- The paper introduces Dense2Sparse, which merges dense and sparse rewards to rapidly learn policies while ensuring robustness against environmental uncertainty.
- It employs a ResNet34-based state representation and MUJOCO simulation on a 7-DOF robotic arm to handle challenges like camera misalignments.
- Experimental results demonstrate improved convergence speed and high success rates, achieving near-oracle performance even under perturbed conditions.
Balance Between Efficient and Effective Learning: Dense2Sparse Reward Shaping for Robot Manipulation with Environment Uncertainty
Introduction
The paper "Balance Between Efficient and Effective Learning: Dense2Sparse Reward Shaping for Robot Manipulation with Environment Uncertainty" presents a novel reward shaping technique, Dense2Sparse, to address the challenges posed by environmental uncertainty in robot manipulation tasks. The Dense2Sparse method aims to balance the faster convergence of dense rewards with the robustness of sparse rewards, providing a strategy that enhances both the efficiency and effectiveness of Deep Reinforcement Learning (DRL) for robotic systems.
Reward Shaping in DRL
Reward shaping is crucial in DRL as it directly influences the learning speed and the quality of the learned policy. Traditional methods either employ dense rewards, offering continuous feedback but prone to noise, or sparse rewards, which are robust but lead to slower convergence due to limited feedback. Dense2Sparse leverages the best of both approaches, using dense rewards initially to guide rapid policy learning, then switching to sparse rewards to refine policy robustness and performance. This approach is particularly beneficial in environments with high uncertainty, where sensor noise and environmental disturbances may otherwise severely degrade learning effectiveness.
System Architecture and Implementation
The paper utilizes a simulated environment powered by the MUJOCO engine, with experiments conducted on a 7-DOF robotic arm performing reaching and lifting tasks. The Dense2Sparse approach integrates a ResNet34-based state representation model to estimate the physical states from camera inputs, which are utilized in the reward shaping process. Initially, dense rewards derived from the estimated states guide the learning, helping the agent to formulate a suboptimal policy quickly. Subsequently, the system transitions to sparse rewards, effectively minimizing the accumulated errors from state estimation and reward noise, thus enhancing the policy's final performance.
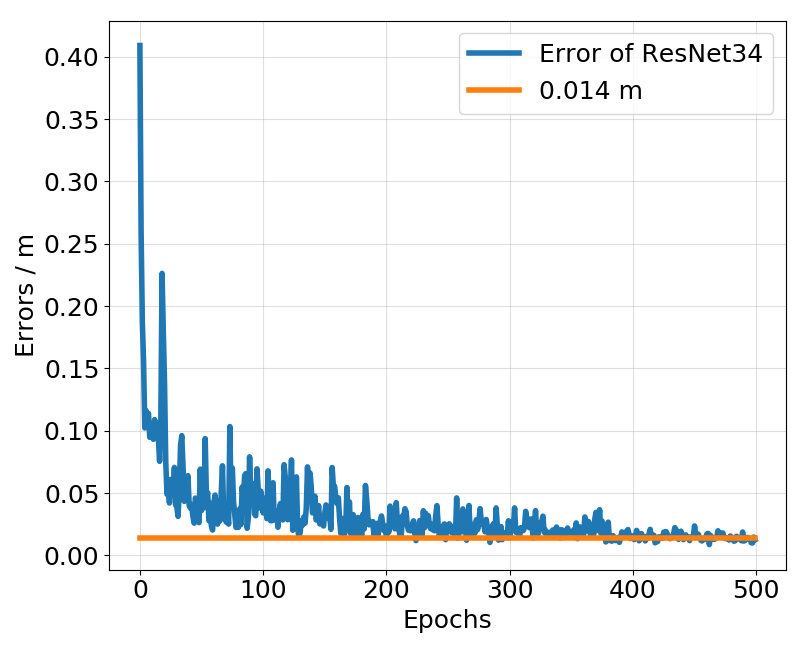
Figure 1: The error graph of representation models during training.
The training process involves two stages, catering to dense and sparse reward phases. This setup is designed to test the resilience of the Dense2Sparse method against environmental perturbations like camera misalignments. The evaluation metrics include episode rewards and success rates, tracked across multiple random seeds for statistical significance.
Experimental Results
Extensive experiments demonstrate that the Dense2Sparse method outperforms standalone dense or sparse approaches in both convergence speed and final policy performance. In noise-free settings, Dense2Sparse achieves near-oracle level performance, and when subjected to environmental uncertainties such as camera misalignments, it maintains high performance and stability.
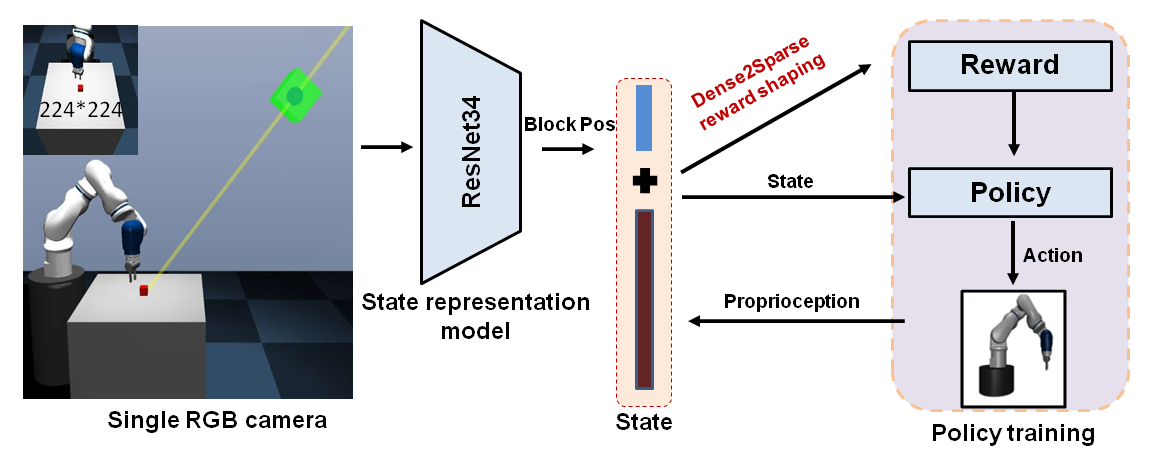
Figure 2: Schematic diagram of the testing platform.
In reaching tasks, Dense2Sparse rapidly achieves high rewards with success rates approaching those of oracle-based methods. In more complex lifting tasks, Dense2Sparse exhibits significantly better robustness and success rates compared to standalone methods, highlighting its potential for complex applications where precise state knowledge is inaccessible or unreliable.

Figure 3: Comparative tests with different camera setting, (a) scenario for ideal camera alignment setting, (b) scenario for 5\circ camera alignment error, (c) scenario for 10\circ camera alignment error.
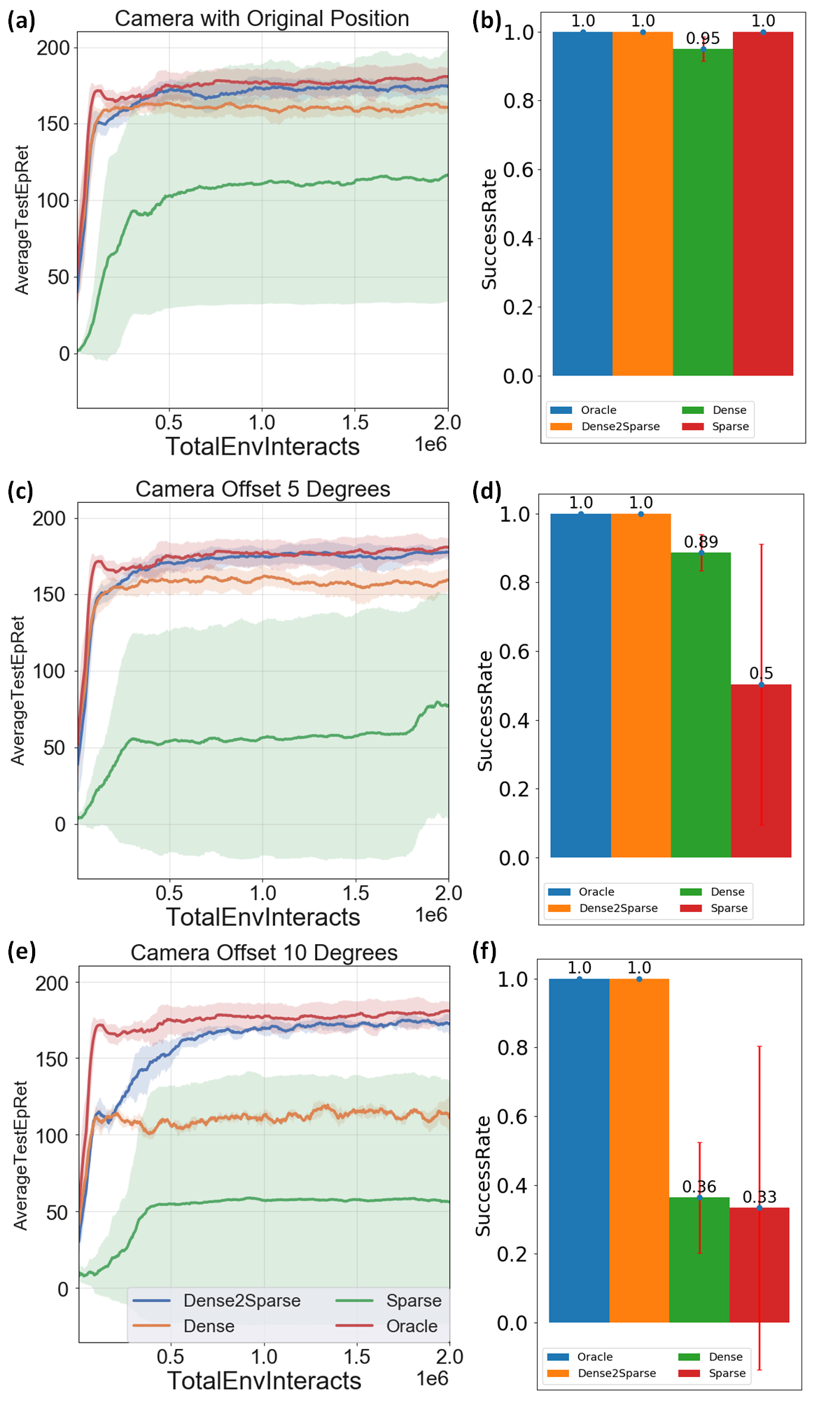
Figure 4: The evaluation results in the reaching task. The solid line and transparent belt in (a), (c) and (e) represent the mean and standard deviation of 3 random seeds for three camera settings which represent no camera shifting, with 5\circ camera shifting, with 10\circ camera shifting, respectively.
Discussion and Conclusion
Dense2Sparse presents a significant advancement in reward shaping techniques for DRL under uncertainty. By switching from dense to sparse rewards, it effectively mitigates noise issues while ensuring fast convergence and high-quality policies. This method is particularly advantageous in real-world scenarios where achieving exact state measurements is challenging. Future work could explore the integration of Dense2Sparse with sim-to-real transfer techniques and expand its application to dynamic, real-world environments, further enhancing the robustness and applicability of DRL in complex robotic tasks.