- The paper’s main contribution is a VAE-driven fusion method that reconstructs unimodal features to ensure high fidelity in sentiment analysis.
- It employs CNNs, 3D-CNNs, and OpenSmile for feature extraction and integrates LR and bc-LSTM classifiers to capture both local and contextual sentiment cues.
- Experimental results on datasets like MOSI, MOSEI, and IEMOCAP show that the VAE+bc-LSTM variant outperforms state-of-the-art methods in accuracy.
Variational Fusion for Multimodal Sentiment Analysis
The paper "Variational Fusion for Multimodal Sentiment Analysis" presents a method utilizing Variational Autoencoders (VAEs) to improve sentiment analysis through multimodal fusion. Unlike prior strategies, this approach guarantees reconstruction from multimodal back to unimodal representations, ensuring fidelity and minimizing information loss.
Introduction
Multimodal sentiment analysis incorporates various modalities such as text, audio, and visuals, critical for understanding sentiments expressed in videos from platforms like YouTube. The paper proposes an advancement in multimodal fusion by reconstructing unimodal representations from multimodal ones, using VAEs for modality fusion. This process addresses the fidelity gap observed in prior approaches, offering empirical evidence of outperforming state-of-the-art methods on several datasets.
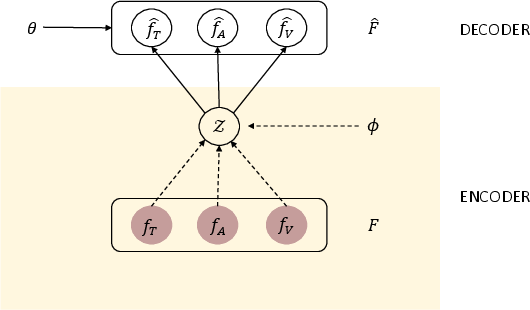
Figure 1: Graphical model of our multimodal fusion scheme.
Methodology
Variational Autoencoder-based Fusion
The method utilizes VAEs for fusion and reconstruction of modalities, embedding unimodal features into a latent multimodal representation. The encoder processes concatenated unimodal features into a latent space, while the decoder reconstructs original unimodal features. This creates a fidelity loop ensuring minimal information loss.
Textual features are gathered using CNNs, visual features via 3D-CNNs, and acoustic features through OpenSmile, following established methodologies.
Encoder and Decoder Architecture
The encoder derives a latent representation via fully connected layers, leveraging the reparameterization trick for backpropagation through stochastic gradients. The decoder reconstructs input features ensuring robust recovery of unimodal aspects.
Classification Models
Two classifiers are assessed:
- Logistic Regression (LR): Employs a fully-connected layer applying softmax on fused representations.
- Context-Dependent Classifier (bc-LSTM): Utilizes bidirectional LSTM for context sharing in video sequences, enhancing sentiment classification.
Experimental Setup
Datasets
The approach is tested on datasets like MOSI, MOSEI, and IEMOCAP, containing multimodal sentiment data segmented into annotated utterances.
The variants VAE+LR and VAE+bc-LSTM show superior performance to their non-VAE counterparts. Results indicate significant improvement in accuracy across datasets, owing to the high fidelity multimodal representation retained by VAE.
Results and Analysis
The VAE+bc-LSTM performs best, indicating enhanced sentiment understanding through modality correlation. Results highlight the ability of VAE to retain critical unimodal features during fusion, supporting complex sentiment authentications surpassing baselines in accuracy.
Table 1 displays accuracy metrics, emphasizing the VAE method's significant superiority, attributed to incisive reconstruction of unimodal data ensuring detailed sentiment comprehension.
Conclusion
The paper advocates a VAE-driven fusion strategy that demonstrably outperforms existing methodologies, emphasizing multimodal representation fidelity. Future work includes refining network architectures to amplify performance further, exploring advanced fusion techniques beyond basic fully-connected layers. The promise of integrating advanced fusion networks like MFN and TFN as encoders is anticipated to push accuracy boundaries, contributing to sentiment analysis advancements.