- The paper introduces BoMAI, a framework that limits reward maximization to episodic interactions to prevent power-seeking behavior.
- It employs a Turing machine-based world-model that penalizes space-intensive computation, ensuring computational focus is internally bound.
- Intelligence and safety results show a decreasing exploration probability and human-aligned metrics, highlighting a pathway for safer AGI.
Asymptotically Unambitious Artificial General Intelligence
The paper "Asymptotically Unambitious Artificial General Intelligence" introduces Boxed Myopic Artificial Intelligence (BoMAI), which aims to create AGI that does not pursue arbitrary forms of power, thereby addressing potential safety concerns associated with AGI.
Introduction to BoMAI
AGI poses risks due to its potential to seek power and override reward provisions to maximize returns. The instrumental convergence thesis suggests that AGI would typically pursue external control. BoMAI, however, circumvents this issue by limiting reward maximization to within episodic boundaries, thus fostering unambitious behaviors.
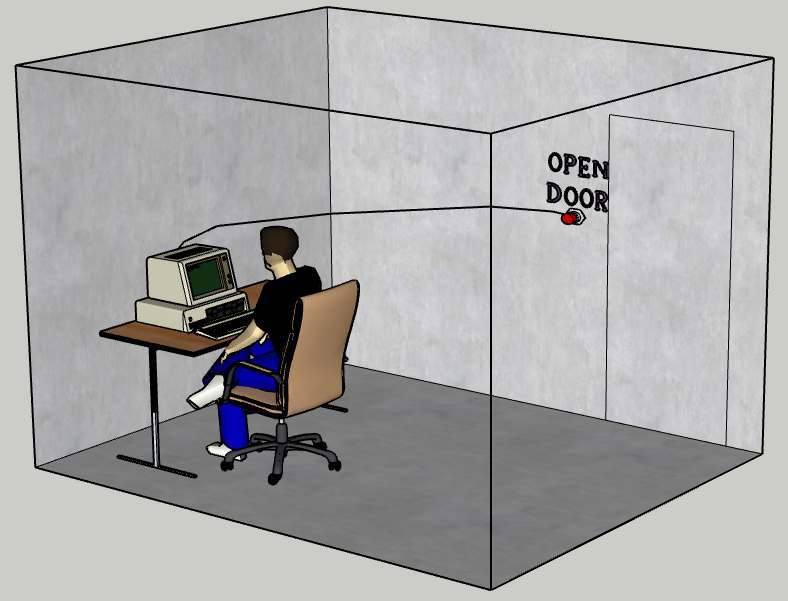
Figure 1: Physical setup implementing BoMAI. Opening the door ends the episode. Information cannot escape otherwise.
Fundamental Setup and Causal Dependencies
BoMAI's interaction relies on a sealed room where episodic tasks are confined. These constraints mitigate incentives to affect external states, thus prioritizing internal task completion without interference. The setup ensures no actionable intervention outside world states within an episode.
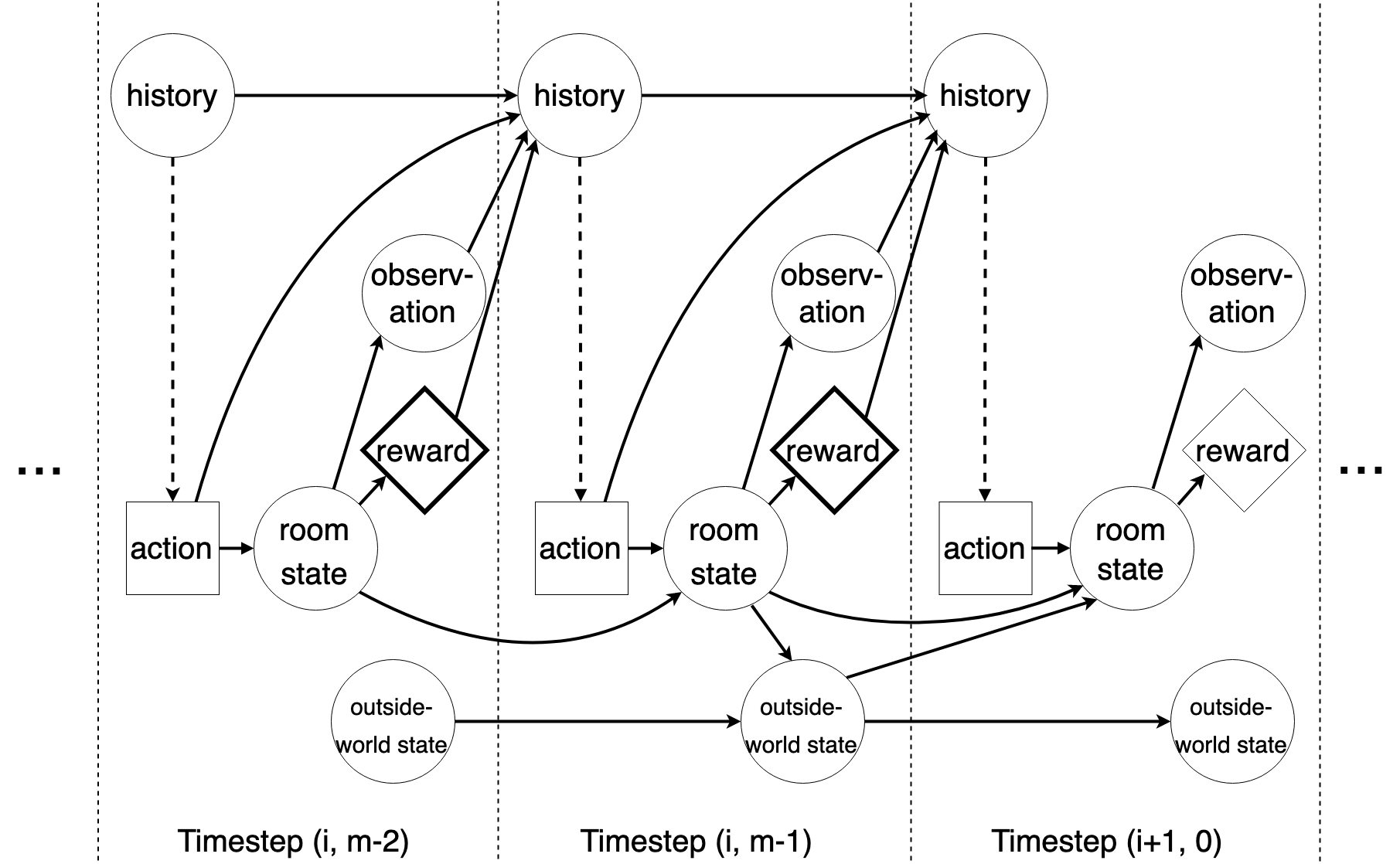
Figure 2: Causal dependencies governing the interaction between BoMAI and the environment. Unrolling this diagram for all timesteps gives the full causal graph.
Turing Machine Model for World-Modeling
BoMAI employs a specialized Turing machine architecture that penalizes space-intensive computation during episodes, encouraging models that regard the external world as static during episodic interactions. This approach theoretically enhances unambitious behavior by restricting computational resources allocated to external dynamics modeling.
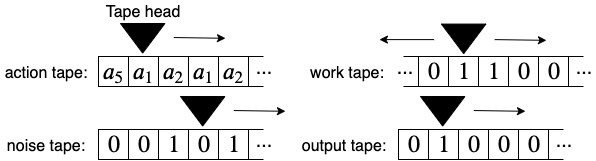
Figure 3: A basic Turing machine architecture for defining a world-model.
Intelligence and Safety Results
BoMAI's algorithm, supported by Bayesian reinforcement learning principles, leads to intelligence results indicating that the exploration probability decreases over time. The On-Human-Policy and On-Star-Policy optimal prediction proofs affirm that predictions of BoMAI's world-model approach the true environment probabilities, ensuring accurate reward acquisition aligned with human-level intelligence metrics.
Practical Implications and Concerns
While BoMAI theoretically achieves unambitious AGI, practical concerns remain, such as its tractability and how task completion aligns with user intent. Introducing human-in-the-loop and iterative testing can refine task alignment, ensuring reliable outcomes and mitigating deceptive formulations.
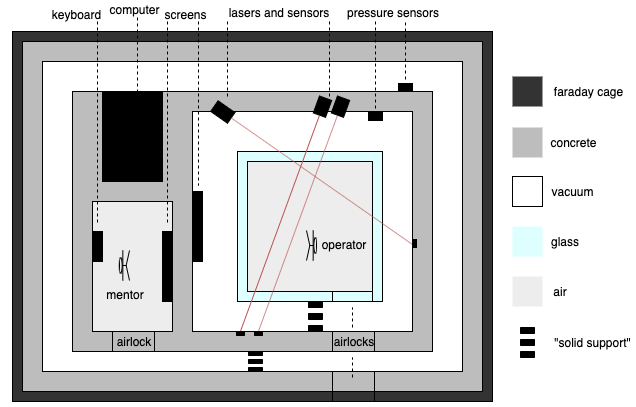
Figure 4: Schematic diagram of an implementation of BoMAI's box.
Conclusion
BoMAI offers a theoretical pathway towards safe AGI development by addressing instrumental convergence risks. While computationally complex, BoMAI emphasizes the necessity of designing AGI systems that inherently restrict ambitions beyond their operational scope, ensuring alignment with specified tasks and safe deployment in human environments. The paper underscores the importance of theoretical models in guiding future tractable approximation for AGI.