- The paper introduces Gap Sentences Generation (GSG) as a novel pre-training objective that masks entire sentences to simulate summary creation.
- It leverages an encoder-decoder Transformer architecture enhanced with GSG and Masked Language Modeling to focus on coherent summarization.
- PEGASUS achieves state-of-the-art performance across 12 datasets, particularly excelling in low-resource conditions with minimal fine-tuning.
Abstract
The paper "PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization" (1912.08777) introduces a novel self-supervised objective named Gap Sentences Generation (GSG) for the pre-training of large Transformer-based models aimed at abstractive summarization tasks. This approach strategically masks whole sentences in a document to create a pseudo-summary that encourages the model to develop holistic understandings and generate concise, coherent summaries. The paper evaluates PEGASUS across 12 diverse summarization tasks, demonstrating its state-of-the-art performance with particular efficacy in low-resource settings.
Model Architecture
PEGASUS is built upon the standard Transformer encoder-decoder architecture, enhanced with unique pre-training objectives (Figure 1). It incorporates both GSG and Masked LLM (MLM) to leverage the strengths of understanding sentence and word-level information. The key innovation, GSG, involves selecting sentences that are likely summary candidates and masking them to force the encoder-decoder model to generate these sentences based on remaining context. This setup mimics the task of abstractive summarization more closely than previous word or span masking strategies.
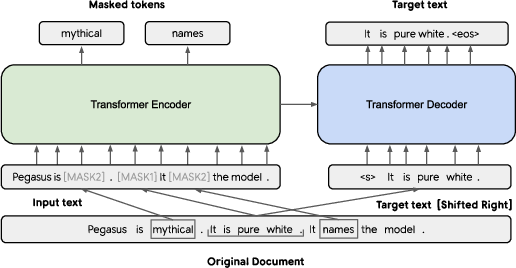
Figure 1: The base architecture of PEGASUS showing the use of GSG and MLM in tandem.
Pre-training Objectives
Gap Sentences Generation (GSG)
In GSG, whole sentences deemed important are masked, and the model is tasked with generating these sentences, simulating summary creation. Various strategies for sentence selection are explored: random, lead (selecting leading sentences), and principal (choosing sentences based on importance measured by ROUGE1-F1 against the rest of the document). Extensive experiments reveal that the principal method with independent scoring is optimal for high-quality pre-training.
Masked LLM (MLM)
MLM serves as a secondary objective, wherein 15% of tokens in unselected sentences are masked. While beneficial initially, MLM is shown to be less effective than GSG in extended pre-training, leading to its exclusion from the final model configuration.
Implementation and Fine-tuning
Hyperparameters and Training
PEGASUS is trained with varying hyperparameters to identify optimal settings. The large model variant employs 568M parameters, Unigram tokenization, and a unique sentence selection strategy. It is pre-trained on two massive corpora: C4 and HugeNews, with findings indicating domain-aligned pre-training corpora (e.g., news data for news summarization tasks) improve performance.
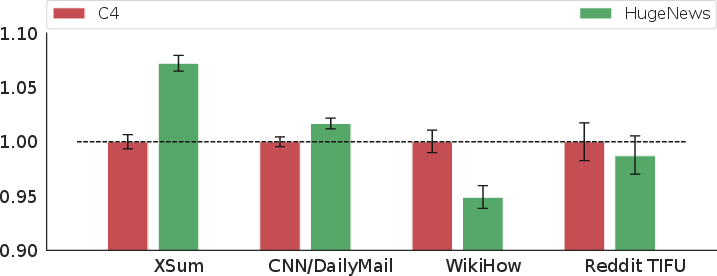
Figure 2: Effect of pre-training corpus on downstream summarization tasks showing the importance of domain alignment.
Downstream Evaluation
PEGASUS demonstrates state-of-the-art performance across 12 datasets with diverse domains, such as XSum, CNN/DailyMail, and Reddit TIFU. Its ability to adapt with minimal fine-tuning data is evident as it reaches competitive performance with as few as 1000 examples.
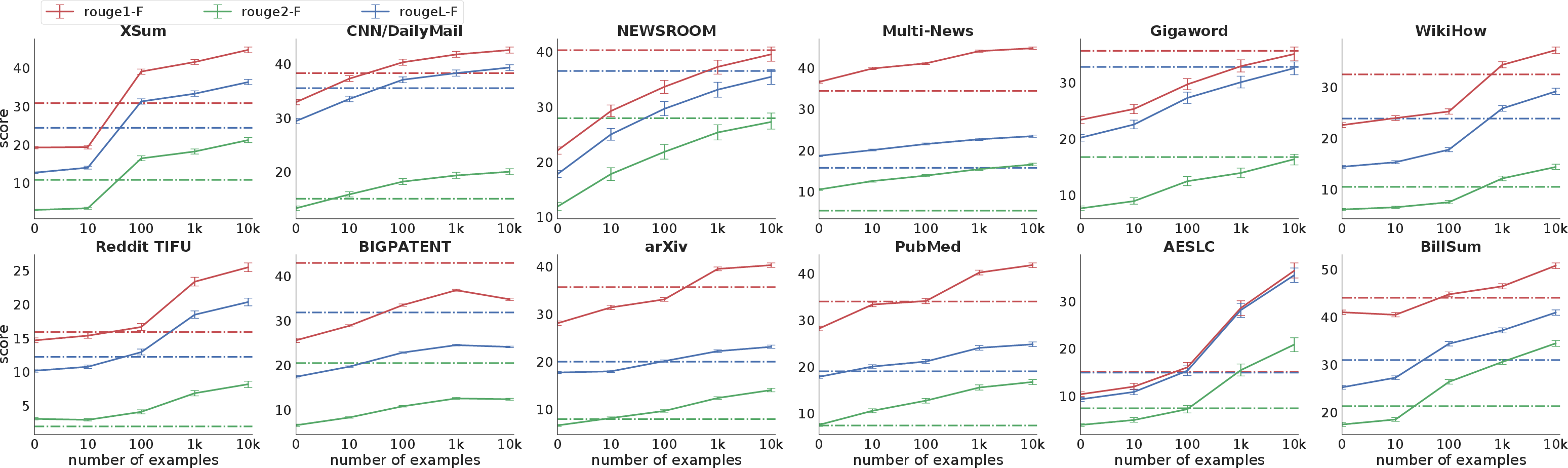
Figure 3: Fine-tuning performance of PEGASUS on limited supervised examples compared against non-pre-trained Transformer models.
Practical Considerations
Computational Efficiency
While PEGASUS achieves remarkable results, its training involves extensive computational resources typical for large-scale transformer models. Efficient deployment requires careful management of resources, especially on GPUs or TPUs.
Low-resource Scenarios
A notable strength of PEGASUS is its performance in low-resource scenarios where supervised training data is scarce. It holds promise for real-world applications where annotated text data may be limited or expensive to curate.
Extensions and Future Work
Further research could explore combining PEGASUS with other state-of-the-art LLMs or enhancing its capabilities on cross-domain summarization. The investigation of additional selection strategies for GSG could also yield insights into optimizing model training further.
Conclusion
PEGASUS transforms abstractive summarization by closely aligning pre-training objectives with the ultimate task requirements, leading to significant improvements in model performance, especially in data-scarce environments. Its architecture and methodology offer a roadmap for future advancements in summarization tasks, balancing computational demands with practical application needs.