- The paper introduces a novel watermark attack that exploits DNN-based OCR vulnerabilities through targeted, natural-looking perturbations.
- It employs a modified Momentum Iterative Method confined to watermark regions, ensuring perturbations remain inconspicuous while inducing OCR errors.
- Empirical evaluations using DenseNet+CTC frameworks reveal high attack success and cross-model transferability, highlighting the need for robust defense strategies.
Analysis of Adversarial Attacks on OCR Systems
This paper presents an approach to exploit vulnerabilities in Optical Character Recognition (OCR) systems using adversarial watermarks. By leveraging knowledge of the deep neural network (DNN) architectures that underpin OCR technology, the authors propose a method to make subtle but deliberate manipulations that provoke erroneous outputs from OCR models without arousing suspicion from human observers.
Conceptual Framework and Contribution
Vulnerabilities of DNN-based OCR
The authors identify critical vulnerabilities in modern OCR systems that arise due to their reliance on DNNs, which are susceptible to adversarial attacks. Existing adversarial approaches in computer vision, such as those creating minute perturbations, fall short when applied to OCR because of the stark and homogenous backgrounds of typical documents. Such perturbations would be conspicuous against the white backgrounds used in document images, making traditional methods ineffective for OCR applications.
Proposed Watermark Attack
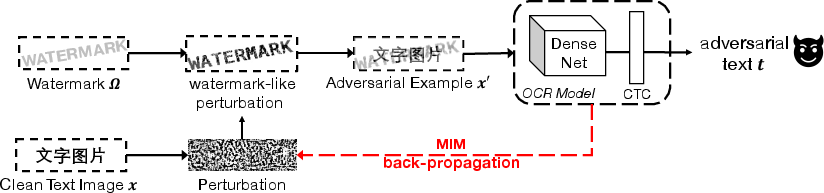
To address this challenge, the paper introduces a novel method of creating adversarial examples by embedding perturbations in the form of natural-looking watermarks. The watermark attack method is designed to avoid detection by human vision while effectively fooling OCR systems:
Implementation Strategy
Attack Methodology
The technique involves generating adversarial perturbations using a modification of the Momentum Iterative Method (MIM). A constraint on these perturbations restricts them to a predefined watermark-shaped region, thereby maintaining natural document aesthetics. The attack iteratively adjusts the perturbations, utilizing features from the DenseNet architecture combined with Connectionist Temporal Classification (CTC) loss:
- MIM-based watermark attack: Gradient-based optimization confines perturbations to perceived watermark regions, operating within an L-infinity ball to ensure the fidelity of the alteration.
Variants and Adaptation
Different variants of the watermark attack are proposed to enhance naturalness:
- WM_init: Starts with a pre-existing watermark to ensure initial consistency.
- WM_neg: Focuses on perturbations resulting in negative gradients to avoid unnecessary whitening.
- WM_edge: Confines perturbations to the edges of text to simulate defects.
The paper also demonstrates how the attack model can work in targeted changes in character sequences, compatible with the complexity of languages like Chinese.
Empirical Evaluation
Attack Success and Transferability
The efficacy of the proposed method is evaluated against a state-of-the-art DenseNet+CTC OCR framework using a substantial dataset of Chinese script. The success rate, MSE, PSNR, and SSIM metrics showcase how WM variants outperform traditional methods regarding perceptibility:
- Real-world scenarios: Through scenarios like altering driver's licenses (Figure 2) and company financial statements (Figure 3), the attack demonstrates substantial adaptability.
- Inter-model transferability: Success is not limited to the white-box setting but extends to proprietary platforms like Tesseract—indicative of substantial cross-model generalizability.

Figure 2: An adversarial attack example in driver license recognition. The OCR output a licenses number of NAL12505717 while it is actually NHL12506717.

Figure 3: Attack on a listed Chinese company's annual report. All the revenue numbers are altered in the OCR result.
Defensive Strategies
Exploration of conventional defenses reveals varying levels of robustness:
- Local smoothing and noise algorithms: Effective, yet often at the cost of reducing legitimate text recognition accuracy.
- Watermark-removal techniques: Methods like inpainting can be overzealous, harming document integrity even while excising adversarial marks.
Conclusion
The paper concludes by emphasizing the newfound potential for adversarial attacks in document-sensitive systems, warranting further exploration of both refined attack methodologies and robust defense mechanisms. The watermark approach underscores the necessity of rethinking adversarial security in domain-specific applications where cosmetic aberrations may inadvertently provide a cloak for deeper vulnerabilities. The ongoing exploration in watermark shapes, semantic inclusion, and LLMs, represents a critical path forward for AI safety research.