- The paper demonstrates that reinforcement learning, particularly policy-based methods like PPO and A2C, can optimize traffic control even with partial detection.
- It employs simulations across sparse, medium, and dense traffic scenarios to reveal that policy-based RL outperforms value-based approaches in adaptability.
- The study highlights practical implications for cost-effective urban traffic management, enabling scalable deployments of PD-ITSC without full vehicular detection.
Summary of "Partially Detected Intelligent Traffic Signal Control: Environmental Adaptation"
Introduction
The research paper titled "Partially Detected Intelligent Traffic Signal Control: Environmental Adaptation," focuses on enhancing traffic management systems through Partially Detected Intelligent Traffic Signal Control (PD-ITSC). PD-ITSC aims to optimize traffic signals using limited vehicular detection, relying on Reinforcement Learning (RL) to adapt to dynamically changing environments. Such systems are essential for mitigating traffic congestion cost-effectively, leveraging advancements in communication technologies like IoT.
Reinforcement Learning in Traffic Control
With the rise of Deep Reinforcement Learning (DRL), its application in adaptive traffic signal control has become an area of intense research. The paper explores various RL algorithms—Q-Learning, Proximal Policy Optimization (PPO), Advantage Actor-Critic (A2C), and Actor-Critic with Kronecker-Factored Trust-Region (ACKTR)—to ascertain their efficacy in PD-ITSC systems under fluctuating traffic scenarios. The research demonstrates that these RL strategies can achieve near-optimal control strategies even when vehicle detection is partial, improving upon traditional traffic management solutions.
System Architecture and Design
PD-ITSC utilizes vehicular communication devices (e.g., DSRC radios, cellphones) that support partial detection, unlike conventional ITSC that presumes full visibility of traffic flow. The study examines the adaptation of traffic systems to varied detection rates over time without manual recalibration—a significant advancement given the rapid adoption of such technologies. It leverages RL's capacity to optimize without exhaustive environment modeling, enabling ITSC to pragmatically operate amidst incomplete data.
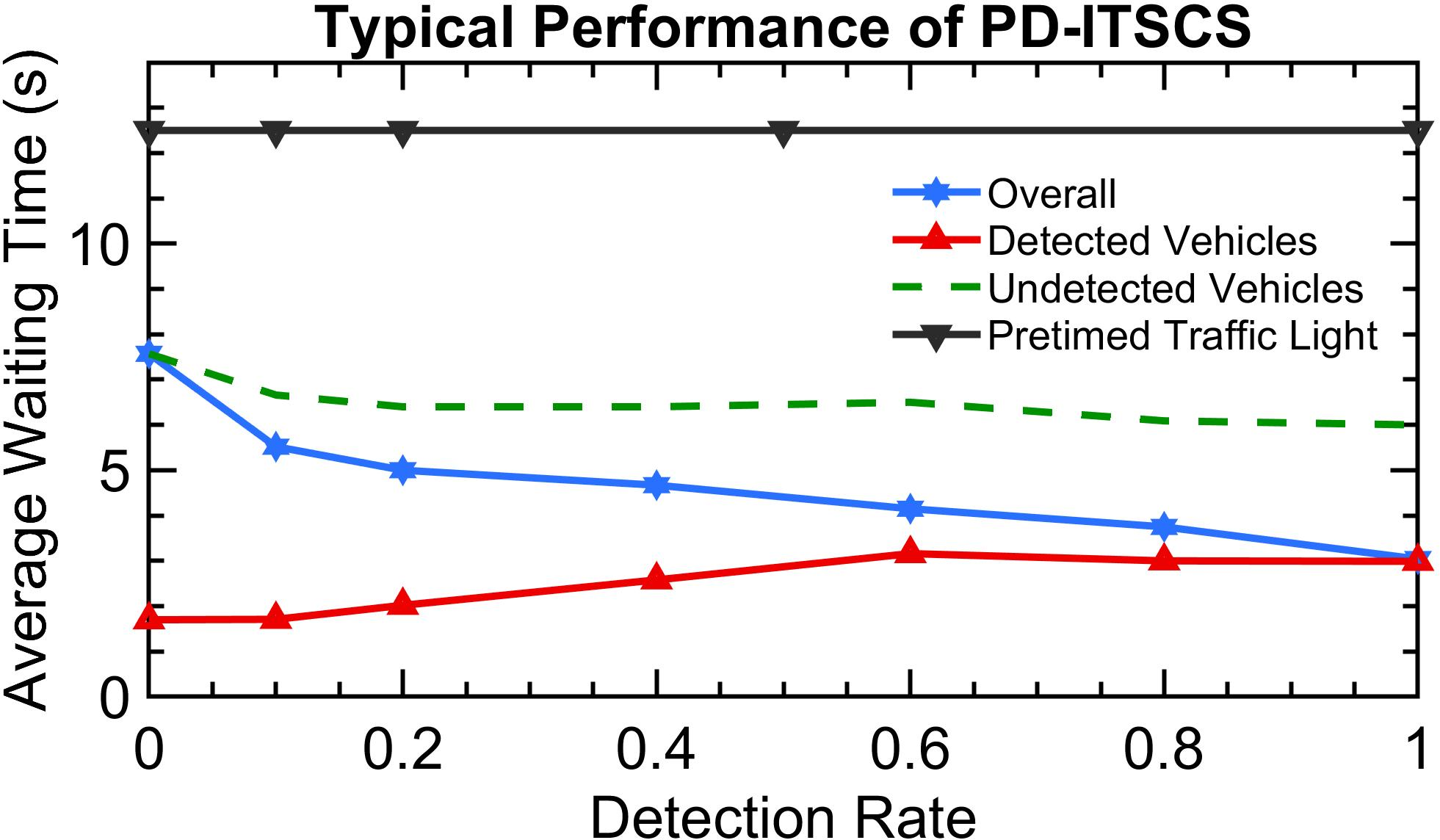
Figure 1: Increasing detection rate decreases waiting time in a typical PD-ITSC system.
Through simulations, the paper presents comparative analyses of RL algorithms in different traffic scenarios—sparse, medium, and dense flow conditions. Findings suggest that policy-based algorithms, like PPO and A2C, exhibit superior adaptability to changing environments compared to value-based methods like Q-learning, thanks to their robust policy gradient frameworks. In dense traffic scenarios, optimizing for detected vehicles aligns closely with optimal performance for all vehicles, reinforcing the efficacy of PD-ITSC systems.
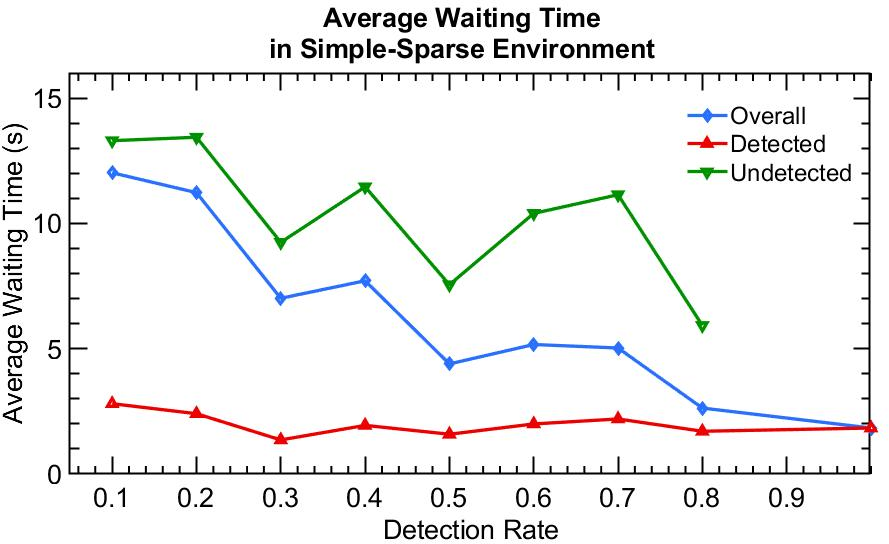
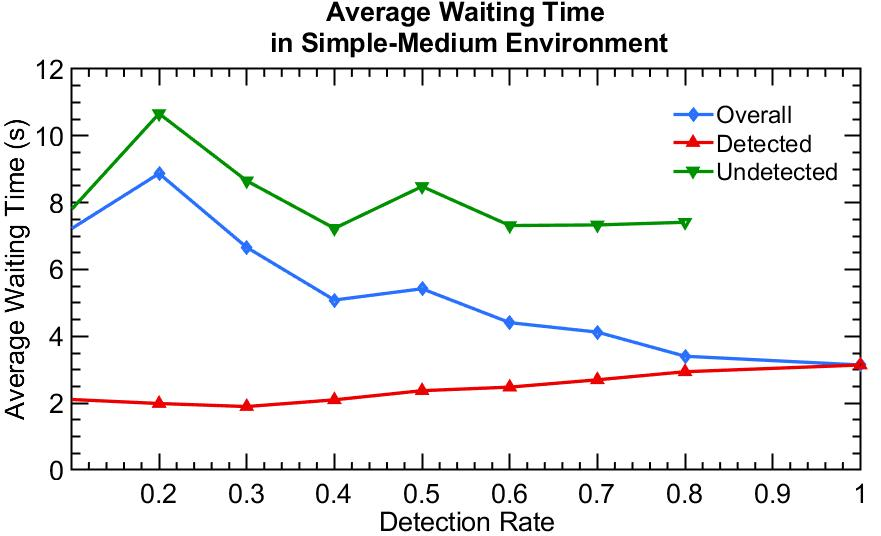
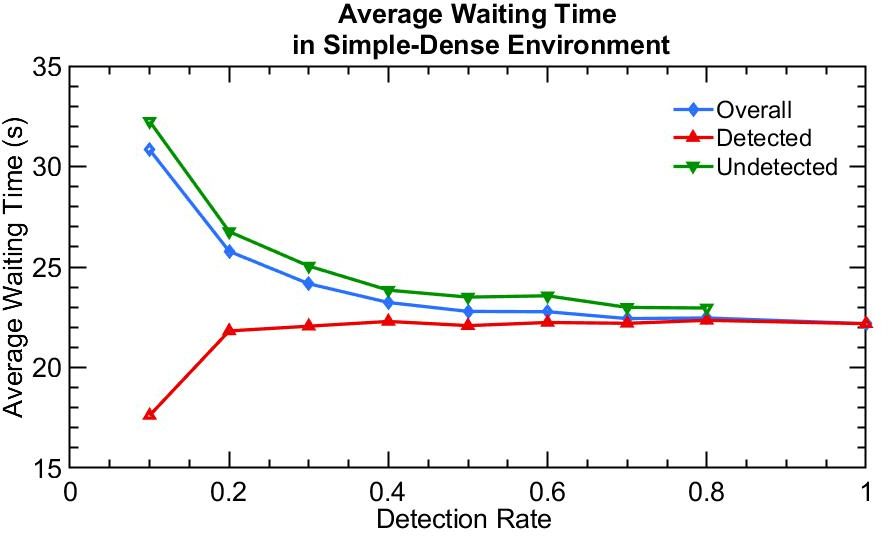
Figure 2: Performance in Simple-sparse environment.
The adaptability of PD-ITSC agents is further validated in long-term deployment simulations with increasing detection rates. These simulations display consistent improvements in traffic efficiency, notably highlighting the challenges faced by value-based methods in maintaining stable performance amidst environmental stochasticity.
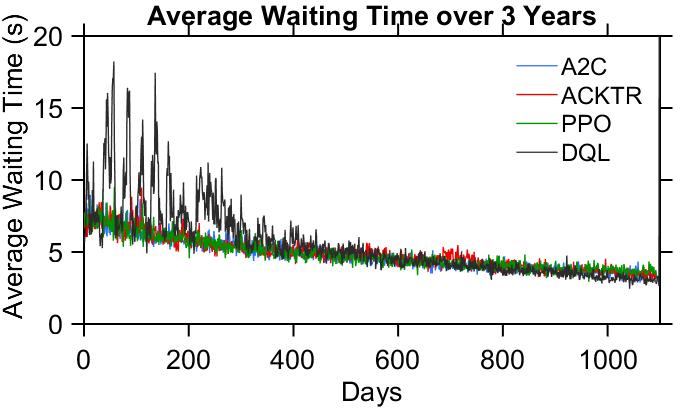
Figure 3: The average waiting time of all vehicles over 3 years, with detection rate increase linearly from 0.1 to 1.
Practical and Theoretical Implications
The research indicates that efficient traffic signal control does not necessitate full vehicular detection. Instead, optimizing detection for a subset of vehicles can suffice, particularly in dense traffic scenarios. This realization could pave the way for economically feasible city-wide deployments of PD-ITSC systems. Future studies are anticipated to focus on refining the reward structures and adapting PD-ITSC systems to more complex urban environments, potentially integrating multi-agent systems for improved global traffic management.
Conclusion
This study underscores the transformative potential of reinforcement learning in dynamically optimizing intelligent traffic systems under partial detection scenarios. Policy-based RL algorithms, due to their inherent stability and adaptability, present a promising solution for sustainable urban traffic management. PD-ITSC serves as a viable alternative for traditional traffic systems, fostering greater adoption through progressive technology deployment without prohibitive costs. The research lays the groundwork for further exploration of adaptive traffic control strategies that can effectively harness evolving vehicle detection technologies.