- The paper demonstrates that untrained subnetworks in randomly weighted neural networks can approach the accuracy of fully trained models using the edge-popup algorithm.
- It introduces an innovative method that selects top-scoring weights without altering them, leveraging a gradient estimator for score updates.
- Experimental results on CIFAR-10 and ImageNet reveal that wider and deeper networks with optimal initialization can contain highly effective subnetworks.
Summary of "What's Hidden in a Randomly Weighted Neural Network?"
Introduction
The paper "What's Hidden in a Randomly Weighted Neural Network?" (1911.13299) explores the concept that untrained subnetworks within randomly initialized neural networks can achieve competitive performance without weight optimization. It challenges traditional neural network training paradigms, which rely on tuning weight values via gradient descent. This study uncovers the potential of subnetworks within overparameterized models, leveraging random weights to match the accuracy of trained networks. An algorithm is proposed to identify these efficient subnetworks, broadening the understanding of neural network initialization and architecture.
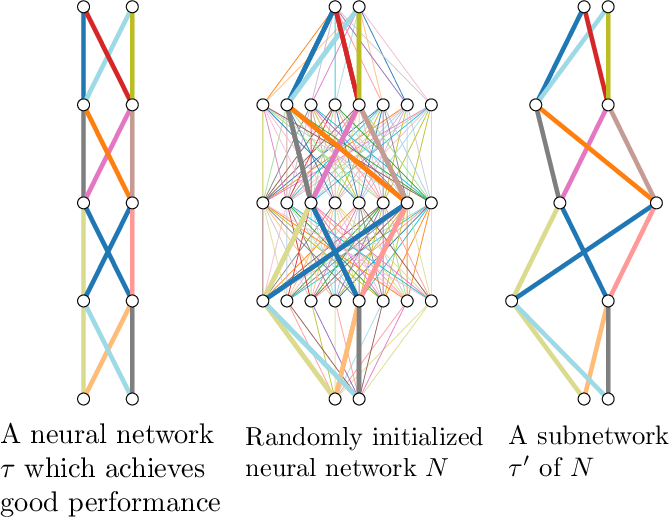
Figure 1: A conceptual illustration showing that a sufficiently overparameterized neural network with random weights contains a subnetwork that performs comparably to a trained network.
Methodology
The paper introduces the edge-popup algorithm, which optimizes the selection of subnetworks without modifying weight values. Each weight in the network is associated with a score, and during the forward pass, the top-scoring weights are selected, forming a subnetwork. These scores are updated using a gradient estimator during the backward pass. Unlike traditional approaches, the edge-popup method never updates the actual weights, only the scores, allowing previously inactive edges to become part of the subnetwork.

Figure 2: The edge-popup algorithm associates scores with each edge, which are updated using the straight-through estimator during the backward pass.
Experimental Setup
Experiments were conducted on CIFAR-10 and ImageNet to demonstrate the robustness of the proposed method. Various architectures and distributions were tested to evaluate the performance of untrained subnetworks. Significant findings show that wider and deeper networks contain high-performing subnetworks. Additionally, the choice of initialization distribution critically impacts performance, highlighting kaiming normal initialization as superior in retaining subnetwork efficacy.
Results
The results showcase that untrained subnetworks can achieve impressive accuracy levels on both CIFAR-10 and ImageNet datasets. When the network's width and depth are sufficiently large, the performance of these subnetworks approaches that of fully trained models. For instance, a randomly weighted Wide ResNet-50 can contain a subnetwork that matches the accuracy of a trained ResNet-34 on ImageNet.
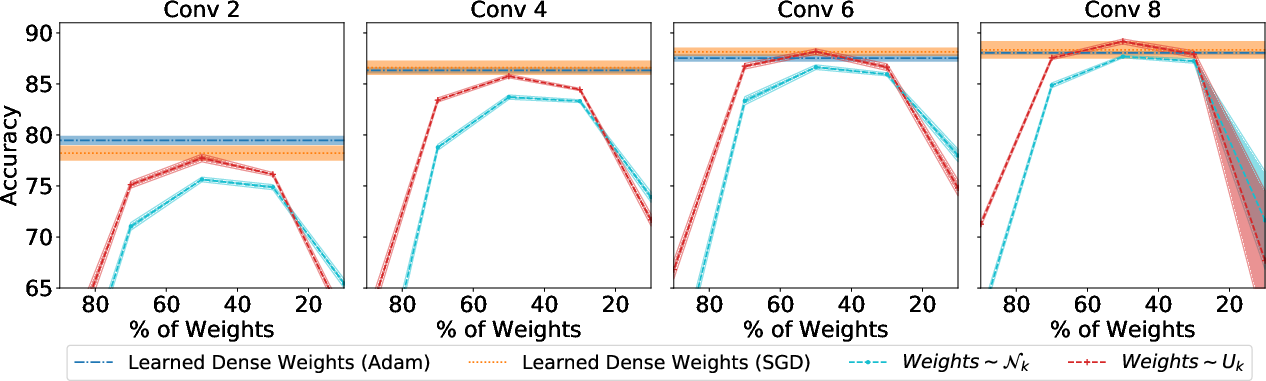
Figure 3: ImageNet performance tests demonstrate the capability of subnetworks within randomly weighted Wide ResNet-50 to match trained ResNet-34 accuracy.
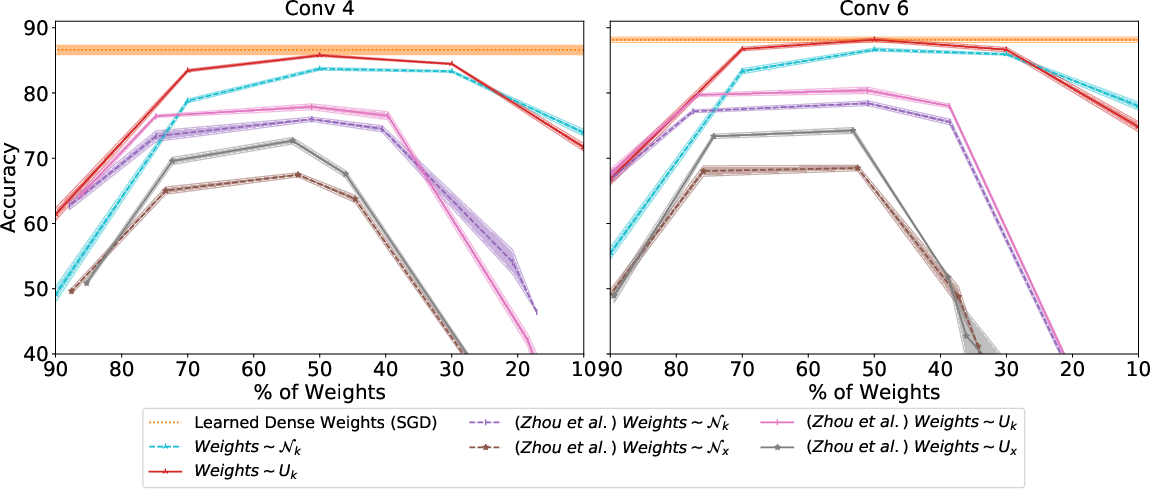
Figure 4: On CIFAR-10, the edge-popup algorithm outperforms the method of Zhou et al., demonstrating its efficiency in finding effective subnetworks.
Implications and Future Work
The implications of this research are profound, suggesting that the initialization process and architectural choices in neural networks may hold untapped potential for performance enhancement without extensive training protocols. This understanding can inform new strategies in neural network design, potentially reducing training time and resource consumption.
Future directions may involve exploring faster algorithms and alternating optimization strategies for neural architectures. The findings provide a pathway toward a deeper comprehension of neural initialization and optimization processes, encouraging investigation into the surprising efficacy of randomly initialized networks.
Conclusion
This study reveals the inherent capacity of randomly initialized neural networks to contain effective subnetworks. By shifting focus from exhaustive training to strategic subnetwork identification, the research opens novel avenues for efficient neural network deployment and encourages a reevaluation of initialization practices.
