- The paper introduces a learning-based framework for predicting optimal rigid transformations that align point clouds, significantly improving upon ICP.
- It utilizes a feature embedding network with an attention-based module and a differentiable SVD layer to compute registrations with lower error rates.
- Experimental results on ModelNet40 demonstrate DCP's robustness to noise and its ability to generalize to unseen data.
Deep Closest Point: Learning Representations for Point Cloud Registration
The paper "Deep Closest Point: Learning Representations for Point Cloud Registration" (1905.03304) presents a novel approach to the problem of point cloud registration. The proposed method, Deep Closest Point (DCP), leverages advancements in deep learning to effectively align point clouds by predicting a rigid transformation. DCP aims to overcome the limitations of traditional methods like Iterative Closest Point (ICP), which often suffer from convergence to local optima.
Motivation and Background
Point cloud registration is a fundamental task in computer vision applications like robotics and medical imaging. The task involves finding the rigid transformation that best aligns one point cloud with another. Traditional methods such as ICP rely on iterative optimization, which is prone to local optima due to the non-convex nature of the problem. To address these issues, the authors introduce a learning-based framework that integrates insights from recent developments in computer vision and natural language processing.
Methodology
Architecture Overview
The DCP model consists of three main components:
- Feature Embedding Network: The input point clouds are embedded into a high-dimensional space using networks like PointNet or DGCNN, which generate permutation-invariant and rigid-invariant representations.
- Attention-Based Module with Pointer Generation: An attention mechanism, inspired by Transformers, facilitates the matching between points of the two clouds. This module outputs a soft matching between points, approximating a combinatorial matching.
- Differentiable SVD Layer: The final rigid transformation is computed using a differentiable singular value decomposition (SVD) layer, which extracts the optimal transformation aligning the two point clouds.
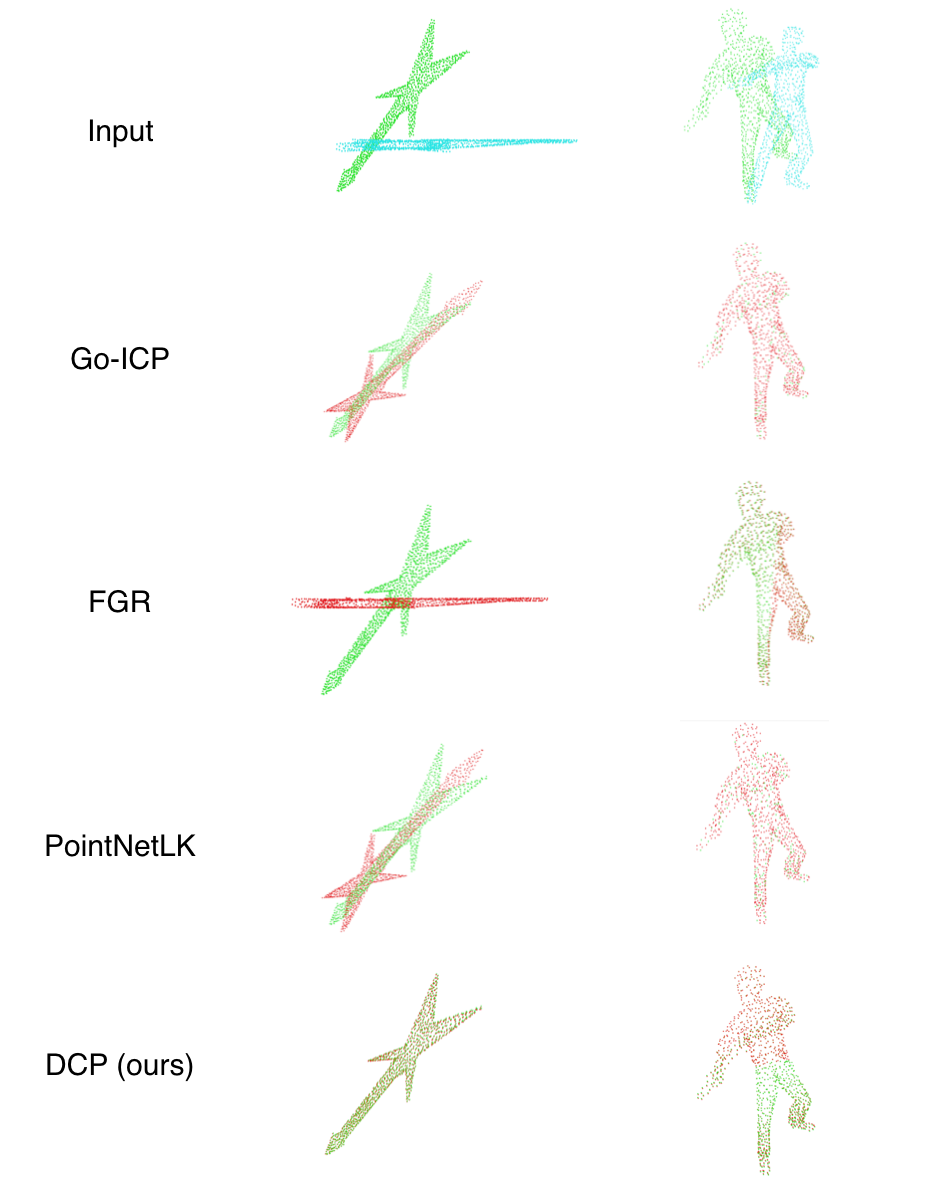
Figure 1: Left: a moved guitar. Right: rotated human. All methods work well with small transformation. However, only our method achieve satisfying alignment for objects with sharp features and large transformation.
Training and Loss Function
The model is trained end-to-end on the ModelNet40 dataset, optimizing a loss function that measures the deviation of predicted transformations from ground truth. The loss function includes terms for both rotation and translation errors, along with a regularization term to prevent overfitting.
Experimental Results
The experiments demonstrate that DCP outperforms traditional ICP and its variants, as well as recent learning-based methods like PointNetLK. DCP achieves lower mean squared error (MSE) and mean absolute error (MAE) in both rotation and translation across various datasets, highlighting its robustness and efficiency.
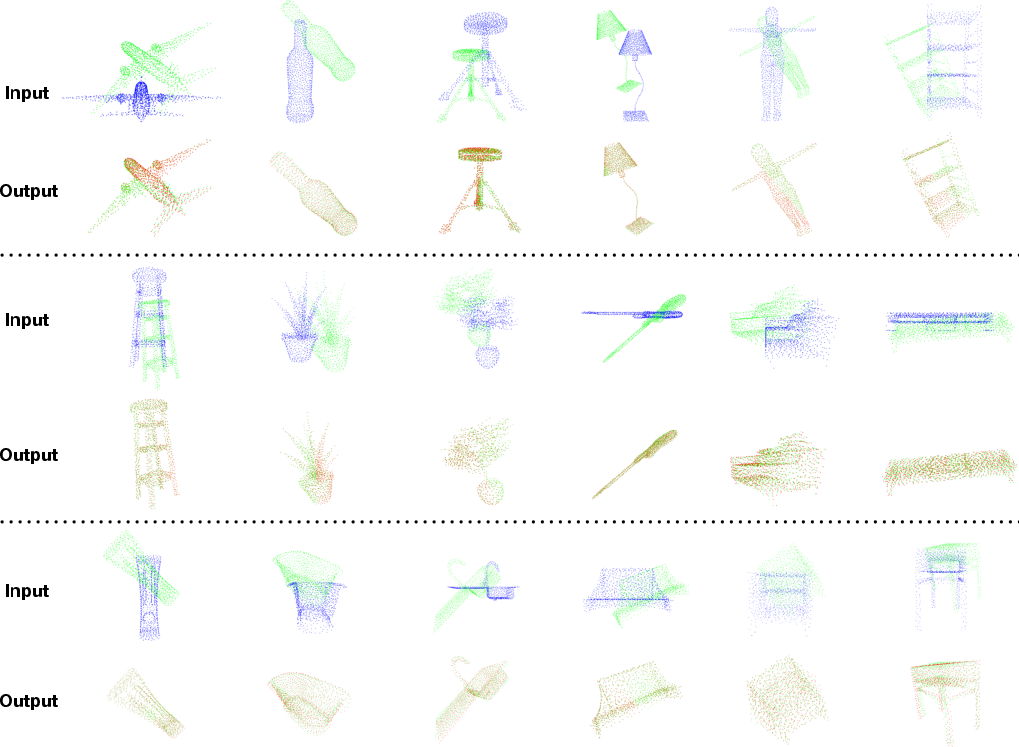
Figure 2: Results of DCP-v2. Top: inputs. Bottom: outputs of DCP-v2.
Generalization and Robustness
DCP's learned features generalize well to unseen data, suggesting that the model captures salient geometric features crucial for registration. Moreover, DCP exhibits resilience to Gaussian noise, preserving alignment accuracy even with perturbed input data.
Implementation Considerations
When implementing DCP, computational efficiency is a critical consideration. The model benefits from deep learning frameworks like PyTorch or TensorFlow, which support automatic differentiation required by the SVD layer. Additionally, the model's ability to provide a good initial guess for ICP means it can also be utilized to improve traditional ICP outcomes by serving as a robust initializer.
Conclusion
The Deep Closest Point method presents a significant advancement in point cloud registration by integrating deep learning techniques with classical geometric principles. Its performance in terms of accuracy and robustness makes it a compelling alternative to traditional methods. Future research could explore the adaptation of DCP for related tasks, such as 3D object detection and pose estimation, potentially broadening its applications in real-world systems.