- The paper introduces Poly-encoders, a novel hybrid transformer architecture that blends the strengths of Bi- and Cross-encoders for efficient multi-sentence scoring.
- It employs domain-specific pre-training, notably on Reddit data, to improve performance on dialogue and information retrieval tasks.
- Experimental results show that Poly-encoders maintain competitive accuracy while significantly reducing inference time compared to Cross-encoders.
Introduction
This paper explores the transformer-based architectures designed to efficiently handle multi-sentence scoring tasks, which involve matching an input context with a corresponding label. It addresses the trade-off between prediction quality and speed. The study introduces Poly-encoders, which balance the performance of Cross-encoders and the efficiency of Bi-encoders, both common techniques for sequence comparison tasks. The results demonstrate that Poly-encoders offer state-of-the-art performance across various datasets while achieving significant speed gains.
Model Architectures
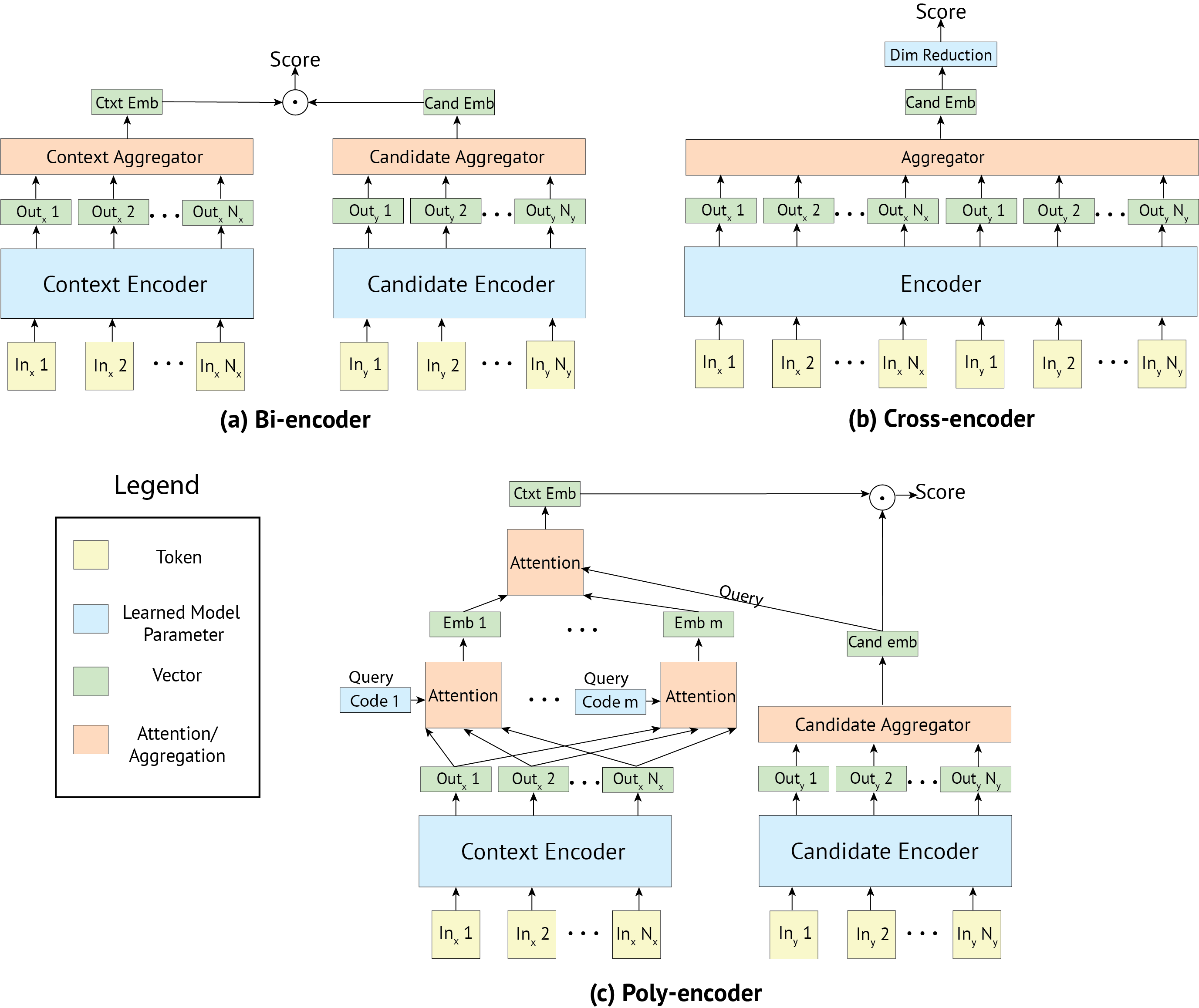
The study evaluates three key architectures: Bi-encoders, Cross-encoders, and the newly proposed Poly-encoders.
Pre-training and Fine-tuning Strategies
The paper discusses the significance of pre-training on datasets closely related to the target domain tasks to enhance performance. Besides replicating the BERT training on Wikipedia and BooksCorpus, a domain-specific pre-training on Reddit data was performed, aiming at dialogue tasks to test the effectiveness of contextually similar data.
- Pre-training on Reddit: Demonstrated improved performance across dialogue tasks, surpassing results obtained through traditional BERT pre-training. This strategy underscores the value of domain-specific data in achieving practical performance gains.
Experimental Results
The proposed architectures and training strategies were evaluated on four tasks: ConvAI2, DSTC7, Ubuntu V2, and Wikipedia Article Search. The Poly-encoder architecture consistently outperformed Bi-encoders while offering a significant speed advantage over Cross-encoders.
- ConvAI2 Test Results: Poly-encoders achieved higher R@1 scores than Bi-encoders and closely rivaled Cross-encoders.
- DSTC7 and Ubuntu V2: The Poly-encoders, especially with Reddit pre-training, set new benchmarks, suggesting effective balance in speed and accuracy.
Inference Speed and Practical Implementation
The inference speed of Poly-encoders aligns more closely with Bi-encoders, making them suitable for real-world applications where rapid evaluation is critical. The ability to cache candidate representations allows for scalable deployment scenarios with large candidate pools, a significant advantage over Cross-encoders.
Conclusion
The introduction of Poly-encoders provides a viable solution for tasks requiring efficient multi-sentence scoring without compromising on performance. By leveraging domain-specific pre-training and a balanced architecture, it represents an advancement in transformer utilization for practical AI applications. The results suggest that task-specific data can substantially improve model performance, stressing the significance of data selection in pre-training phases. These findings could inform future developments and implementations in areas requiring quick and accurate candidate scoring mechanisms.