- The paper provides a comprehensive empirical analysis of embedding-based entity alignment, identifying methodological gaps and proposing realistic benchmarks using IDS sampling.
- The paper demonstrates that integrating attribute and literal information significantly improves alignment accuracy, though challenges remain for low-degree entities.
- The paper shows that advanced inference strategies like CSLS and stable matching enhance embedding discriminability and overall performance.
Benchmarking Embedding-Based Entity Alignment for Knowledge Graphs: A Comprehensive Analysis
Introduction
The paper "A Benchmarking Study of Embedding-based Entity Alignment for Knowledge Graphs" (2003.07743) conducts an exhaustive empirical investigation into the state-of-the-art in embedding-based entity alignment (EA) across knowledge graphs (KGs). The study addresses several critical gaps in the literature: the lack of comprehensive surveys on embedding-based EA, the absence of realistic and widely-accepted benchmark datasets, insufficient open-source tools, and limited analysis of the methods’ generalization and robustness, especially concerning heterogeneity and scale.
The authors contribute a detailed taxonomy of 23 prominent embedding-based EA methods, introduce novel KG sampling algorithms for realistic dataset construction, implement the OpenEA benchmarking library, and perform rigorous evaluation and analysis of EA models’ geometric and empirical properties. The study further explores unexplored areas such as model complementarity, alignment inference strategies, and the implications of non-Euclidean embeddings.
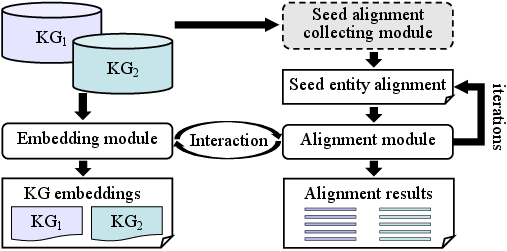
Figure 1: Framework of embedding-based entity alignment, showing separate and unified embedding spaces with alignment modules.
Datasets and Sampling: Realistic Benchmarks
A salient contribution of the work is the creation of dedicated benchmark datasets that closely mirror the statistical properties—especially degree distributions—of the source KGs (such as DBpedia, Wikidata, and YAGO).
Current de facto datasets like DBP15K and WK3L are shown to be systematically biased toward high-degree entities, overestimating model performance on real-world KGs. To address this, the authors propose iterative degree-based sampling (IDS), designed to produce smaller subgraphs with degree distributions that minimize Jensen-Shannon divergence from the original KG, while maintaining sufficient connectivity, scale, and diversity of heterogeneity factors (e.g., multilingualism, schema, scale).
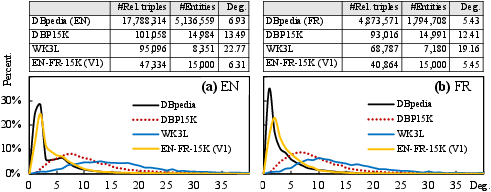
Figure 2: Comparison of degree distributions and average degrees in popular datasets and newly constructed ones.
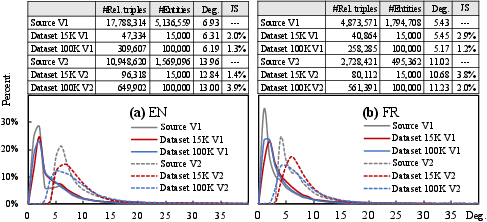
Figure 3: Degree distributions of sampled datasets (EN-FR-15K/100K) from DBpedia compared to the real KG, showing convergence toward true degree statistics.
This methodology enables more reliable and generalizable benchmarking, as supported by detailed structural analysis and empirical tests. Sampling via IDS, compared to random or PageRank-centric schemes, preserves graph characteristics better, including cluster structure and avoidance of large numbers of isolated entities.
OpenEA: An Extensible Benchmarking Library
To facilitate reproducible research and fair comparison, the authors release OpenEA, an open-source library implemented in Python/TensorFlow. OpenEA is architected with modularity and extensibility at its core, decoupling embedding and alignment modules and integrating 12 prominent EA models (including MTransE, JAPE, BootEA, RDGCN, MultiKE, etc.), eight KG embedding models (e.g., TransE, TransH, ConvE, RotatE), and two attribute embedding schemes. Configuration management and abstraction supports the integration of new models and combination of approaches.
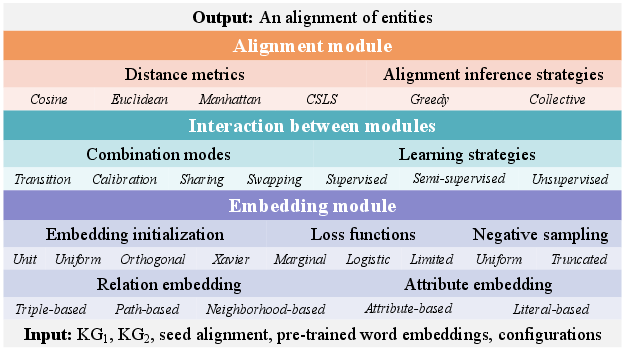
Figure 4: The software architecture of OpenEA, enabling plug-and-play benchmarking.
Empirical Study: Comparative and Granular Analysis
An extensive experimental campaign is conducted leveraging 5-fold cross-validation across multiple dataset versions (sparse/dense; 15K/100K entity splits) and various KG/language pairs. Evaluation is standardized using metrics such as Hits@1/5, Mean Reciprocal Rank (MRR), and Mean Rank (MR).
Key findings include:
- Model Performance: RDGCN, BootEA, and MultiKE are the top-tier performers. The inclusion of literal and attribute information (as in MultiKE and RDGCN), as well as robust bootstrapping (as in BootEA), are highly correlated with superior results.
- Impact of Graph Density: All models, especially those reliant on relational structure, perform significantly better on denser datasets. Long-tail/low-degree entities remain a challenge due to insufficient signal for robust embedding construction.
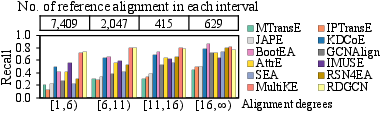
Figure 5: Alignment recall stratified by entity degree, highlighting persistent underperformance on long-tail entities.
- Semi-supervised Learning: BootEA’s iterative alignment augmentation provides a notable boost, contingent on both the quantity and quality (precision) of generated new alignments. Naive self-training leads to error accumulation and diminished gains in alternatives like IPTransE.
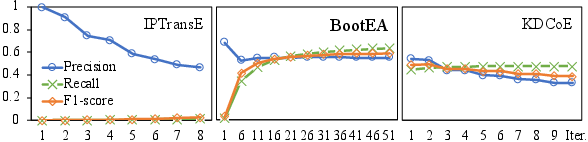
Figure 6: Evolution of alignment seed quality through the self-training process in semi-supervised models.
- Auxiliary Signal: The benefit of attribute and literal information is nuanced. Literal embeddings with strong multilingual initialization can substantially aid performance, whereas weak attribute correlations or unresolved attribute alignment yield little empirical improvement or may even harm results.
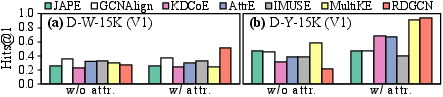
Figure 7: Ablation study quantifying the effect of attribute and literal incorporation on EA performance.
- Scalability: Approaches vary dramatically in computational efficiency. BootEA and RSN4EA incur high training costs due to negative/path sampling, while GCNAlign and MTransE are significantly faster.
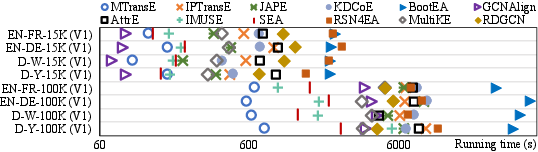
Figure 8: Run-time comparison demonstrating the computational trade-offs across models and dataset sizes.
Geometric and Inference Module Analysis
Going beyond standard metric-based benchmarking, a geometric analysis of learned embeddings is conducted:
- Nearest Neighbor Structure: Models vary in the discriminability of embedding spaces. Effective EA correlates with high top-1 similarity scores and high variance among the k-nearest candidates, signifying sharply defined latent neighborhoods.
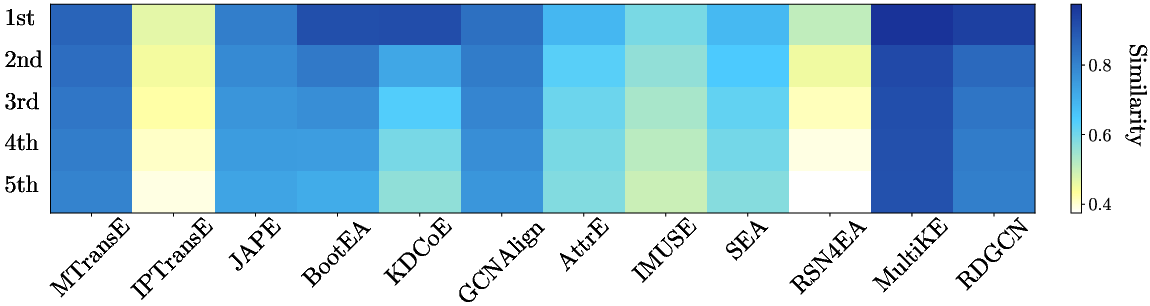
Figure 9: Cosine similarity structure among the top-5 candidates for different models, reflecting embedding discriminativeness.
- Hubness and Isolation: A substantial proportion of target entities remain isolated—never emerging as top-1 neighbors—while others accrue excessive 'hub' status, causing violation of 1-to-1 mapping constraints and misalignments.
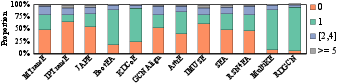
Figure 10: Distributional analysis of hub/isolated entities for top-1 neighbor assignments.
To mitigate these phenomena, the study evaluates Cross-domain Similarity Local Scaling (CSLS) and stable marriage matching for global, rather than greedy, alignment inference. Both strategies yield significant Hits@1 improvements for most approaches; notably, stable matching is less sensitive to the specifics of the distance metric.
Under-Explored Embedding Models and Model Suitability
An important observation is that models originally designed for link prediction do not necessarily excel in EA. Advanced Euclidean translational models (TransH, TransD) offer incremental improvements, but RotatE—a non-Euclidean, complex-valued embedding—emerges as a highly effective choice for EA. Conversely, more complex models like TransR and HolE, which depend heavily on relation/property alignment, fail to generalize due to lack of alignment supervision for properties and relations.
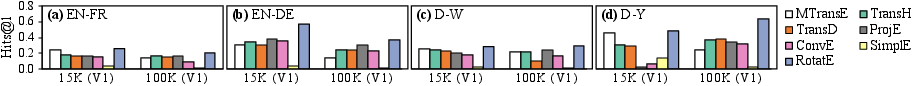
Figure 11: Empirical performance of unexplored KG embedding models when repurposed for entity alignment.
The finding emphasizes the need for alignment-centric design in embedding models, and points to non-Euclidean approaches as a fertile direction.
Complementarity and Limits: Conventional vs. Embedding-Based EA
Comparative analysis with conventional symbolic/statistical EA methods (LogMap, PARIS) shows no consistent dominance by embedding-based approaches. While embedding-based models excel in integrating relational and latent information, symbolic approaches still perform strongly, particularly in attribute-rich cases, and provide holistic reasoning capabilities (e.g., inconsistency handling) that embedding-based models lack.
An ablation by feature type demonstrates that symbolic methods are highly reliant on well-aligned attribute information, while embedding-based methods are more robust in the absence of such signals.
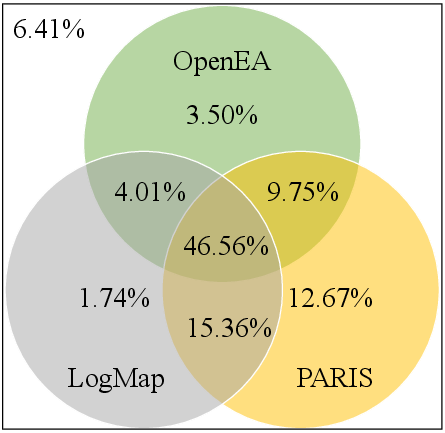
Figure 12: Venn analysis of correct entity alignment discovered across diverse paradigms—showing considerable complementarity and headroom for hybrid systems.
Implications and Future Prospects
The study rigorously exposes the central problems limiting current progress in embedding-based EA:
- Inability to handle highly sparse/long-tail entities due to weak local signal
- Sub-optimal inference strategies leading to hubness/isolation pathologies
- Limitations of reliance on supervision in the form of seed alignments
- Insufficient exploitation of non-Euclidean latent spaces and multi-modal auxiliary features
- Poor scalability to real-world, large-scale KGs
Future research directions highlighted include:
- Unsupervised and active/aligned learning paradigms to reduce reliance on labeled data
- Enhanced modeling for long-tail and sparse entities, including multi-modal signals and joint link prediction-EA frameworks
- Hybrid symbolic/embedding-based systems to leverage complementarity and address diverse scenarios
- Advances in non-Euclidean (hyperbolic/complex) embedding families, particularly in architectures explicitly targeting alignment rather than local relational semantics
- Scalable blocking and approximate candidate generation mechanisms for EA at web-scale
Conclusion
This paper constitutes the most comprehensive benchmarking and analytical investigation of embedding-based entity alignment for KGs to date. It provides critical insights into intrinsic limitations, architectural and dataset biases, and the underlying geometric and algorithmic properties of current methods. Notably, it establishes robust best practices for dataset construction (IDS), empirical evaluation, and software design (OpenEA), and advances the discussion toward holistic, scalable, and robust approaches for real-world EA.
The findings established here set an agenda for the next generation of EA research, centering the need for discriminative, robust, and scalable models capable of incorporating heterogeneous signals and leveraging both embedding and symbolic paradigms effectively.