- The paper introduces DeepSketchHair, a framework that generates 3D hair models from user-drawn 2D sketches using a three-stage neural network pipeline.
- It employs GAN-based and hybrid 2D/3D convolution architectures (S2ONet, O2VNet, and V2VNet) to transform sketches into detailed volumetric hair representations.
- Quantitative and qualitative evaluations demonstrate its superior performance in synthesizing realistic and diverse hairstyles with high user interaction flexibility.
DeepSketchHair: Deep Sketch-based 3D Hair Modeling
This essay presents an in-depth analysis of the paper "DeepSketchHair: Deep Sketch-based 3D Hair Modeling" by Yuefan Shen, Changgeng Zhang, Hongbo Fu, Kun Zhou, and Youyi Zheng (1908.07198). The paper introduces DeepSketchHair, an innovative framework for interactive modeling of 3D hair from 2D sketches. This framework leverages deep learning to overcome the inherent challenges of geometric complexity and variability in hair modeling.
Framework Overview
DeepSketchHair is designed to generate 3D hair models by converting user-drawn 2D sketches into volumetric hair models. The system utilizes three neural networks: S2ONet, O2VNet, and V2VNet. S2ONet translates 2D sketches into dense 2D orientation fields, O2VNet transforms these orientation fields into 3D vector fields, and V2VNet facilitates multi-view hair editing by updating the 3D vector field in response to new sketches.
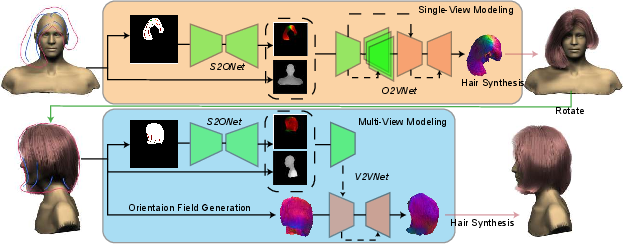
Figure 1: The pipeline of our DeepSketchHair framework. The single-view modeling module (top row) takes as input a user-drawn sketch on top of a bust model, and generates a hair strand model from a synthesized 3D orientation field.
Key Components
S2ONet
S2ONet employs a GAN-based architecture to map a 2D sketch into a dense 2D orientation field. This network effectively bridges the gap between sparse sketch inputs and the detailed volumetric information needed for hair modeling. It utilizes a WGAN-GP framework to ensure stable training and employs content and style losses to improve the quality of the generated orientation fields.
O2VNet
O2VNet extends the capabilities of S2ONet by mapping the 2D orientation field into a 3D vector field, essential for strand-level 3D hair synthesis. It incorporates projection and Laplacian losses to maintain alignment with input sketches and encourage smooth output fields. This network is crucial for providing a volumetric representation of hair, allowing for high-quality synthesis of strand-level details.
V2VNet
V2VNet addresses multi-view modeling by updating the 3D vector fields based on additional sketches from different views. Unlike other methods that rely solely on 2D convolutions, V2VNet utilizes a hybrid 2D/3D convolutional architecture, allowing it to retain geometrical features from previous views while incorporating new information.

Figure 2: From left to right: the sketch map generated by rendering randomly selected hair strands, the corresponding ground-truth 2D orientation map, and the sketch map generated with our image tracing method.
DeepSketchHair demonstrates superior performance in both qualitative and quantitative assessments. It excels in generating realistic and diverse hairstyles, accommodating user inputs for intricate designs. The framework outperforms existing methods in both resolution and user interaction flexibility. Comparisons with image-based and traditional sketch-based hair modeling techniques reveal that DeepSketchHair produces more coherent and visually appealing results.

Figure 3: Comparisons of our method with single-view image-based hair modeling methods.
Experimental Validation
The system has been validated through comprehensive experiments, including qualitative comparisons and user studies. Results indicate that DeepSketchHair can model complex hairstyles from minimal user input. The framework's ability to handle cartoon-style and highly variable hairstyles underscores its versatility.
Limitations and Future Work
Despite its strengths, DeepSketchHair faces challenges in representing extremely fine details due to resolution constraints in its volumetric representation. Future work may focus on integrating higher resolution vector fields or exploring alternative neural network architectures to enhance detail fidelity. Additionally, expanding the hairstyle database could further improve the network's ability to generalize and produce accurate models for a wider range of hairstyles.
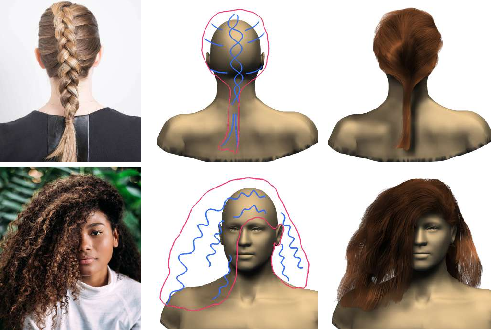
Figure 4: Our method might fail to synthesize hair details due to either insufficient resolution of 2D or 3D orientation fields, or insufficient training data.
Conclusion
DeepSketchHair represents a significant advancement in the domain of 3D hair modeling, driven by deep learning techniques. Its innovative approach to converting 2D sketches into detailed 3D hair models offers a flexible and efficient tool for artists and developers in digital content creation. The framework's potential expansion into VR and real-time applications could further redefine interactive modeling paradigms in computer graphics.