- The paper shows that adversarial training naturally induces low-rank and sparse weight matrices that enhance robustness.
- It demonstrates that ℓ1 and nuclear norm regularizations significantly lower fooling ratios in both FCNNs and CNNs.
- Experimental results indicate that compressed weight structures promote improved resistance against adversarial examples.
The Effect of Low-Rank Weights on Adversarial Robustness of Neural Networks
Introduction
The paper explores the influence of low-rank weight structures on the adversarial robustness of deep neural networks (DNNs). It investigates how properties such as effective rank and effective sparsity in weight matrices impact the model's resilience against adversarial attacks. A key observation is that adversarial training tends to naturally foster these low-rank and sparse structures. Conversely, promoting these properties through regularization techniques can augment adversarial robustness, notably in convolutional neural networks (CNNs).
Theoretical Foundations
This research highlights significant hypotheses regarding adversarial examples within DNNs. The supposed linear nature of DNNs around data points is hypothesized to cause susceptibility to adversarial perturbations. However, some studies counter this, suggesting adversarial robustness in simple linear classifiers. Discussions incorporate factors such as decision boundary flatness, evolutionary stalling during training, and high dimensionality. A common thread is the necessity of compressed representations and effective dimensionality reduction as key elements in enhancing adversarial robustness.
Methodology
The paper presents three primary regularization techniques designed to encourage sparsity and low-rankness:
- ℓ1-Regularization: Designed to induce sparsity in weight matrices.
- Nuclear Norm Regularization: Aids in promoting low-rank weight matrices.
- Joint Regularization: Focuses on minimizing the ℓ1-norm of the combined product of weight matrices, aiming to mimic robustness characteristics akin to linear networks.
These techniques are evaluated using two architectures: a fully connected neural network (FCNN) for MNIST and a convolutional network (CNN) for Fashion-MNIST.
Experiments and Observations
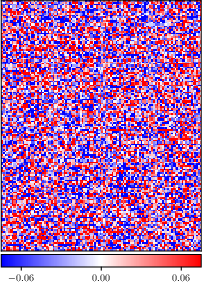
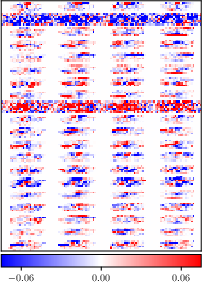
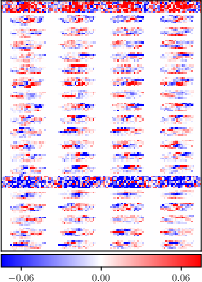
Figure 1: Reshaped input weight matrix $#1{W}^1 \in \mathbb{R}^{20 \times 784}$ of the FCNN after natural vs. adversarial training with ϵ=0.05.
In experimental settings, the paper shows how adversarial training significantly reduces the effective rank and sparsity of weights while also decreasing mutual information, which is an indication of compression. Notably, adversarial training impacts the network by re-structuring weights to become sparser and lower in rank.
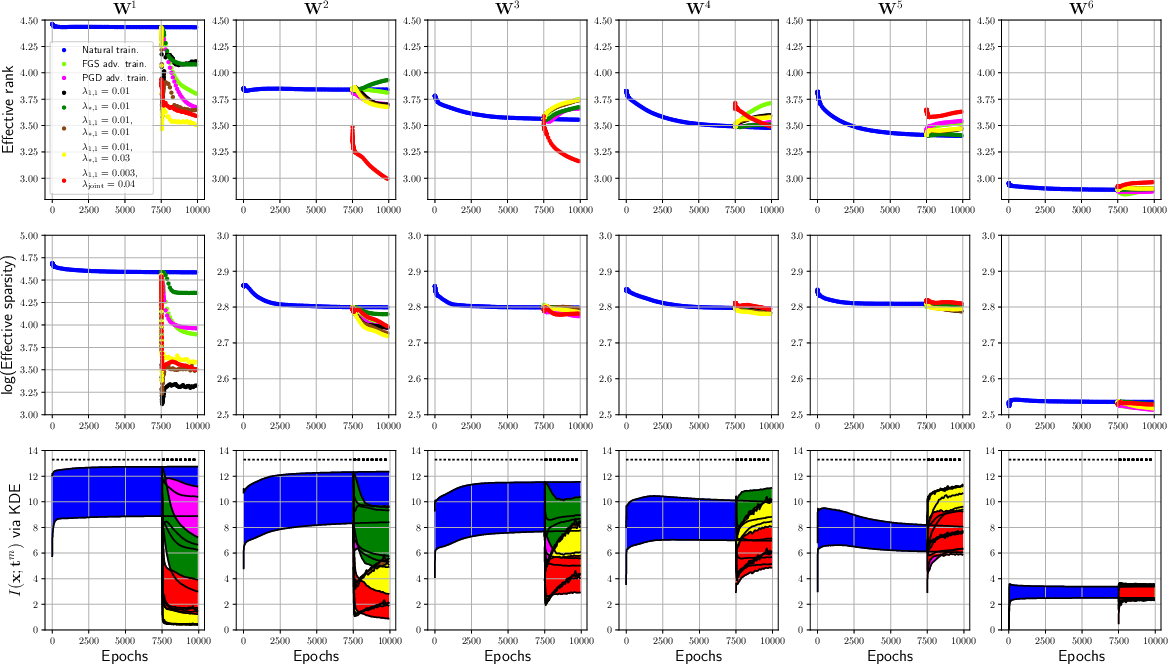
Figure 2: Fooling ratios of the FCNN showcasing how distinct regularization methods improve resilience to adversarial attacks.
For FCNNs, the paper investigates the effect of direct regularization on the input weight matrix and discovers that both ℓ1-regularization and nuclear norm regularization significantly decrease fooling ratios, implying enhanced robustness. In CNNs, reshaping convolutional filters to promote low-rank structures showed notable improvement in adversarial robustness.
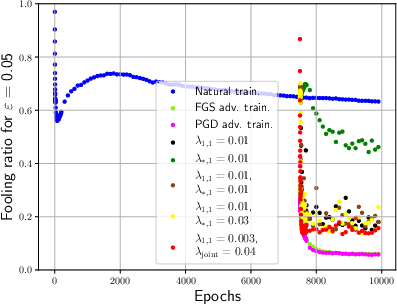
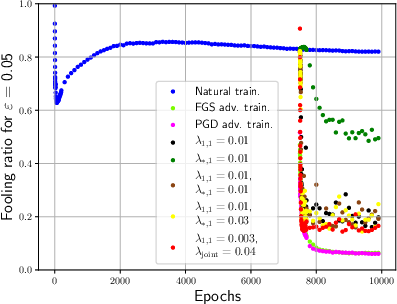
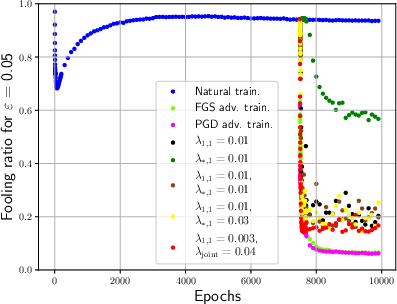
Figure 3: Effective rank and sparsity metrics for both CNN and FCNN models during training sessions.
Discussion
The results suggest that while adversarial robustness can be substantially improved by promoting low-rank and sparse weights, these properties alone do not fully account for the efficacy seen in adversarial training. This implies there may be other unknown aspects influencing adversarial robustness.
Conclusion
The paper proposes two major claims:
- Adversarial training leads to low-rank and sparse weights.
- Simultaneously low-rank and sparse weights promote robustness against adversarial examples.
The paper demonstrates that investing in weight matrix compression could provide further insights and improvements in the quest for robust neural network architectures. Future inquiries may target identifying optimal merges of these attributes for even greater robustness.