- The paper presents a modified EfficientNet architecture with additional convolution layers that optimizes multi-scale training for object detection.
- It introduces a distributed softmax loss to handle hierarchical tagging and label noise, achieving an improvement of 0.84 mAP points.
- Class-aware sampling and expert models are used to address severe data imbalance, contributing to a final mAP of 67.17 on the public leaderboard.
Efficient Object Detection via Network Architecture and Loss Optimization
This paper presents a solution to the Open Images Challenge 2019, focusing on object detection within the complexities of a large-scale, hierarchically structured, and imbalanced dataset. The core contributions revolve around architectural modifications to EfficientNet, a novel distributed softmax loss function, and strategies for addressing data imbalance through class-aware sampling and expert models. The solution achieves a final mAP of 67.17 on the public leaderboard and 64.21 on the private leaderboard, securing 3rd place in the competition.
Addressing Data Characteristics and Network Architecture
The Open Images dataset presents unique challenges, including its large scale (1.7M images, 12M bounding boxes, 500 categories), hierarchical tag system, significant annotation incompleteness, and substantial data imbalance. The paper leverages EfficientNet as a backbone and adapts it to the specific demands of object detection.

Figure 1: Example images from the Open Images dataset, highlighting the issue of missed annotations for bounding boxes.
Standard compound scaling methods used in EfficientNet are found to be suboptimal for multi-scale training and testing scenarios common in object detection. The authors hypothesize that the standard EfficientNet scales up resolution to improve performance in single-scale training, which is detrimental when training and testing occur across multiple scales. To address this, they propose fixing the resolution and re-assigning the stage of EfficientNet-B7 to mimic ResNeXt, thereby optimizing parameter allocation across different architectural stages. More specifically, the modified architecture includes additional convolutional layers in stage four.
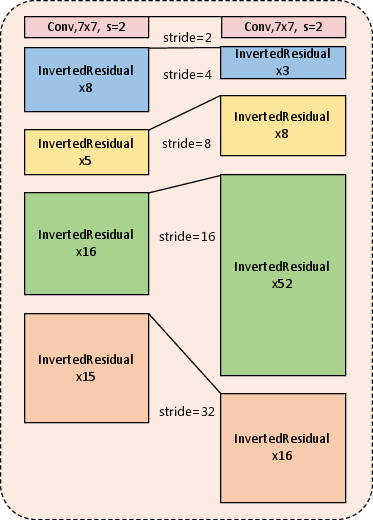
Figure 2: A comparison between the standard EfficientNet-B7 architecture and the proposed variant, emphasizing the increased convolutional layers in stage four.
Distributed Softmax Loss for Hierarchical Tagging and Label Noise
The paper introduces a distributed softmax loss to handle the hierarchical tag system and label noise inherent in the Open Images dataset. This loss function is designed to address the limitations of standard softmax cross-entropy loss, which struggles with hierarchical relationships and ambiguous categories.
The distributed softmax loss is formulated as:
Lcls=c=1∑Cyclog(∑i=1Cexiexc)
where yc is an element of the label vector y, with k non-zero elements each set to $1/k$ corresponding to the k≥1 categories. This approach allows for multi-label training while maintaining suppression between categories, improving performance by 1 mAP point compared to the standard softmax loss.
Class-Aware Sampling, Augmentation, and Expert Models for Data Imbalance
The Open Images dataset exhibits a severe data imbalance, with instance counts varying drastically across categories. The paper addresses this through class-aware sampling, which balances major and rare categories. The method involves uniformly sampling a category and then sampling an image containing objects of that category.
To mitigate overfitting introduced by class-aware sampling, auto augmentation is applied at both the image and bounding box levels. Furthermore, expert models are trained on rare categories and ensembled to solve the data imbalance problem. Strategies to reduce false positives when using expert models are employed, including building a confusion matrix to identify easily misclassified categories, training multiple expert models with overlapping subsets, and training a classifier to re-weight the confidence of detected boxes.
Experimental Results and Ablation Studies
The efficacy of the proposed methods is validated through detailed ablation studies. Results demonstrate that the variant of EfficientNet-B7 outperforms ResNeXt-152 by 1.71%. The distributed softmax loss improves performance by 0.84 mAP points, while class-aware sampling yields a significant gain of 4.67 points. Auto augmentation and a classifier further enhance the model, achieving a best single-model mAP of 62.29%. Ensembling 12 different models results in a final mAP of 67.17% on the public leaderboard and 64.21% on the private leaderboard.
Conclusion
This paper effectively addresses the challenges of large-scale hierarchical object detection with data imbalance. By modifying the EfficientNet architecture, introducing a distributed softmax loss, and employing class-aware sampling with expert models, the solution achieves state-of-the-art results on the Open Images dataset. These techniques offer valuable insights into handling the complexities of real-world object detection tasks.