- The paper introduces a GPU-optimized ORCA model that significantly outperforms multi-core CPU simulations for crowds exceeding 100,000 agents.
- It employs a specialized batch linear programming solver and a spatial partitioning scheme to balance workload and reduce communication overhead.
- Experimental results confirm near real-time performance at 30 FPS with realistic crowd behaviors, despite limitations imposed by GPU memory capacity.
GPU-Optimized Crowd Simulation Using ORCA
This paper introduces a GPU-optimized implementation of the Optimal Reciprocal Collision Avoidance (ORCA) model for simulating large-scale crowd dynamics. By parallelizing computations and communication on the GPU, the authors achieve significant performance improvements compared to multi-core CPU implementations, enabling real-time simulations of crowds exceeding 100,000 agents. The key innovations include a specialized linear program solver tailored for GPU architecture and a spatial partitioning scheme for efficient information sharing between agents.
The paper contrasts continuum and microscopic models for crowd simulation. Continuum models offer fast simulation of large crowds but lack individual-level accuracy, while microscopic models define rules at the individual level, allowing for non-homogeneous agents and behaviors. Popular microscopic models include cellular automata (CA), social forces, and velocity obstacles (VO). The authors note that while CA models can reproduce certain phenomena, their discrete space and sequential agent movements limit parallelism and GPU implementation. Social forces models are computationally lightweight and suitable for GPU parallelization, but they can produce unrealistic motion at high densities. VO models, which compute collision-free trajectories based on the velocity and position of nearby objects, are well-suited for GPU implementation due to their parallel nature. ORCA, an extension of VO, provides sufficient conditions for collision-free motion by solving low-dimension linear programs.
Algorithm Implementation
The GPU-optimized ORCA implementation builds upon the multi-core CPU version, incorporating key changes for efficient GPU execution. The core of the algorithm involves each agent observing nearby agents, calculating half-planes of restricted velocities based on their properties (radius, position, velocity), and selecting a velocity that avoids collisions within a lookahead time τ. This velocity selection is formulated as a linear programming problem, solved using a batch-GPU-LP algorithm [charlton_two-dimensional_2019] designed for solving multiple low-dimensional linear programs on the GPU.
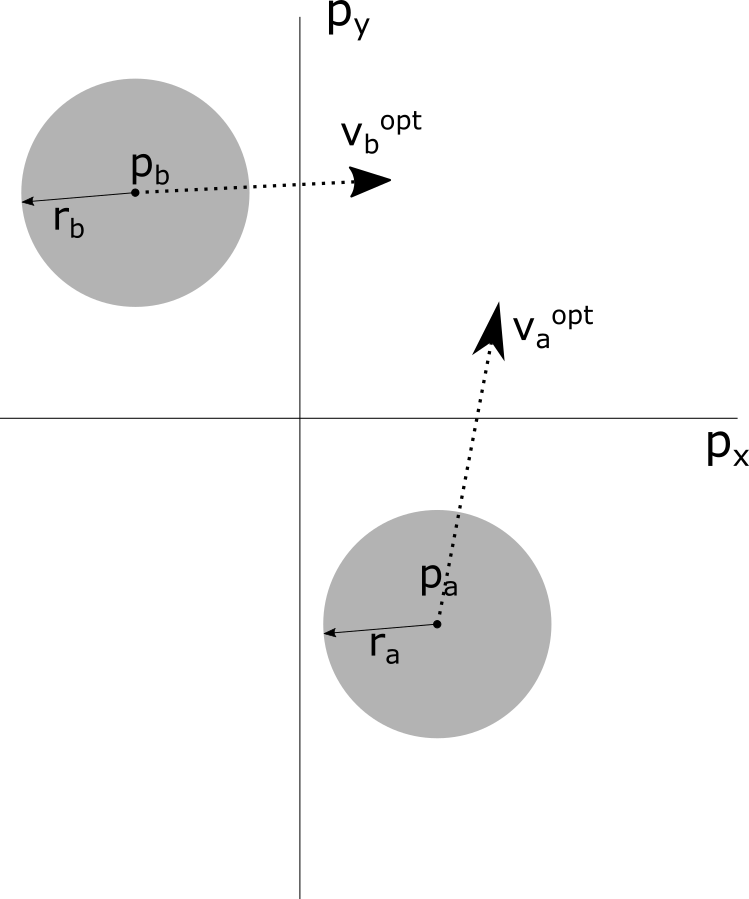
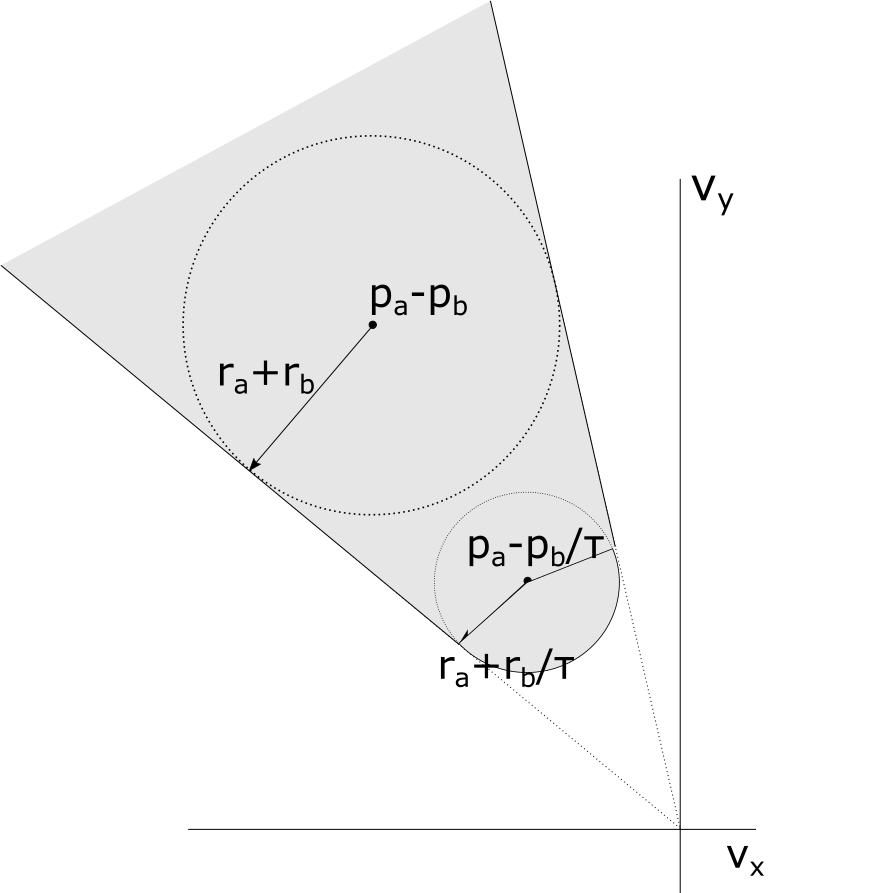
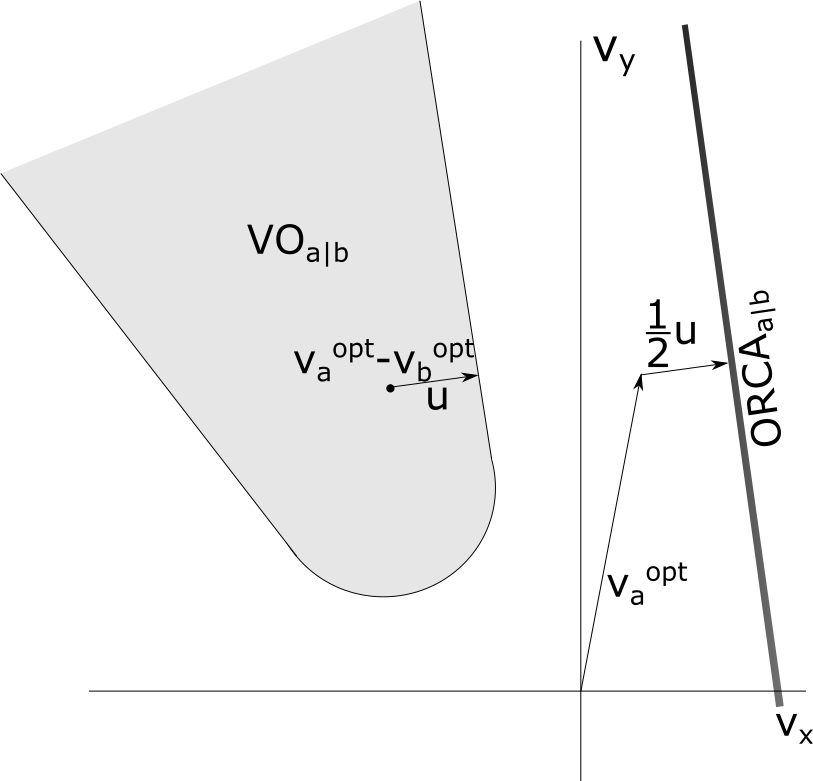
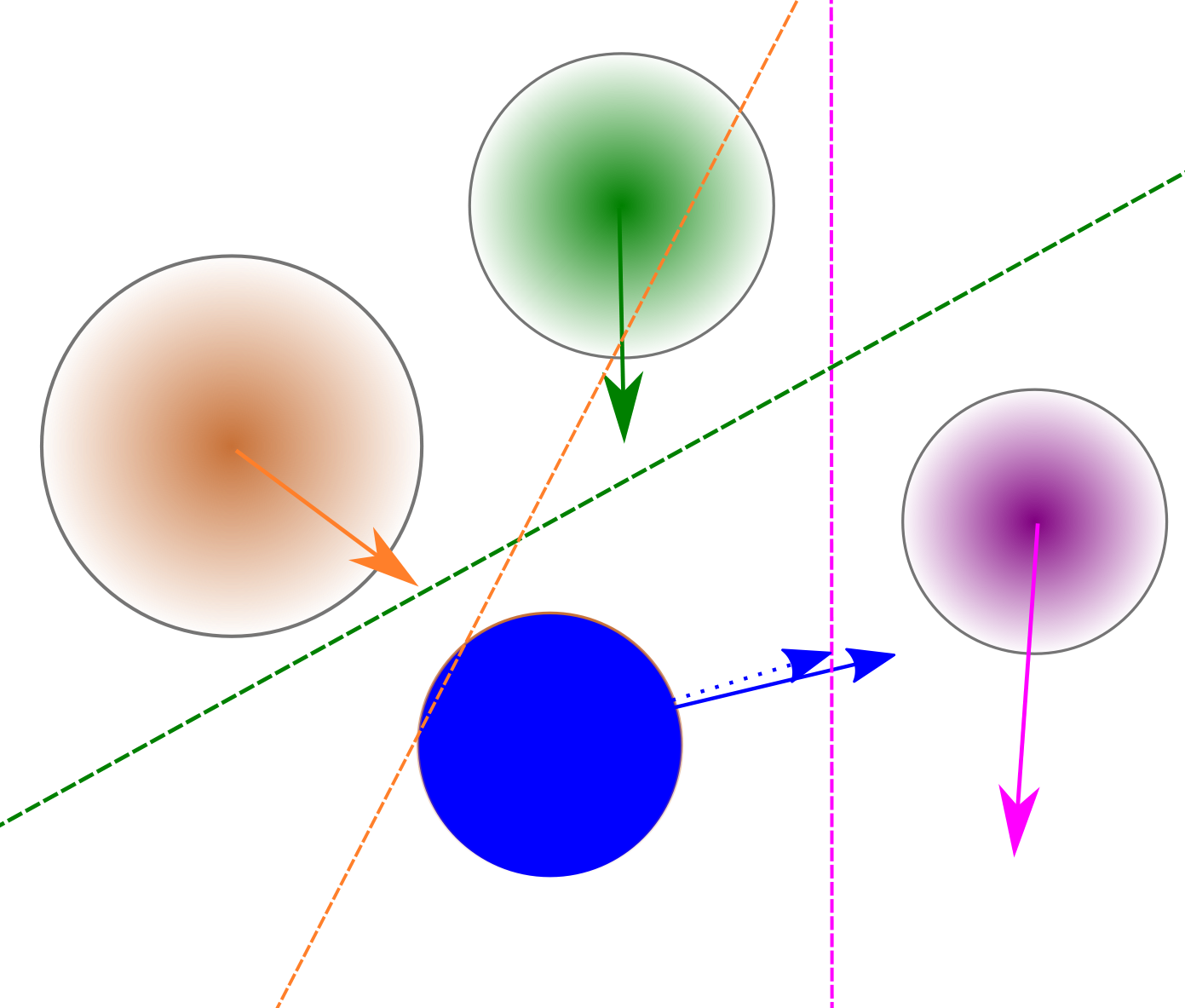
Figure 1: A system of 2 people a and b with corresponding radius ra and rb. (b) The associated velocity obstacle VOa∣b in velocity space for a look-ahead period of time τ caused by the neighbor b for a. (c) The vector of velocities vaopt−vaopt lies within the velocity obstacle VOa∣b. The vector u is the shortest vector to the edge of the obstacle from the vector of velocities. The corresponding half-plane ORCAa∣b is in the direction of u, and intersects the point vaopt+u. (d) A view of a blue agent and its neighbors, as well as the generated half-planes caused by the neighbors interacting with the blue agent. The solid blue arrow shows the desired velocity of the blue agent. The dotted blue arrow is the resulting calculated velocity that does not collide with any neighbor in time τ.
The batch-LP solver assigns each thread to a pedestrian and incrementally considers half-plane constraints. To address the unbalanced workload caused by branching calculations, the implementation uses ideas from cooperative thread arrays [wang_gunrock_2016] to subdivide calculations into "work units," enabling a more balanced workload and improved performance.
Efficient communication between agents is achieved using a spatial partitioning scheme inspired by the FLAME GPU framework [richmond_flame_2011]. Agents create messages containing observable properties, which are organized into spatial bins. Each agent then reads messages from its associated bin and neighboring bins, reducing the communication overhead compared to a brute-force approach.
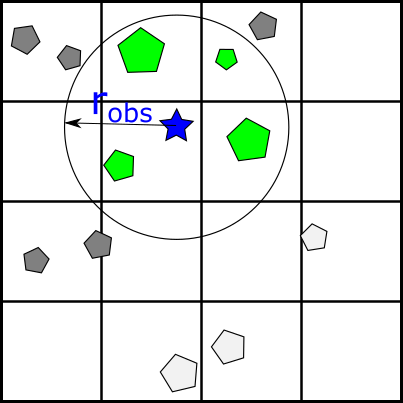
Figure 2: FLAME message partitioning. The simulation is discretized into spatial bins and people save their message to the corresponding bin. For a given person (blue star), it does not read messages of those in non-neighboring bins (white pentagons). For those within the same or neighboring partitioning bins, it calculates whether they are within the observation radius robs.
Experimental Results and Discussion
The paper presents results from two experiments. The first demonstrates the model's behavior in two test cases: a two-way crossing and an eight-way crossing. These scenarios showcase the emergence of realistic crowd behaviors such as lane formation.
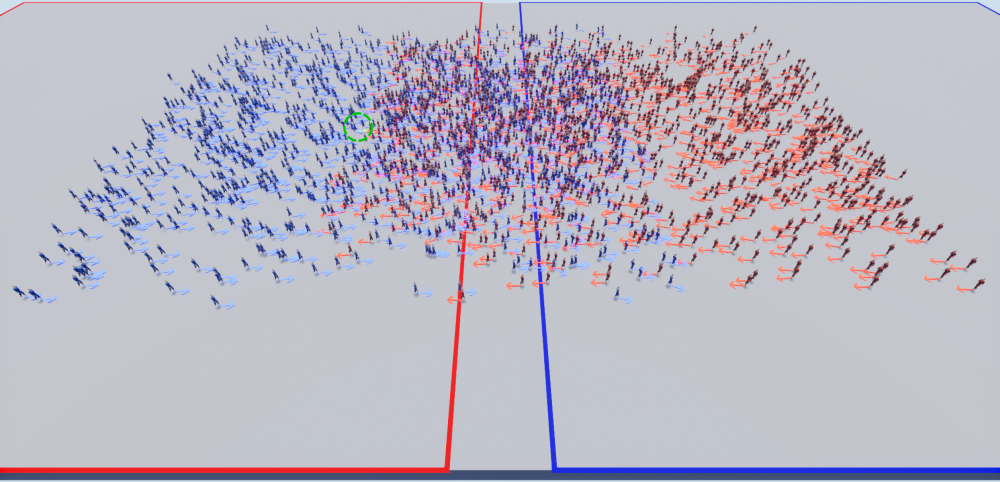

Figure 3: Visualization of 2,500 people in Unreal. Two crowds navigate past each other, one heading from left to right and the other heading from right to left. Left: scene view from above. Colored arrows show the direction of travel. One pedestrian is highlighted with a green circle; Inset: view from the perspective of the pedestrian in the green circle.
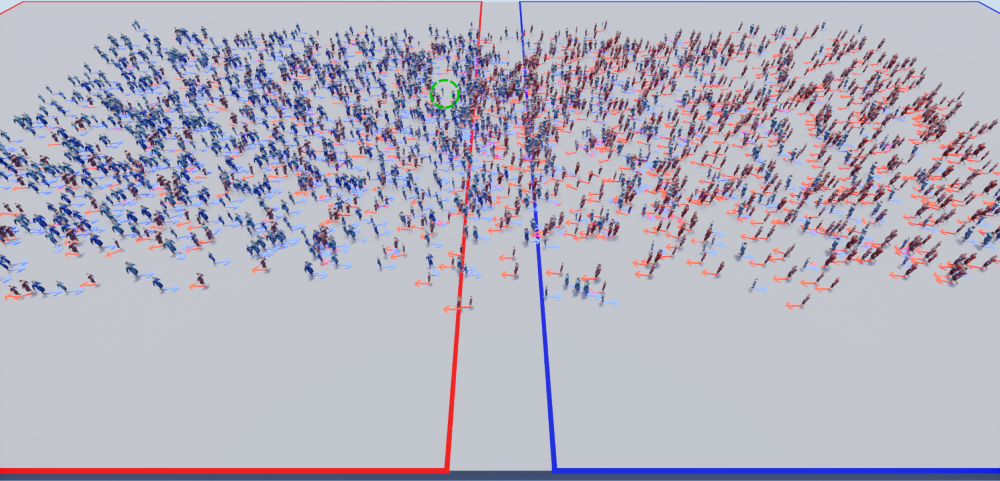

Figure 4: Visualization of 2,500 people in Unreal. Two crowds navigate past each other, one heading from left to right (blue clothes) and the other from right to left (red clothes). People are color coded according to their maximum speeds (using three shades of red or blue, respectively) and have varying radii (indicated by their actual size and also using S, M and L on their tops). Top: scene view from above; One pedestrian is highlighted with a green circle; Inset: view from the perspective of the pedestrian in the green circle.
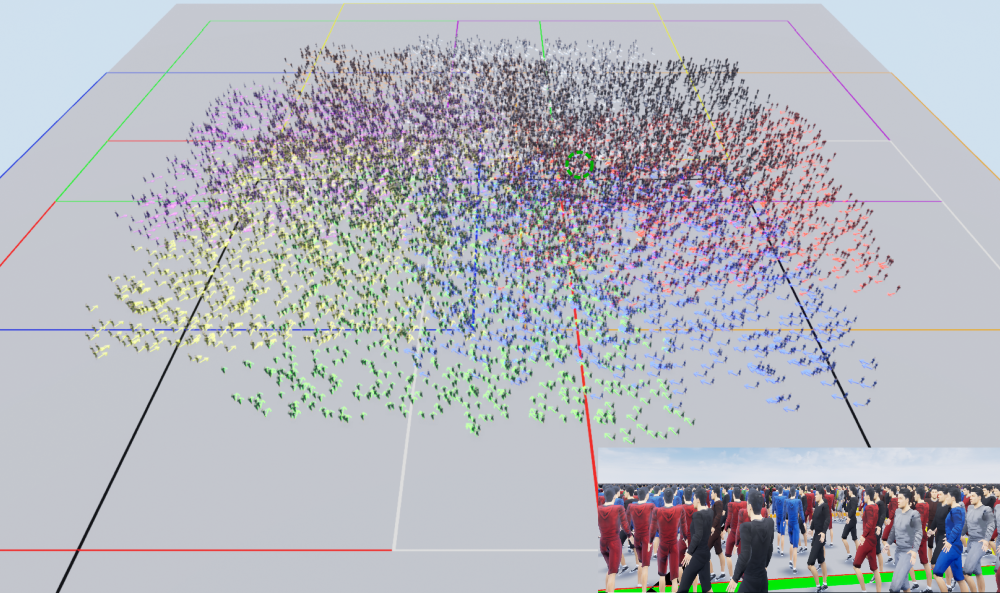
Figure 5: Visualization of 10,000 people in Unreal. Eight crowds attempting to navigate to the opposite end of the environment. Different colors are used for each crowd. Top: scene view from above; One pedestrian is highlighted with a green circle; Inset: view from the perspective of the pedestrian in the green circle.
The second experiment compares the performance of the GPU implementation to a multi-core CPU version, demonstrating speed increases of up to 30 times for the GPU model. The GPU simulation achieved near real-time performance (approximately 30 frames per second) for up to 5×105 agents. The CPU version performed better for smaller numbers of agents, with a crossover point occurring at approximately 2×103 agents.
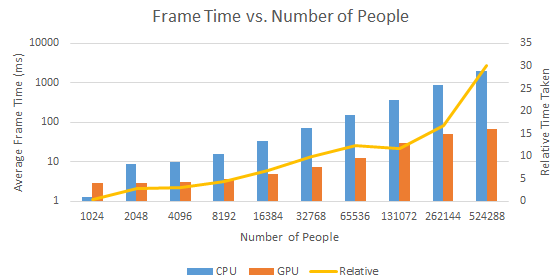
Figure 6: Frame time (in ms) for multi-core CPU and GPU ORCA models with varying numbers of people. Logarithmic scale on primary (left) vertical axis. Relative timing is given on the secondary (right) vertical axis, in linear scale. Simulation time only without visualisation of the pedestrians.
Conclusion and Future Work
The paper concludes by highlighting the substantial performance gains achieved with the GPU-optimized ORCA model for large-scale crowd simulations. The authors note that the current implementation is limited by GPU memory capacity, which could be addressed by considering fewer neighbors or utilizing managed memory techniques [nvidia_tuning_2018] to page information between CPU and GPU. Future work will focus on integrating the simulation directly with the Unreal Engine for real-time visualization and exploring more computationally expensive steering models for increased realism.