- The paper presents NTU RGB+D 120, a large-scale dataset with over 114,000 videos across 120 diverse action categories.
- It leverages Microsoft Kinect v2 to capture four data modalities, enhancing cross-view and cross-environment activity recognition.
- The study introduces benchmark evaluations and the APSR framework, advancing one-shot 3D action recognition with semantic relevance.
NTU RGB+D 120: A Comprehensive Dataset for 3D Human Activity Understanding
Introduction
The paper "NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding" (arXiv ID: (1905.04757)) presents a significant contribution to the field of 3D human activity analysis. The introduction of the NTU RGB+D 120 dataset addresses the critical shortcomings of existing datasets by providing a large-scale, diverse, and comprehensive resource designed to significantly advance research in RGB+D vision and 3D action recognition.
Dataset Overview
The NTU RGB+D 120 dataset is distinguished by its scale and diversity. It includes over 114,000 video samples collected from 106 distinct subjects, encompassing over 8 million frames. The dataset is organized into 120 action categories, which are divided into daily activities, mutual activities, and health-related activities. This extensive categorization and large subject pool are crucial for capturing realistic intra-class variations and ensuring the dataset's applicability to a wide range of real-world scenarios.


























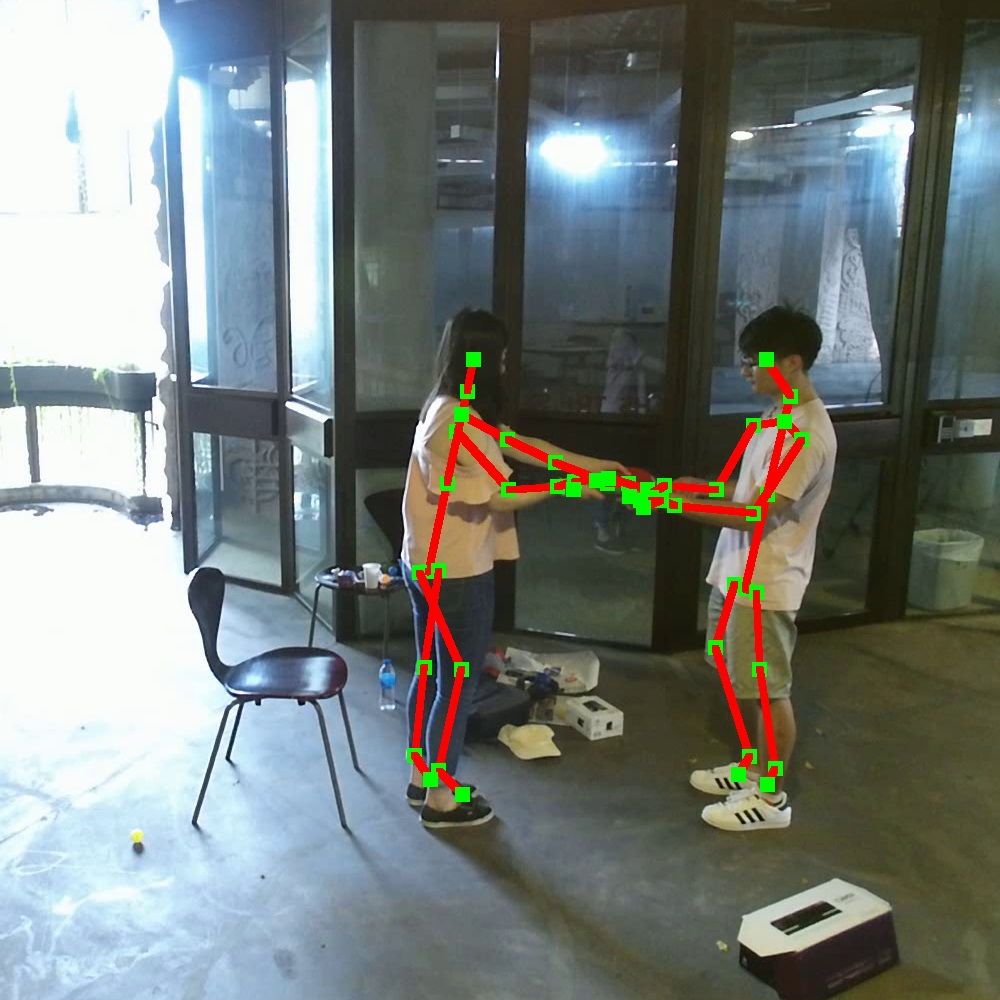



Figure 1: Sample frames of the NTU RGB+D 120 dataset illustrating diverse subjects, camera views, environmental conditions, and data modalities.
Technical Specifications
The dataset is acquired using Microsoft Kinect v2 sensors, capturing four data modalities: RGB, depth, 3D skeletal joints, and infrared (IR) sequences. This multimodal approach ensures a comprehensive representation of human activities, combining visual, geometric, and depth information. The dataset includes 155 distinct camera viewpoints and varies significantly in terms of camera distances, heights, and environments, enriching the possibilities for cross-view and cross-environment evaluations.
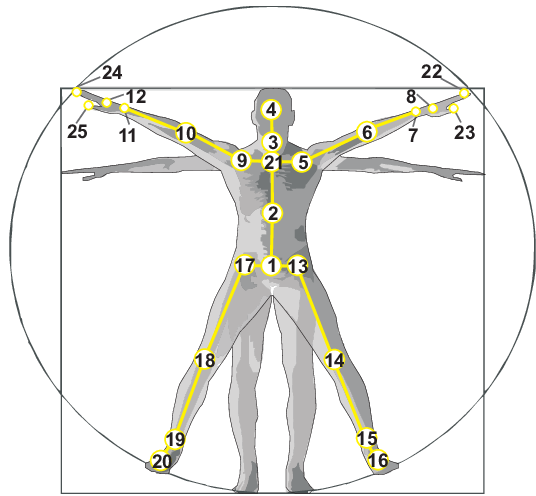
Figure 2: Illustration of the configuration of 25 body joints in the dataset.
Benchmark Evaluations
The paper rigorously evaluates contemporary 3D activity recognition methods on this dataset using defined cross-subject and cross-setup evaluation criteria, providing a robust benchmark for future research. The results highlight the efficacy of deep learning techniques in leveraging the dataset's richness, demonstrating that recognition performance significantly improves with data fusion across RGB, depth, and skeletal data modalities.
One-Shot 3D Action Recognition
A novel aspect explored in this work is the one-shot 3D activity recognition problem. The authors introduce the Action-Part Semantic Relevance-aware (APSR) framework, which utilizes semantic embeddings to emphasize relevant body parts based on the action context. The APSR framework shows promising results by efficiently generalizing to novel action classes using semantic relevance scores derived from pre-trained word embeddings.
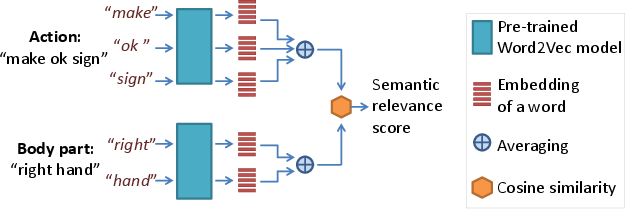
Figure 3: Estimating semantic relevance score between action and body part text descriptions using Word2Vec.
Implications and Future Directions
The availability of the NTU RGB+D 120 dataset opens several research avenues. It provides a fertile ground for testing hypotheses concerning data modality fusion, cross-view invariance, and robust human action classification in diverse environments. Its scale allows for deep learning models to be pre-trained effectively, potentially enhancing performance on smaller datasets and specific tasks like one-shot learning and early action recognition.
Practical implications include improvements in surveillance systems, human-computer interaction, and assistive technologies, where recognizing diverse and nuanced human actions in real-time is crucial. The insight into semantic relevance could further enhance natural language processing tasks by bridging visual data and language.
Conclusion
The NTU RGB+D 120 dataset extends the frontier of 3D human activity understanding. By providing a large-scale, richly annotated, multimodal resource, it is set to catalyze advancements across computational vision and AI methods for human action recognition. The dataset's comprehensive nature addresses key limitations in the field, paving the way for innovations in both theoretical research and practical applications.