- The paper presents a comprehensive survey of video object segmentation and tracking, synthesizing diverse methodologies such as unsupervised, semi-supervised, and interactive approaches.
- It details various frameworks including CNN-based mask propagation and graph-partitioning, addressing challenges like occlusion, motion blur, and scale variations.
- The survey evaluates benchmark datasets and metrics while identifying future trends like 3D tracking and multi-camera integration for robust video analysis.
Survey on Video Object Segmentation and Tracking
Video object segmentation (VOS) and video object tracking (VOT) are key areas in computer vision research aiming to tackle challenges such as occlusion, deformation, motion blur, and scale variation. The intersection of VOS and VOT offers promising solutions to enhance video analysis tasks in applications like video summarization, high-definition video compression, human-computer interaction, and autonomous vehicles.
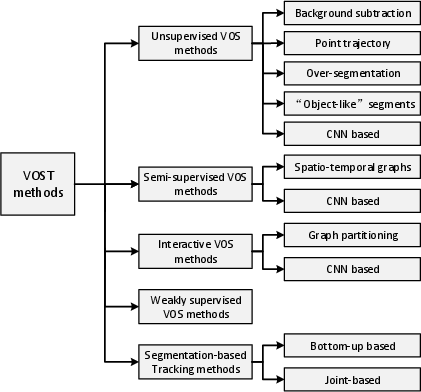
Figure 1: Taxonomy of video object segmentation and tracking.
Categorization of Approaches
Unsupervised Video Object Segmentation
Unsupervised VOS methods automatically identify and segment objects without user input. These approaches assume that objects exhibit distinct motion or frequent occurrences. The techniques can be divided into:
- Background Subtraction: Methods like MoG and KDE model the scene's background and identify foreground objects by detecting deviations in pixel behavior.
- Point Trajectory: Techniques employ long-term motion analysis using sparse optical flow for consistent clustering of trajectories.
- Over-segmentation: Graph-based approaches group similar pixels into superpixels or supervoxels to facilitate segmentation.
- Object-like Segments: Approaches focus on generating hypothesis segments like saliency maps or object proposals to distinguish foreground objects.
- CNN-based Methods: These use deep learning to associate motion cues or refine masks leveraging CNN architectures.
Semi-supervised Video Object Segmentation
Semi-supervised VOS requires initial object masks to guide segmentation in subsequent frames. Two primary types are:
- Spatio-temporal Graphs: With an emphasis on pixel/superpixel-based graphs, optimization techniques like MRF and CRF are used for label propagation.
- CNN-based Methods: Opt for motion-based mask propagation via optical flow or appearance-based detection, often incorporating RNNs.
Figure 2 illustrates how mask propagation algorithms estimate the segmentation mask of the current frame from the prior frame to enhance segmentation accuracy.
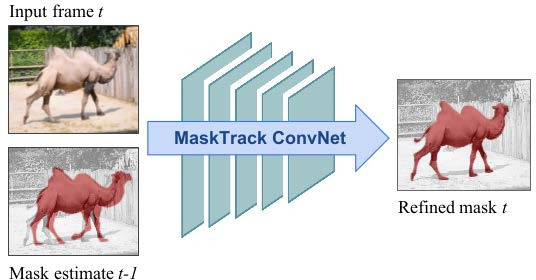
Figure 2: Illustration of mask propagation to estimate the segmentation mask using previous frame's guidance.
Interactive Video Object Segmentation
Interactive VOS utilizes user interaction through scribbles or clicks to refine segmentation iteratively. Common techniques include:
- Graph Partitioning Methods: Such as graph-cuts and random walker algorithms.
- Active Contours: Touch-based methods for object boundary enhancement.
- CNN-based Interaction: User input guides neural networks for accurate segmentation, showcasing significant advancement.
Weakly Supervised Video Object Segmentation
These approaches leverage weak annotations, such as bounding boxes or natural language descriptions, to perform semantic segmentation of objects across video datasets. This domain aims to alleviate manual annotation challenges while maintaining segmentation accuracy.
Segmentation-based Tracking
Segmentation-based tracking intertwines VOS and VOT, separating tasks that benefit from joint processing:
- Bottom-up Methods: Non-rigid object handling using contour matching or propagation.
- Joint Framework Methods: Integrating segmentation and tracking in unified models using graph-based or probabilistic frameworks.
(Figure 3 provides a schematic of the bottom-up based framework.)
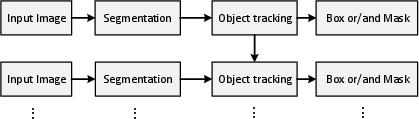
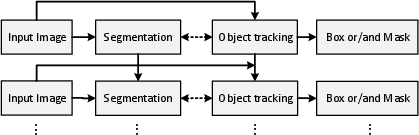
Figure 3: Bottom-up based framework.
Dataset and Metrics
The evaluation of VOS and VOT methods relies on datasets like DAVIS, YouTube-VOS, and SegTrack, which provide diverse annotated video sequences. Metrics focus on region similarity, contour precision, temporal stability, and bounding box overlap for accurate comparison of segmentation and tracking performance.
Future Directions
Key areas for future research include:
- Simultaneous Prediction: Improvements in speed and accuracy for methods predicting both object masks and position.
- Fine-grained Segmentation: Enhanced handling of high-definition videos with small or detailed objects.
- Generalization: Robust methods that adapt to varied environments and object classes.
- Multi-camera Integration: Challenges and techniques for video analysis from multiple viewpoints.
- 3D Segmentation and Tracking: Applications in autonomous driving and infrastructure modeling that require precise 3D object analysis.
Conclusion
The survey presents a comprehensive analysis of the methodologies and progress in video object segmentation and tracking. They are categorized based on application scenarios, offering insights into dealing with complex video data. These techniques remain critical for advancing video analysis capabilities in dynamic and real-world environments.