- The paper introduces a dynamic termination Bellman equation that allows agents to adaptively choose when to stop options, enhancing coordination across multi-agent tasks.
- The dynamic termination mechanism reduces reliance on centralized controllers, scales effectively by minimizing joint action space complexity, and improves computational efficiency.
- Empirical evaluations on pursuit and taxi tasks demonstrate significant performance improvements over traditional Q-learning and greedy strategies, validating the approach's efficacy.
Multi-agent Hierarchical Reinforcement Learning with Dynamic Termination
Introduction
The paper "Multi-agent Hierarchical Reinforcement Learning with Dynamic Termination" introduces an advanced reinforcement learning framework that addresses the dynamic interactions and challenges inherent in multi-agent systems. By focusing on dynamic termination within a hierarchical reinforcement learning (HRL) framework, the research illuminates how agents can balance flexibility and predictability when executing options over extended time periods.
Problem Statement
The paper tackles the problem of optimizing agent policies in multi-agent systems where each agent's performance is interdependent on the actions of others. Traditional centralized methods suffer from scalability issues due to an exponentially growing joint action space. Conversely, decentralized approaches struggle with inconsistency in agents' behaviors if options, representing subgoals, are altered too frequently.
The key challenge identified is the delayed response to environmental changes due to the fixed-duration nature of options in HRL. This delay may hinder adaptability to dynamic scenarios or changes in other agents' behaviors, an issue exacerbated by premature option switching that reduces predictability.
Dynamic Termination Bellman Equation
The proposed solution introduces a dynamic termination mechanism that allows agents to choose whether to terminate their current options based on both the environment state and the options of other agents. This mechanism is encapsulated in a novel dynamic termination Bellman equation, balancing the benefits of flexibility against those of predictability.
Dynamic Termination Architecture:
The architecture is composed of hierarchical levels where a high-level controller decides the termination of options using a Q-value network enriched with dynamic termination capabilities (Figure 1).
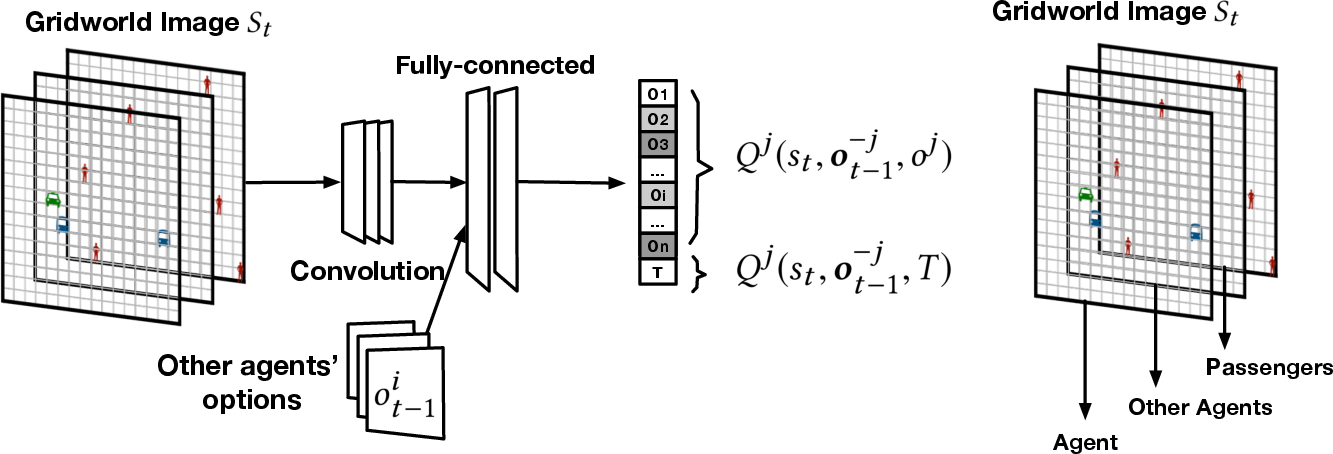
Figure 1: Dynamic termination Q-value network architecture.
This equation introduces an additional termination value, allowing the agents to continuously evaluate the viability of continuing or stopping their current options. By associating a cost δ with termination decision-making, agents are encouraged to weigh the cost of terminating an option against the potential benefits carefully.
Empirical Evaluation
The framework was empirically validated on multi-agent pursuit and taxi coordination tasks. The evaluation framework tested the performance across different setups, focusing on the agents' abilities to adapt to varying environmental conditions. The tasks were configured to examine flexibility (the ability to switch goals or targets) and predictability (commitment to a planned course of action).
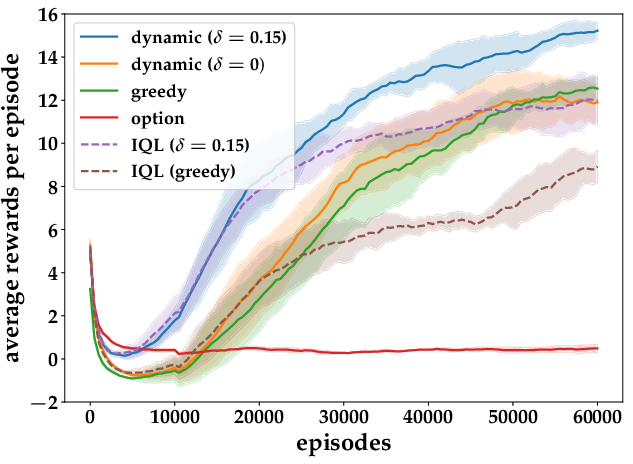
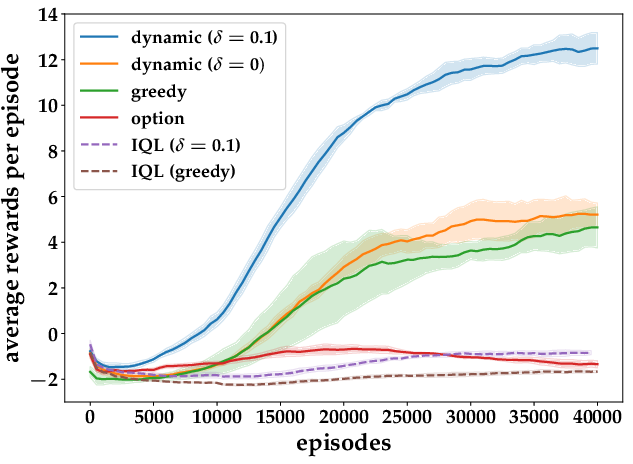
Figure 2: Results from Taxi Pickup and Pursuit Tasks.
Key results from these tasks demonstrated that the dynamic termination model significantly outperforms existing approaches, including independent Q-learning and greedy termination strategies. The perturbational robustness against varying penalty values δ for termination reflects the versatility of the proposed framework.
Technical Implications
The implementation of dynamic termination in hierarchical policy frameworks carries several implications:
- Resource Efficiency: The dynamic termination approach yields computational simplifications by reducing reliance on complex centralized control systems.
- Scalability: By minimizing joint action spaces and leveraging decentralized control mechanisms, the framework scales effectively to larger multi-agent environments.
- Predictability: The ability to project agent behavior through dynamic option evaluation enhances coordination among agents.
Conclusion
The exploration of dynamic termination within multi-agent systems presents a promising direction for advancing the efficacy of reinforcement learning in complex, dynamic environments. By providing a structured approach to adapting option strategies dynamically, the paper paves the way for further applications in fields requiring cooperative multi-agent interactions, such as autonomous traffic management and large-scale fleet operations. Future work will likely explore adaptive mechanisms for setting the termination costs and their impacts on real-world systems.