Hierarchical Predictive Coding Models in a Deep-Learning Framework
Abstract: Bayesian predictive coding is a putative neuromorphic method for acquiring higher-level neural representations to account for sensory input. Although originating in the neuroscience community, there are also efforts in the machine learning community to study these models. This paper reviews some of the more well known models. Our review analyzes module connectivity and patterns of information transfer, seeking to find general principles used across the models. We also survey some recent attempts to cast these models within a deep learning framework. A defining feature of Bayesian predictive coding is that it uses top-down, reconstructive mechanisms to predict incoming sensory inputs or their lower-level representations. Discrepancies between the predicted and the actual inputs, known as prediction errors, then give rise to future learning that refines and improves the predictive accuracy of learned higher-level representations. Predictive coding models intended to describe computations in the neocortex emerged prior to the development of deep learning and used a communication structure between modules that we name the Rao-Ballard protocol. This protocol was derived from a Bayesian generative model with some rather strong statistical assumptions. The RB protocol provides a rubric to assess the fidelity of deep learning models that claim to implement predictive coding.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about “predictive coding,” a way of thinking about how the brain—and machines—might learn. The big idea is simple: a higher part of the system tries to predict what lower parts (like your senses) will see or hear. Then it compares that prediction to what actually comes in. The difference between the prediction and reality is called the “prediction error.” That error is used to improve future predictions. The paper reviews classic brain-inspired models of predictive coding and shows how to build and study them using modern deep-learning tools.
Key Objectives
The authors aim to:
- Explain well-known predictive coding models from neuroscience in plain terms.
- Identify common connection patterns—who sends predictions, who sends errors—across models.
- Introduce a simple “protocol” (called the Rao–Ballard protocol) that describes how information should flow in predictive coding systems.
- Show how these ideas fit into deep learning, including examples like predicting the next frame in a video.
How the Research Was Done
This is a review and concept paper rather than a single experiment. Here’s the approach in everyday language:
- The authors study several important predictive coding models from the brain literature and point out how they pass information between parts (layers).
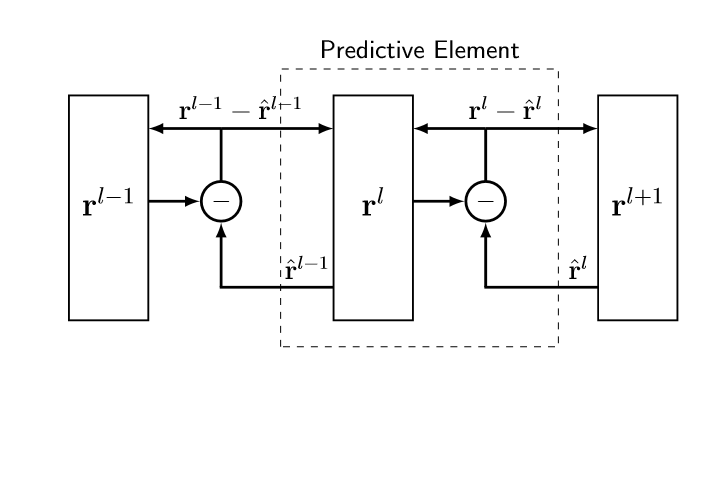
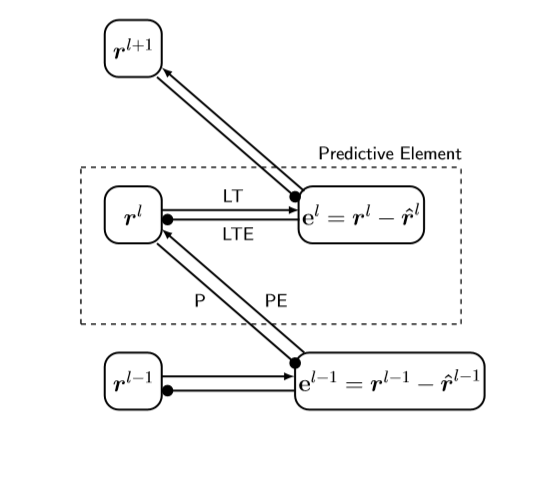
- They describe a standard wiring pattern (the Rao–Ballard protocol) where:
- Predictions flow down from higher layers to lower layers.
- Prediction errors flow up from lower layers to higher layers.
- Specific “modules” only send certain kinds of signals (e.g., prediction modules don’t send errors upward).
- They re-express these ideas using deep-learning components: things like convolutional networks (good at images) and LSTMs (good at remembering over time), so predictive coding can be tested in modern tools.
- They discuss two main styles of predictive coding: 1) Higher layers try to reconstruct the lower layer’s activity (Bayesian predictive coding). 2) Higher layers try to predict the lower layer’s error (used in video prediction models like PredNet).
Core Idea: Predict and Correct
Imagine the brain as a smart guesser. It forms a guess (prediction) about what the eyes will see next. When new sensory data arrives, it compares guess vs. reality. The “surprise” (prediction error) is used to adjust the internal model so future guesses get better. If the brain already has a good default prediction, it only needs a small update to represent the present scene—saving effort and bandwidth.
The Rao–Ballard Protocol (Simple Wiring Rules)
Think of each “layer” in the system as two teams:
- A representation team (what the layer thinks is going on).
- An error team (how wrong the prediction was).
The rules:
- Predictions go down from higher representation to lower representation.
- Errors go up from lower error to higher representation.
- Representation and error teams only talk to their opposite type, not to the same type across layers. This gives a clear checklist to test whether a deep-learning model is truly doing predictive coding.
Models Reviewed (in simple terms)
These short summaries introduce how each model works and why it matters:
- Rao & Ballard (1999):
- A classic brain-inspired model showing how feedback (top-down predictions) can explain “context effects” in vision.
- Example: some visual neurons fire less when a line gets too long (end-stopping). The model shows this can happen because higher layers “explain away” part of the signal using broader context.
- Learning tries to reduce prediction error over time.
- Spratling’s models (2008–2017):
- Reformulates predictive coding using “non-negative matrix factorization” (NMF), which builds parts-based representations (think assembling faces from eyes, nose, mouth—like LEGO pieces).
- Uses “divisive modulation” (ratios instead of differences) to measure error, which can be more biologically plausible and keeps signals non-negative (like neural firing rates).
- Friston’s Free Energy framework:
- A comprehensive mathematical theory that seeks to explain brain function by minimizing “free energy”—a quantity related to prediction error weighted by how certain you are.
- Uses Bayesian ideas with priors (expectations) to handle tricky, ambiguous situations where many causes could explain the same sensory input.
- Provides rules for both adjusting the current guess (inference) and updating model parameters (learning), again driven by prediction errors.
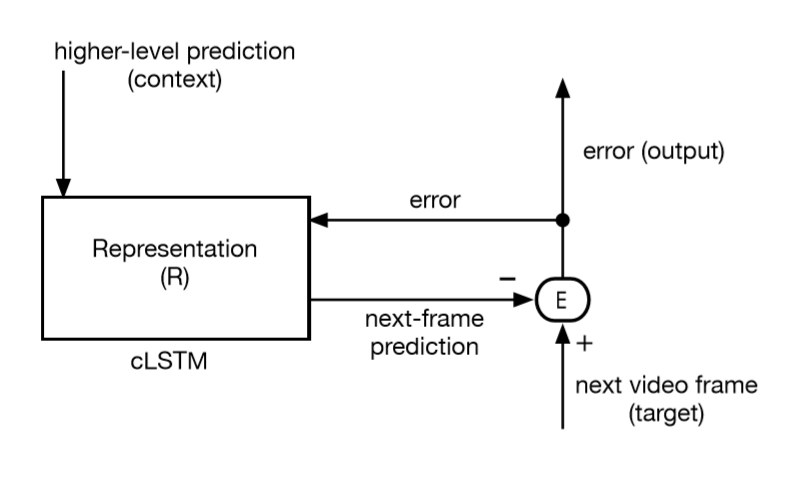
- Deep-learning versions (e.g., PredNet):
- Modern networks like PredNet predict the next frame in a video by combining error modules with convolutional LSTMs (which remember patterns over time).
- These systems bring the predictive coding idea into practical AI, using standard libraries and code.
Main Findings and Why They’re Important
Here are the main takeaways, written in accessible terms:
- Predictive coding always relies on feedback: higher layers send predictions downward, lower layers send errors upward. This structure appears across many models and matches how the cortex has lots of feedback connections.
- Prediction errors drive learning: the model improves itself by noticing and fixing what it got wrong. That makes learning “unsupervised”—it can learn from raw streams of data without needing labels.
- A common protocol (Rao–Ballard) helps judge whether deep-learning models are truly predictive coding: do they use top-down predictions and bottom-up errors in the right way?
- There are different ways to compute error:
- Subtraction (actual minus predicted).
- Division (actual divided by predicted). Each choice has different biological and computational pros and cons.
- Deep learning can implement predictive coding effectively:
- Convolutional networks and LSTMs can be wired to follow predictive coding rules.
- Models like PredNet show strong results in tasks like video frame prediction.
- Open issue: bandwidth of feedback. While predictive coding saves bandwidth by sending errors forward, feedback sometimes sends rich, full predictions downward, which might still be costly. The paper suggests studying this with “spiking” models to measure information transfer more precisely.
Implications and Potential Impact
- For neuroscience: Predictive coding offers a unified way to think about how the cortex might work—using expectations to make sense of noisy, complex sensory data, and using errors to improve over time.
- For AI:
- Better unsupervised learning: models can learn useful internal representations just by predicting streams of data (images, sounds, videos).
- Improved performance on real tasks: video prediction, anomaly detection, object recognition, and more.
- Smarter architectures: adding feedback (not just feedforward) can make models more powerful and more brain-like.
- For future research:
- Use the Rao–Ballard protocol as a checklist to design and evaluate predictive coding networks in deep learning.
- Explore different error computations and parts-based representations for better biological realism and practical performance.
- Measure information use with spiking models to balance accuracy with efficiency.
In short, the paper shows that a brain-inspired idea—predictive coding—can be clearly described, organized, and brought into modern deep-learning frameworks. This makes it easier to build, test, and improve models that learn by predicting and correcting themselves, just like a smart guesser getting better with experience.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s reviewed architectures (e.g., Rao–Ballard protocol, predictive elements, PredNet with convolutional LSTMs), learning rules (prediction-error-driven updates, NMF/divisive input modulation), and workflows (unsupervised predictive training in deep-learning frameworks).
- Video next-frame prediction for streaming optimization and compression
- Sector: Media/Telecom
- Tools/Workflow: PredNet-like convolutional LSTM stacks trained unsupervised on platform-specific video; serve predicted frames or transmit residuals; integrate with codecs to compress by sending prediction errors rather than full frames.
- Assumptions/Dependencies: High-quality, domain-specific video datasets; stability of recurrent training; compatibility with existing codec pipelines; sufficient edge compute.
- Video anomaly detection via prediction-error maps
- Sector: Security, Manufacturing, Retail, Transportation
- Tools/Workflow: Train predictive coding networks on “normal” footage; use magnitude/structure of prediction errors as anomaly scores; thresholding or scoring with precision-weighted errors (free-energy perspective).
- Assumptions/Dependencies: Representative “normal” data; calibrated thresholds; drift monitoring; edge deployment footprint.
- Unsupervised pretraining for downstream classification
- Sector: Computer Vision, Software
- Tools/Workflow: Pretrain feature hierarchies with predictive losses (RB protocol: top-down reconstruction + feedforward prediction errors); fine-tune with small labeled sets.
- Assumptions/Dependencies: Abundant unlabeled streams; robust handoff from predictive to discriminative objectives; careful hyperparameter tuning.
- Parts-based, interpretable feature learning with divisive input modulation
- Sector: Healthcare (medical imaging), Compliance-focused AI, Education
- Tools/Workflow: Spratling’s NMF-inspired predictive coding (non-negative activations, divisive error) to learn subparts (e.g., anatomical components, device features); report part activations for interpretability.
- Assumptions/Dependencies: Non-negativity constraints, appropriate pre/post-processing; acceptance of additive composition assumptions; training stability of multiplicative updates.
- Sensorimotor cancellation and artifact suppression
- Sector: Robotics, AR/VR
- Tools/Workflow: Use top-down predictions to subtract self-generated sensory effects (predictive elements send priors; error units gate residuals); improve control and perception under movement.
- Assumptions/Dependencies: Real-time feedback loops; accurate priors from recent action history; latency constraints.
- Neuroscience model replication and hypothesis testing
- Sector: Academia (Computational Neuroscience)
- Tools/Workflow: Implement RB protocol to reproduce V1 context effects (e.g., end-stopping via broader-context feedback); compare model behavior to empirical data.
- Assumptions/Dependencies: Experimental stimuli and datasets; precise mapping of model layers to cortical areas; parameter fitting.
- EEG and physiological signal modeling
- Sector: Healthcare, Neurotech
- Tools/Workflow: Free-energy predictive coding to model evoked responses; use precision-weighted prediction errors as features for event detection or monitoring.
- Assumptions/Dependencies: Curated EEG/physio datasets; clinically appropriate evaluation; regulatory and validation requirements.
- Time-series quality monitoring and anomaly detection
- Sector: Finance, Energy, IoT Ops
- Tools/Workflow: LSTM-based predictive coding for forecasting; flag deviations using error units (residuals) for alerting and root-cause workflows.
- Assumptions/Dependencies: Stationarity or controlled drift; change-point handling; robust error calibration.
- Edge IoT bandwidth reduction using feedforward residuals
- Sector: IoT, Energy
- Tools/Workflow: Run local predictors; transmit only feedforward prediction errors to the cloud (reduce upstream bandwidth); periodic model refresh from server.
- Assumptions/Dependencies: Good local predictors; network constraints; note the paper’s caveat on feedback bandwidth—use asymmetric (feedforward-only) residual transmission for practicality.
Long-Term Applications
These applications require further research, scaling, tooling, or hardware development to realize the full benefits of hierarchical predictive coding and feedback-rich architectures as articulated in the paper (e.g., solving bandwidth challenges, robust priors/precision estimation, standardized training protocols).
- General-purpose feedback-rich deep architectures
- Sector: Software/AI Platforms
- Tools/Workflow: Standardized modules implementing the Rao–Ballard protocol (explicit error and representation nodes; P/PE/LT/LTE link taxonomy), integrated into PyTorch/TensorFlow; training recipes for stability.
- Assumptions/Dependencies: Community benchmarks; regularization for feedback networks; reproducibility across tasks.
- Neuromorphic predictive-coding hardware (spiking implementations)
- Sector: Semiconductors, Energy-Efficient AI
- Tools/Workflow: Spiking versions of predictive elements that encode and transmit residuals; measure and exploit true information-transfer reductions (addressing bandwidth concerns raised in the paper).
- Assumptions/Dependencies: Hardware R&D, spike-based learning rules for prediction errors, toolchain support, application-specific tuning.
- Active inference controllers for autonomous systems
- Sector: Robotics, Autonomous Vehicles
- Tools/Workflow: Friston-style free energy minimization for action selection; precision-weighted errors drive perception-action loops and planning under uncertainty.
- Assumptions/Dependencies: Robust generative models (priors and observation models), safety certification, real-time guarantees, extensive validation.
- Multimodal hierarchical predictive coding
- Sector: Embodied AI (Vision–Audio–Proprioception), Assistive Tech
- Tools/Workflow: Cross-modal RB protocol stacks predicting lower-level representations across modalities; handle occlusion/non-uniqueness via learned priors and precisions.
- Assumptions/Dependencies: Large curated multimodal datasets; scalable training; careful synchronization and latency management.
- Bidirectional residual-networking protocols
- Sector: Networks/Teleoperation/Cloud Robotics
- Tools/Workflow: Communication standards that exchange priors and residuals both ways (feedforward residuals plus compressed feedback predictions), reducing overall bandwidth.
- Assumptions/Dependencies: Protocol design, latency constraints, security; solving feedback bandwidth issue identified in classical models.
- Clinical decision support using precision-weighted errors
- Sector: Healthcare
- Tools/Workflow: Use precision-weighted prediction errors as early-warning biomarkers across streaming vitals/EEG; decision support integrated with EHR.
- Assumptions/Dependencies: Clinical trials, regulatory approval, robust calibration across populations and devices.
- Privacy-preserving on-device unsupervised learning
- Sector: Mobile/Edge AI
- Tools/Workflow: Predictive coding losses for continual learning on-device; share only model updates or error statistics; improve personalization without raw data upload.
- Assumptions/Dependencies: Efficient on-device training, federated protocols, robustness to non-iid data, privacy/legal compliance.
- Open-source libraries and evaluation rubrics
- Sector: Academia/Policy/Education
- Tools/Workflow: Libraries implementing predictive elements, divisive input modulation, and free-energy updates; rubrics using the Rao–Ballard protocol to assess “predictive coding” claims; courseware and benchmarks.
- Assumptions/Dependencies: Community governance, maintenance funding, consensus on metrics and protocols.
Collections
Sign up for free to add this paper to one or more collections.