- The paper demonstrates that combining CNNs for local feature extraction with Bi-LSTMs for temporal dependency capture significantly improves sentiment classification, achieving 90% accuracy on IMDB.
- The methodology leverages pre-trained GloVe embeddings, varied convolutional filters, and a two-layer Bi-LSTM, with final predictions produced by averaging both models' outputs.
- Experimental results show that the ensemble outperforms individual CNN and LSTM models and converges faster on training data, indicating enhanced model efficiency.
Deep Sentiment Analysis via CNN and Bi-LSTM Ensemble
This paper introduces a sentiment analysis framework leveraging an ensemble of CNNs and bidirectional LSTMs (Bi-LSTMs) to improve accuracy on sentiment classification tasks. The authors posit that CNNs are effective at extracting local structural information, while LSTMs excel at capturing temporal dependencies within text. By combining these models, the framework aims to leverage the strengths of both architectures for enhanced sentiment analysis.
Proposed Model Architecture
The ensemble model architecture (Figure 1) consists of two primary components: a CNN and a Bi-LSTM network. The CNN is designed to extract local features from the input text, while the Bi-LSTM captures temporal dependencies. The outputs of both networks are then combined to produce a final sentiment prediction.
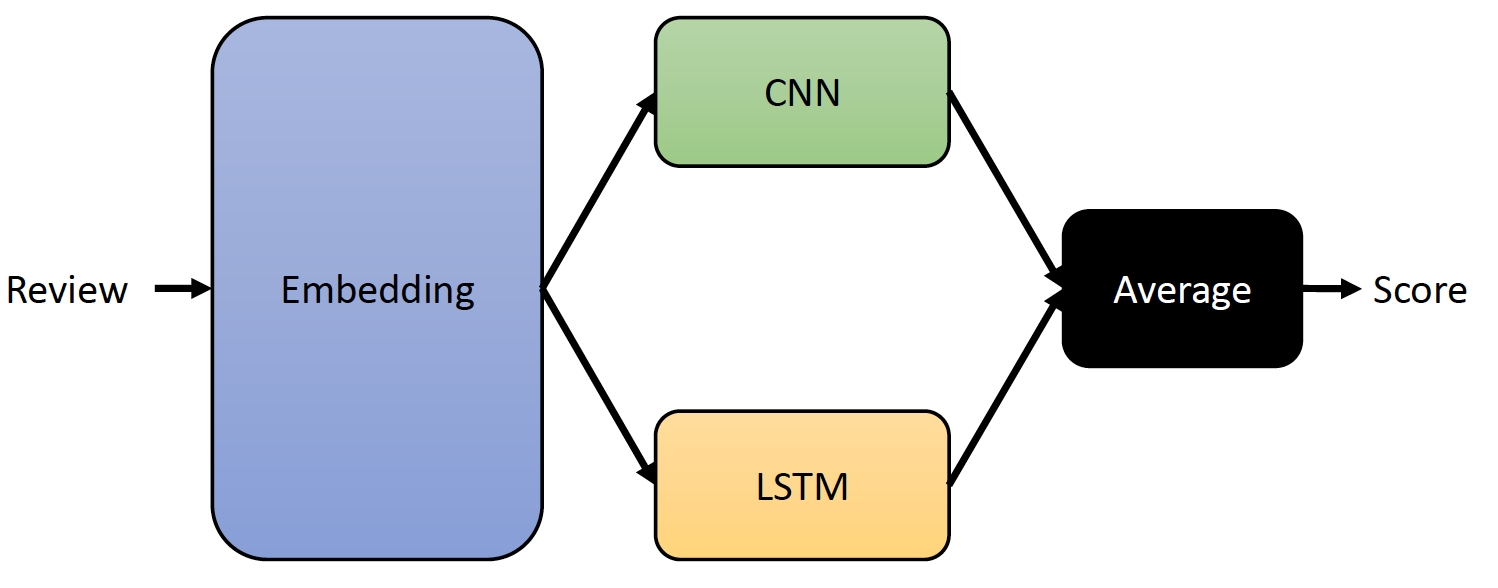
Figure 1: The block diagram of the proposed ensemble model.
LSTM Model Details
The LSTM component employs a two-layer Bi-LSTM network, utilizing pre-trained GloVe embeddings for word representation (Figure 2). The Bi-LSTM processes the input sequence in both forward and reverse directions to capture contextual information from both past and future words. The LSTM architecture incorporates input, output, and forget gates to regulate information flow and mitigate the vanishing gradient problem, facilitating the learning of long-range dependencies. The relationships between input, hidden states, and gates are defined by the following equations:
ft=σ(W(f)xt+U(f)ht−1+b(f)), it=σ(W(i)xt+U(i)ht−1+b(i)), ot=σ(W(o)xt+U(o)ht−1+b(o)), ct=ft⊙ct−1+it⊙tanh(W(c)xt+U(c)ht−1+b(c)), ht=ot⊙tanh(ct)
where xt is the input at time step t, σ is the sigmoid function, and ⊙ denotes element-wise product.
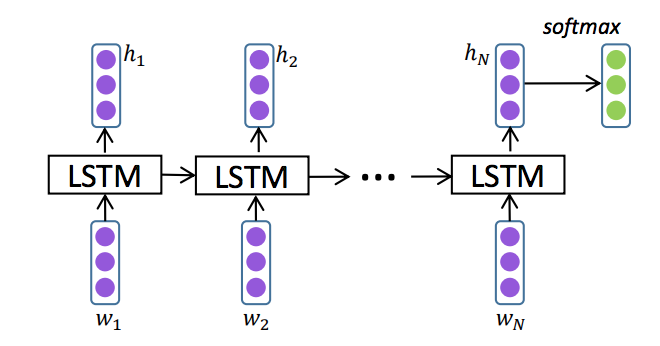
Figure 3: The architecture of a standard LSTM model [lstm_cell].
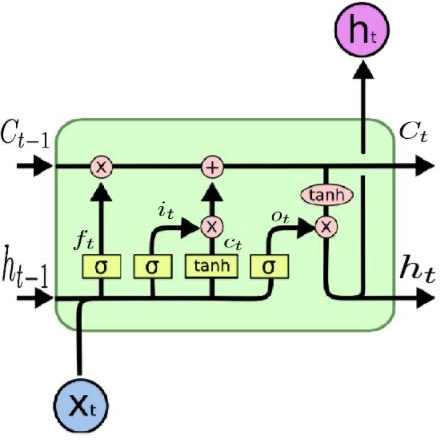
Figure 4: The architecture of a standard LSTM module [lstm_cell].

Figure 2: The architecture of a standard LSTM module [lstm_cell].
CNN Model Details
The CNN component uses pre-trained GloVe embeddings and convolutional filters of varying sizes (1, 2, 3, and 4) (Figure 5). Each filter size is associated with 100 feature maps. Max-pooling is applied to the convolutional outputs, and the resulting features are concatenated and passed through two fully connected layers before the final softmax classification.
Figure 5: The general architecture CNN based text classification models.
Ensemble Strategy
The ensemble model combines the predictions of the CNN and Bi-LSTM models by averaging their probability scores. This approach aims to leverage the complementary strengths of both models.
Figure 6: The proposed ensemble model for sentiment analysis.
Experimental Evaluation
The proposed framework was evaluated on the IMDB review and SST2 datasets. The models were trained for 100 epochs using the ADAM optimizer with a learning rate of 0.0001 and a weight decay of 0.00001. The batch size was set to 64 for SST2 and 50 for IMDB.
Datasets
The IMDB dataset consists of 50,000 movie reviews, evenly split into training and testing sets, with balanced positive and negative sentiment labels. The SST2 dataset is a binary sentiment analysis dataset from the Stanford Sentiment Treebank.
Results and Discussion
The ensemble model achieved an accuracy of 90% on the IMDB dataset and 80.5% on the SST2 dataset. These results demonstrate a performance gain compared to the individual CNN (89.3% on IMDB, 80.2% on SST2) and LSTM (89% on IMDB, 80% on SST2) models. Visualizations of frequent words in positive and negative reviews for both datasets are shown in Figures 7 and 8. The distribution of predicted probability scores for the SST2 dataset (Figure 7) indicates that the CNN model produces scores closer to the extremes (0 and 1) compared to the LSTM model. Training accuracy curves (Figures 10 and 11) show that the CNN model converges faster than the LSTM model on both datasets.
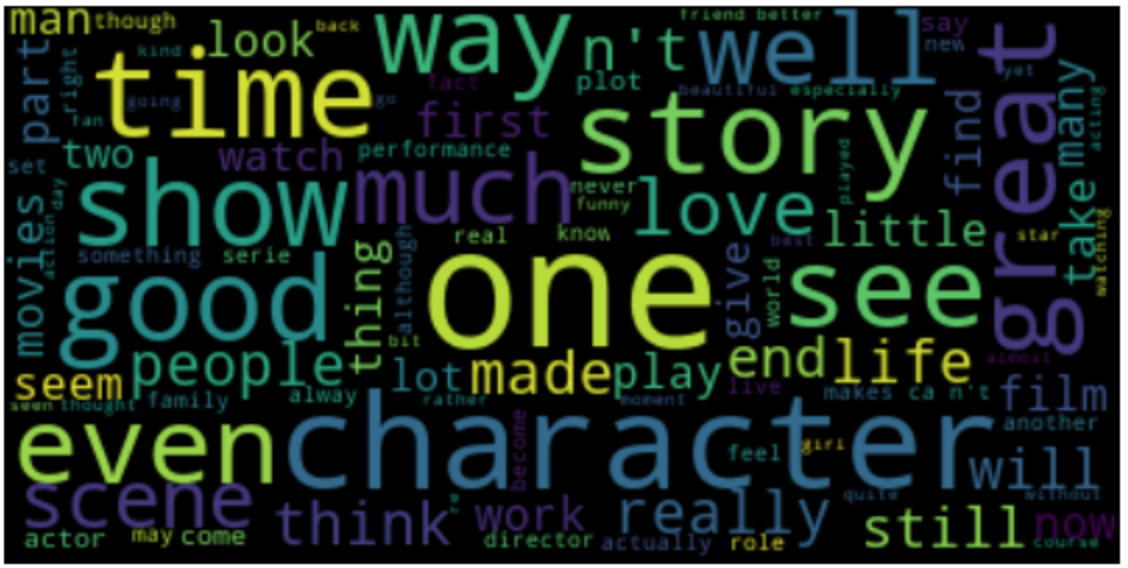
Figure 8: The visualization of most frequent words for both positive and negative reviews for IMDB database. The top and bottom image denote the frequent words for positive and negative reviews respectively.
Figure 9: The visualization of most frequent words for both positive and negative reviews for SST2 database. The top and bottom image denote the frequent words for positive and negative reviews respectively.
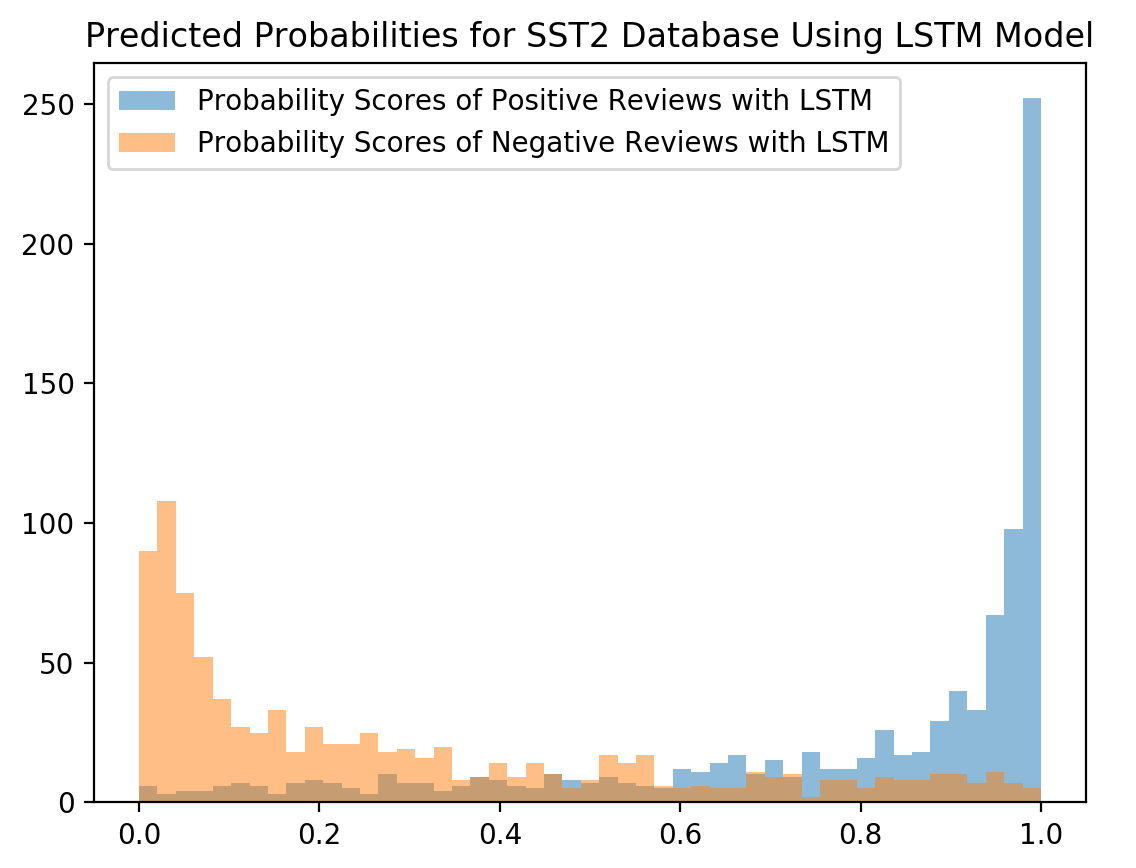
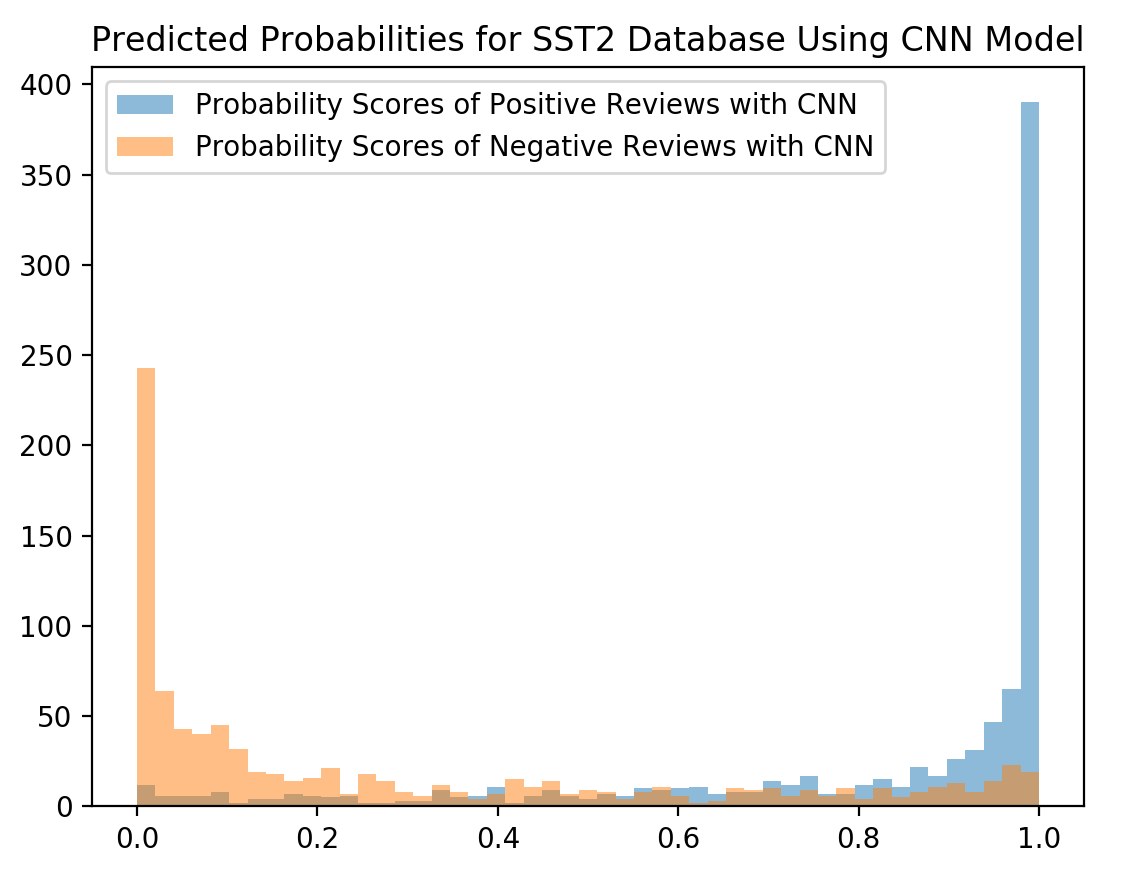
Figure 7: The distribution of predicted probability scores predicted by LSTM and CNN for the reviews in SST2 database.
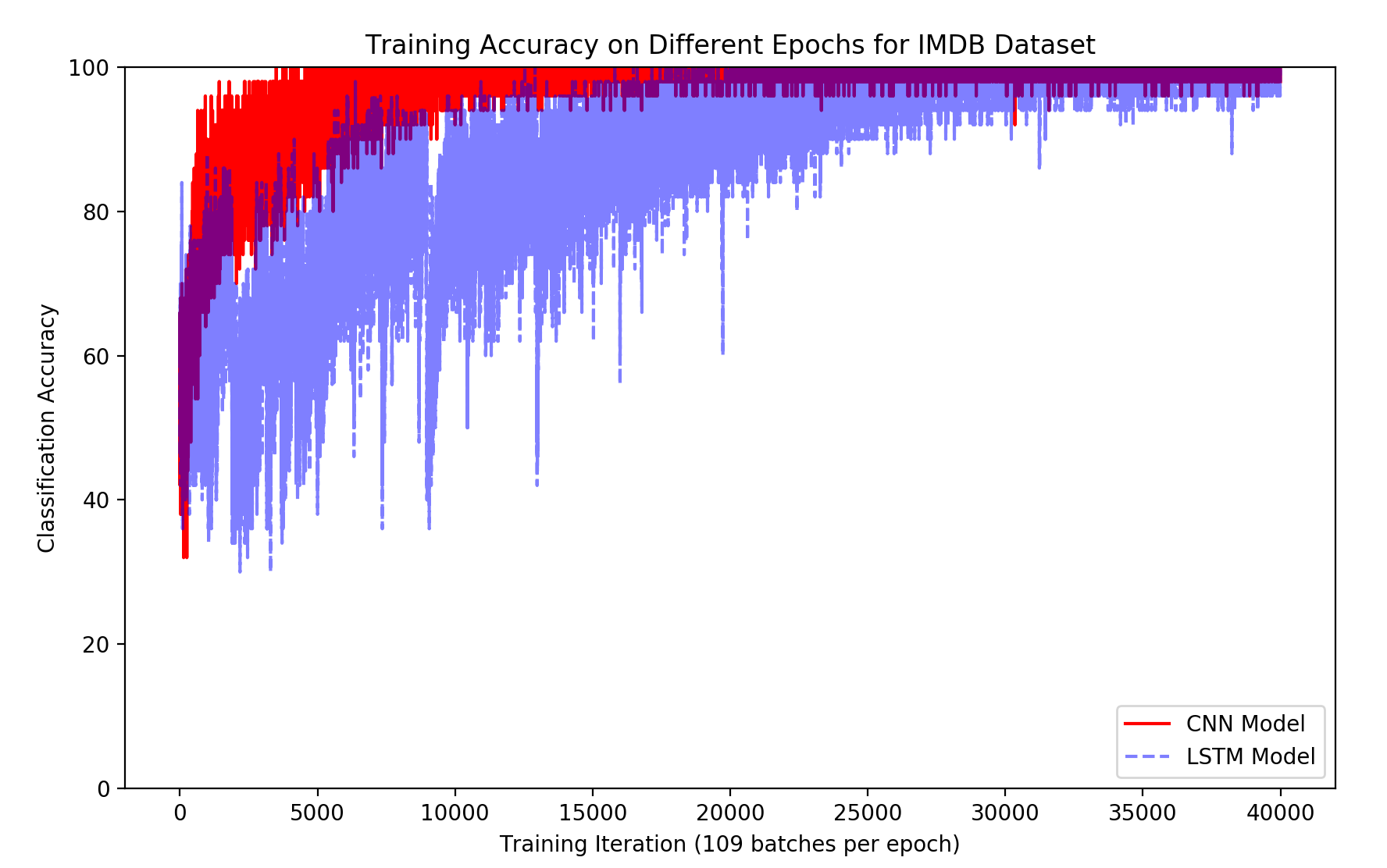
Figure 10: The training accuracy at different epochs for IMDB database.
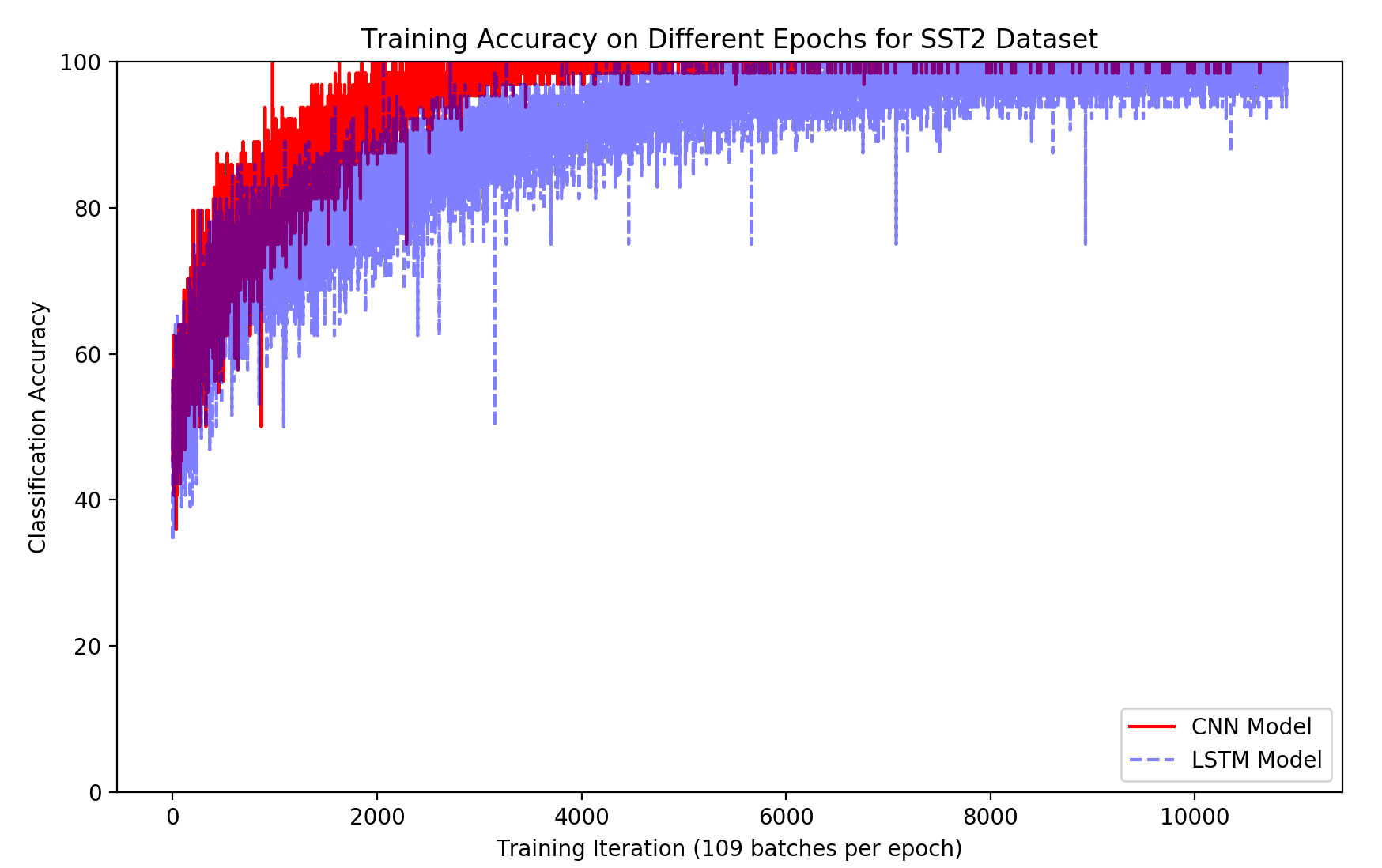
Figure 11: The training accuracy at different epochs for SST2 database.
Conclusion
The authors conclude that their ensemble model, which combines CNNs and Bi-LSTMs, achieves improved performance in sentiment analysis compared to using either model alone. They suggest future work could involve joint training of the CNN and LSTM components to further enhance performance. The ensemble approach could potentially be applied to other deep learning-based text processing tasks.