetics Tutorial"
Introduction to Corpus Phonetics
The field of corpus phonetics seeks to leverage large-scale computational processing for phonetic analysis, thereby enabling more extensive and statistically robust linguistic studies. This tutorial by Eleanor Chodroff is designed to familiarize speech scientists, particularly those without an engineering background, with advanced tools and methods for speech data processing. The tutorial emphasizes the integration of computational power with linguistic research, highlighting the role of automatic speech recognition (ASR) frameworks and scripting in facilitating large-scale phonetic analyses.
The tutorial extensively covers various tools pivotal to corpus phonetics, drawn from ASR technologies. Key tools include the Kaldi ASR Toolkit, FAVE-align, the Montreal Forced Aligner, and AutoVOT, among others. Each of these tools is pivotal for different aspects of speech processing:
- Kaldi ASR Toolkit: Described as the cornerstone for speech recognition and alignment tasks, Kaldi offers infrastructure to train acoustic models and deploy ASR systems tailored to specific speech corpora. The tutorial provides detailed instructions for setting up Kaldi, training acoustic models using Gaussian Mixture Models (GMMs), Hidden Markov Models (HMMs), and variants like LDA-MLLT and fMLLR.
- FAVE-align and Montreal Forced Aligner: Both tools are used for forced alignment, syncing phonetic boundaries within an audio file to the hypothesized model of speech. FAVE-align is particularly noted for American English, whereas the Montreal Forced Aligner supports multiple languages, making it versatile for cross-linguistic applications.
- AutoVOT: This tool automatically measures the voice onset time (VOT) in speech, crucial for studies focusing on stop consonant production. The tutorial guides users through the process of modifying TextGrids to capitalize on AutoVOT's capabilities effectively.
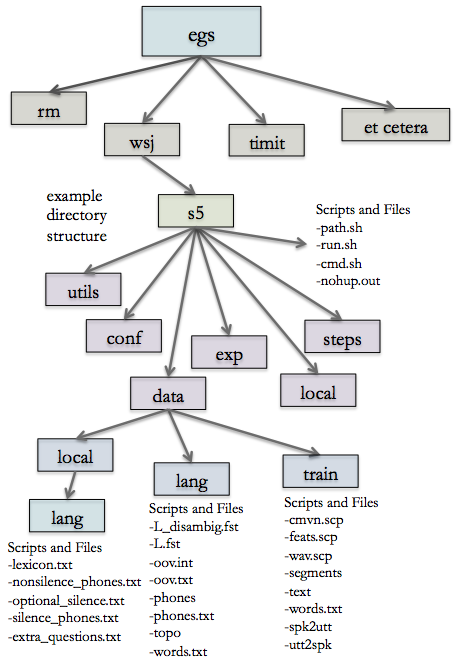
Figure 1: Example directory structure for organizing Kaldi experiments.
Numerical Results and Claims
The tutorial, being a comprehensive guide, does not primarily report experimental results or bold claims but rather focuses on the step-by-step implementation of tools proven to enrich phonetic research. The efficacy of these tools is evidenced by their widespread adoption in linguistic studies that require high-throughput, precise phonetic measurements.
Implications and Future Developments
The implications of this tutorial are profound for both theoretical phonetics and practical applications in ASR. By democratizing access to advanced computational tools, it enables researchers to transcend traditional limitations of small sample sizes, fostering more generalized and nuanced linguistic insights. Practically, it sets the stage for more accurate speech recognition systems sensitive to phonetic nuances, vital for enhancing user interactions with speech-driven technologies.
Future developments in AI and ASR could enhance the functionality of these toolkits, particularly through the integration of deep learning for improved model training and phonetic recognition in noisy or diverse linguistic environments.
Conclusion
Chodroff's "Corpus Phonetics Tutorial" serves as a critical resource for researchers aiming to integrate large-scale phonetic analysis into their work. By bridging the gap between linguistic science and computational engineering, it empowers researchers to conduct more detailed and expansive phonetic studies. As computational resources and techniques advance, the methodologies outlined in this tutorial are poised to evolve, further enriching the scope and depth of phonetic research.