- The paper demonstrates that reformulating contrastive learning objectives via mutual information significantly stabilizes the learning process.
- It introduces VINCE, a generalized InfoNCE estimator that enhances negative sample selection and improves representation quality.
- Experiments on CIFAR10 and ImageNet show that tailored data augmentations and view selections boost performance across tasks.
Introduction to Contrastive Learning
Contrastive learning is a powerful paradigm for unsupervised learning in computer vision, aiming at extracting meaningful visual representations without labeled data. This paper, "On Mutual Information in Contrastive Learning for Visual Representations" (2005.13149), explores the theoretical foundations of contrastive algorithms through mutual information and proposes improved objectives. By treating every example as its label, contrastive methods like Instance Discrimination (IR), Local Aggregation (LA), and Contrastive Multiview Coding (CMC) have marked success, competing closely with supervised methods.
The study employs mutual information as a central tool for understanding the learning dynamics of various contrastive algorithms. Mutual information measures the statistical dependence between two variables, which in this context pertains to two "views" of an image created through data augmentation. The paper demonstrates that contrastive objectives are equivalent to maximizing lower bounds on mutual information. The InfoNCE estimator is generalized with a focus on negative sampling from challenging contrasts, providing insights into algorithm design decisions.
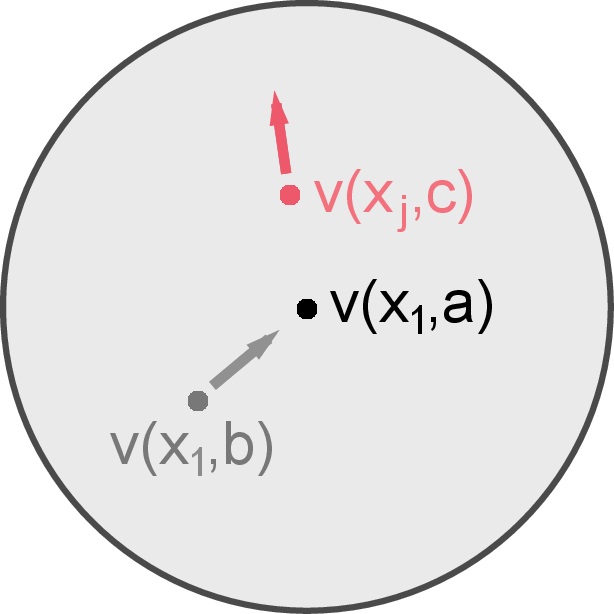
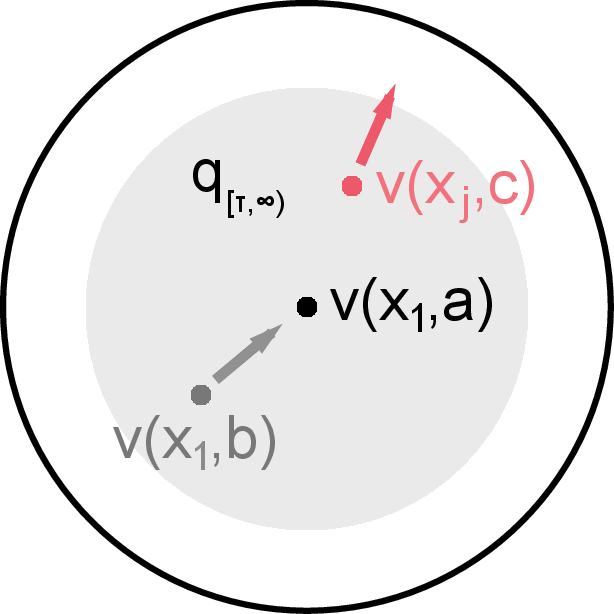
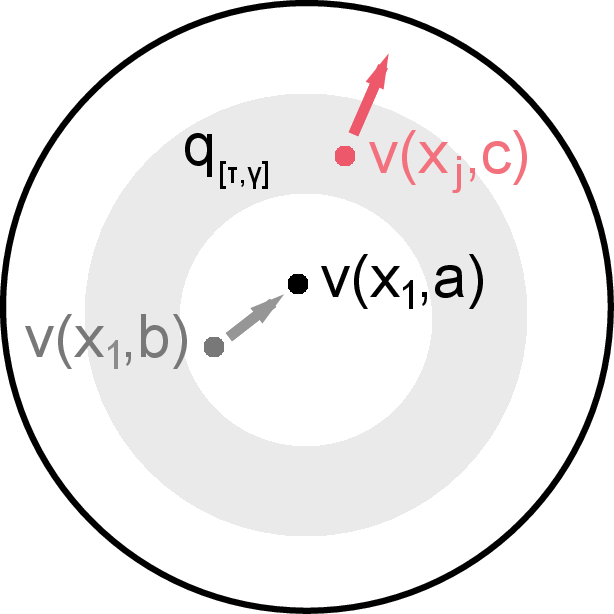
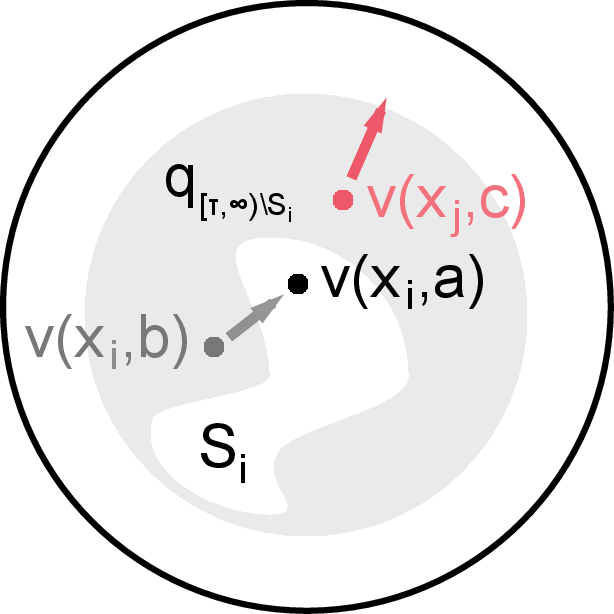
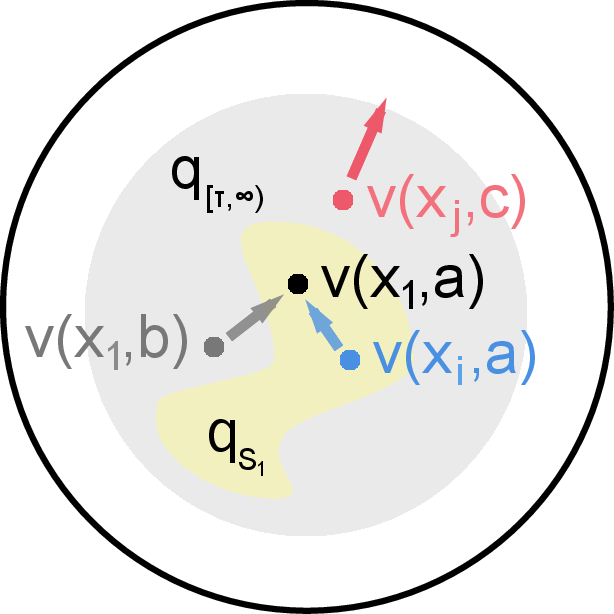
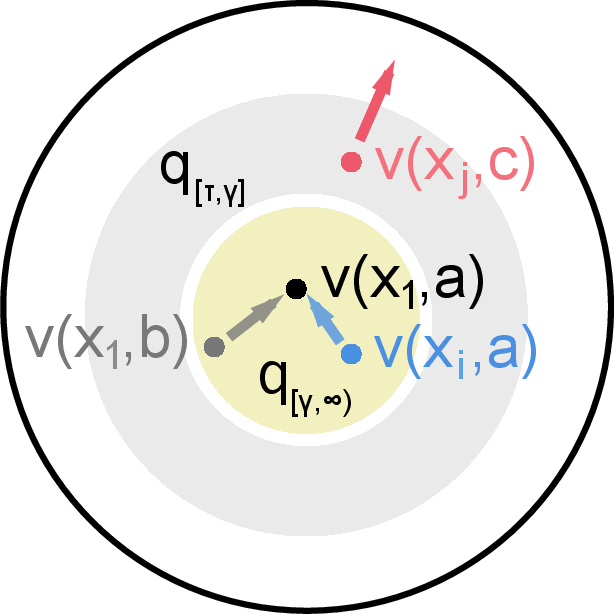

Figure 1: Illustration of IR showing how mutual information helps generalize the InfoNCE objective by selecting effective negative samples.
The paper claims that reformulating learning objectives using mutual information simplifies and stabilizes them, potentially eliminating tweaks such as softmax approximation adjustments seen in IR. The adoption of InfoNCE without approximations proves not only more stable but equally effective.
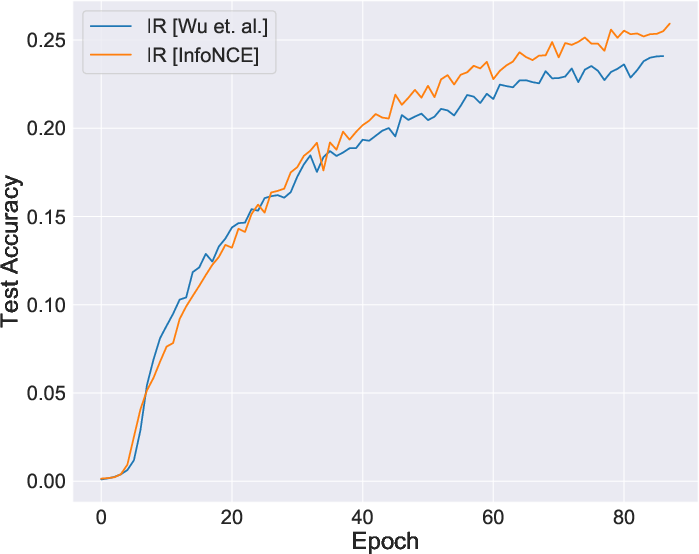
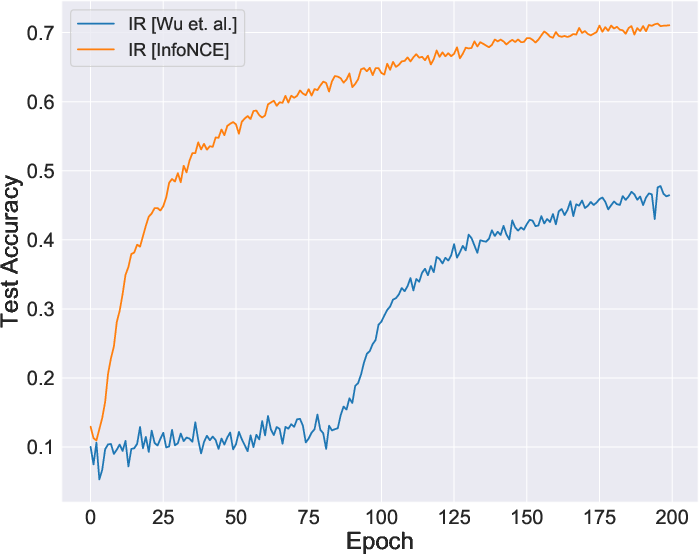
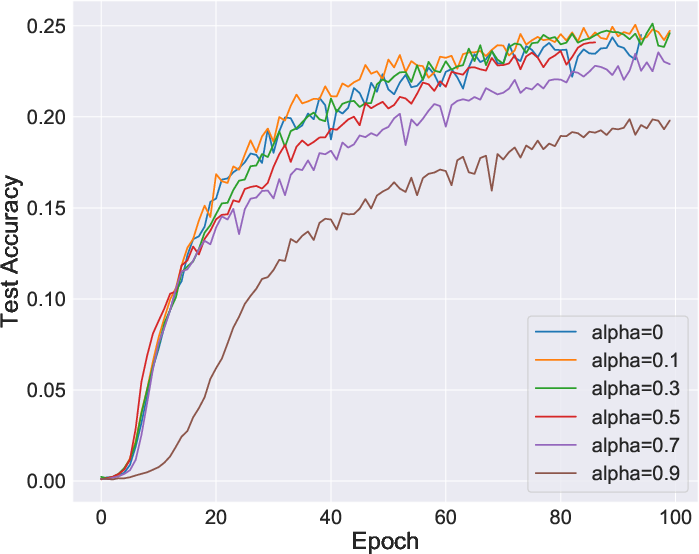
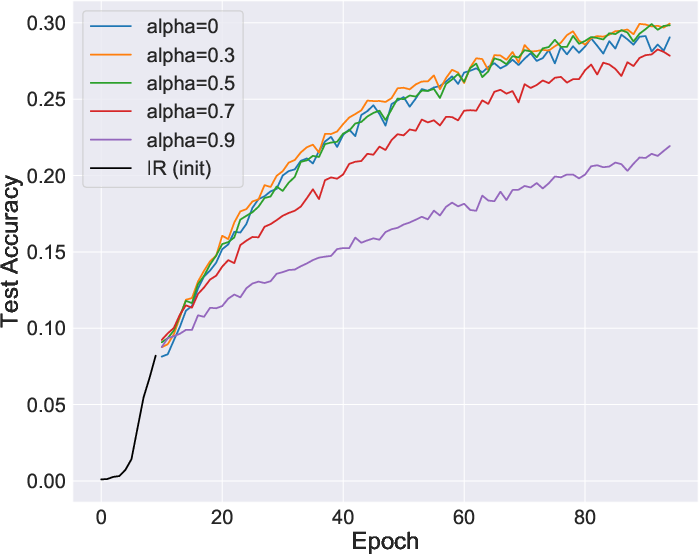
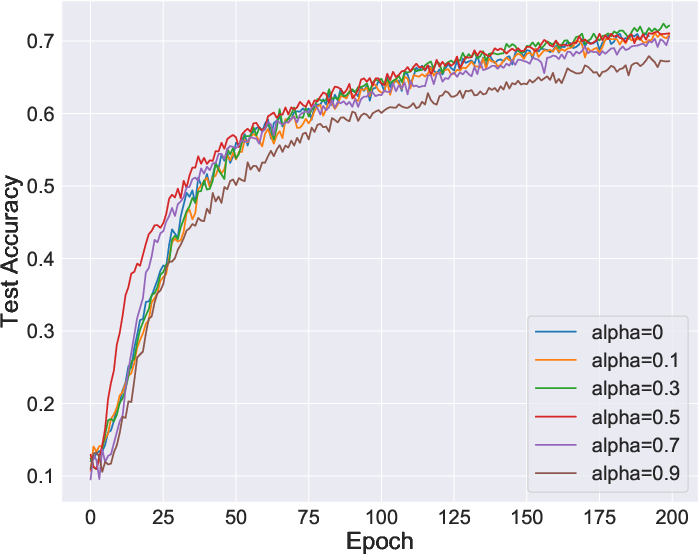
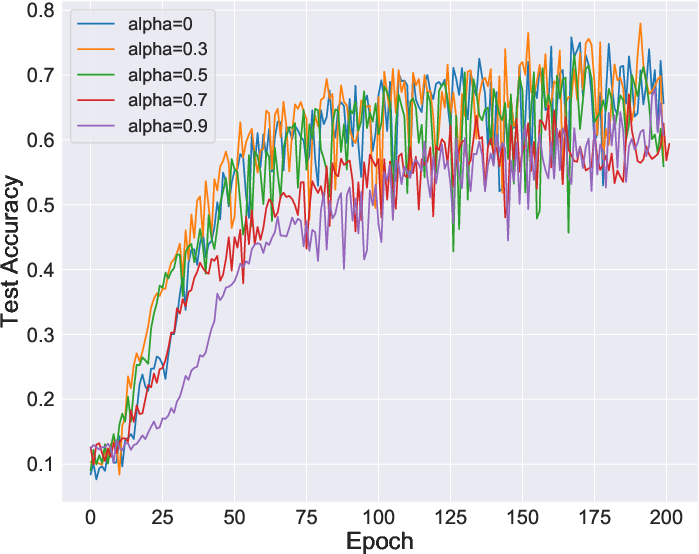
Figure 2: Comparative stability during learning, showing improvements when using InfoNCE directly.
Furthermore, memory banks utilized in IR for storing representations can be counterproductive, as training may converge without them by utilizing views directly. This aligns well with findings from SimCLR on the non-necessity of memory banks when using large batch sizes.
View Set Importance in Representation Quality
A significant revelation from this paper is the pivotal role of data augmentations or "views" in the strength of learned representations. Without augmentations, the IR objective reduces to a trivial instance, incapable of capturing the nuances necessary for useful generalization. Thus, learning success hinges on the choice of data transformations that encourage collisions amongst views, enriching mutual information.
Enhancing Local Aggregation with VINCE
Through an innovative approach, the paper generalizes the InfoNCE bound to account for samples chosen from specific distributions—coined VINCE (Variational InfoNCE)—enabling tailored sampling strategies rather than relying on purely independent draws. This approach rigorously connects Local Aggregation to mutual information, explaining the clustering benefits seen in LA and paving the way for algorithms such as Ring and Cave Discrimination.

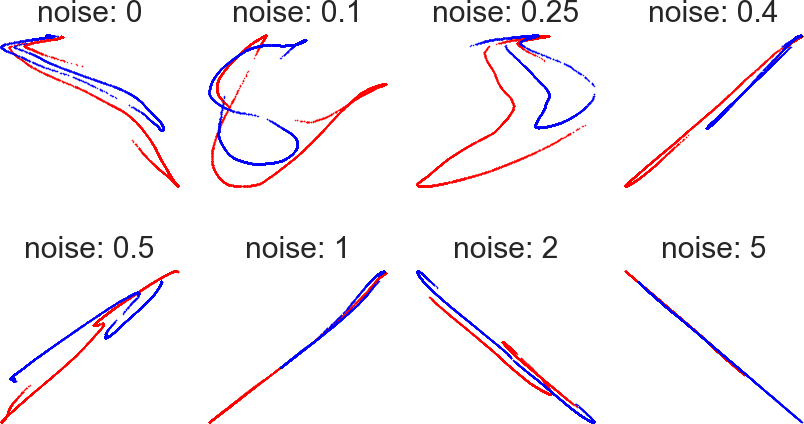
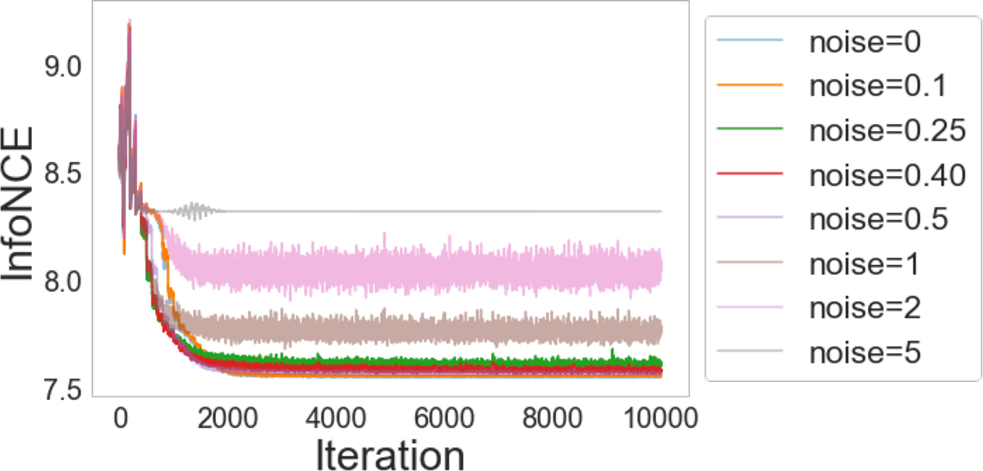
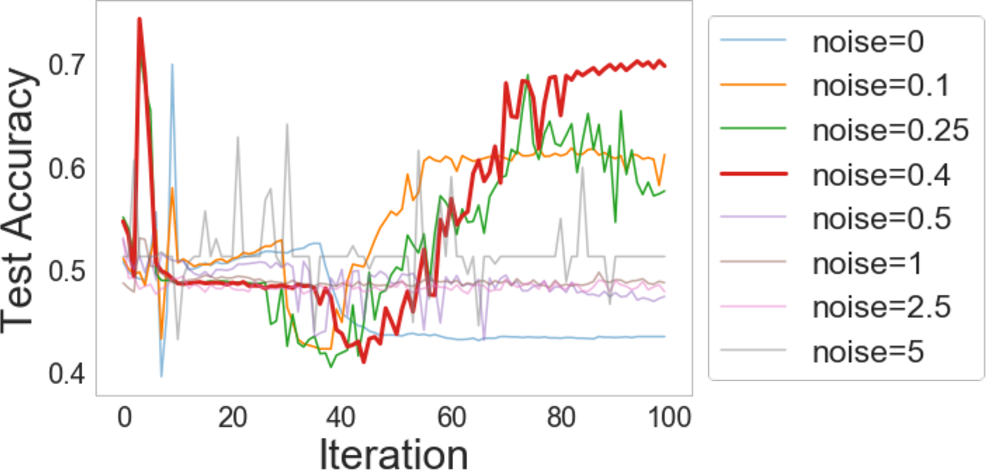
Figure 3: Visualization of sampled views showcasing the enrichment provided by intelligent augmentation strategies.
Experimental Insights and Comparisons
Experiments reveal that intelligent negative sample selections markedly improve outcomes, as evidenced by tests on CIFAR10 and ImageNet. The proposed formulations such as RING and CAVE outperform traditional IR and LA methods across multiple tasks, including classification, object detection, and instance segmentation.
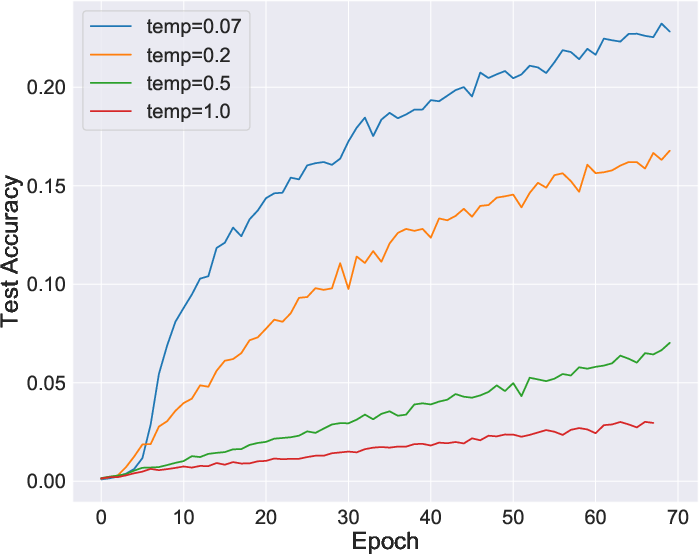
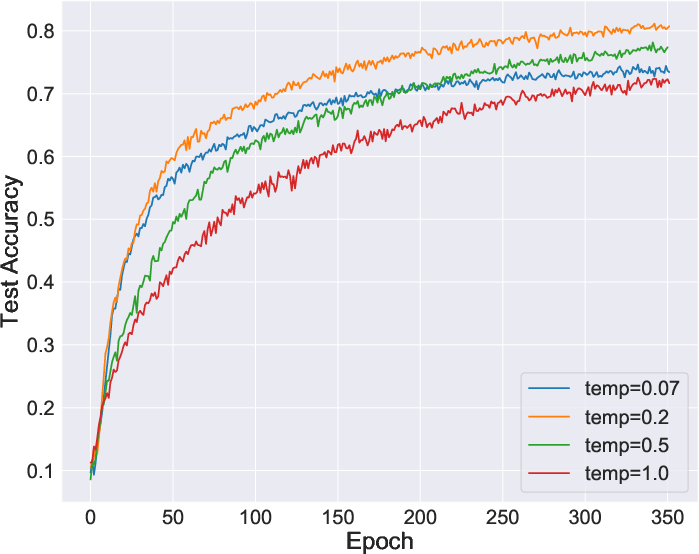
Figure 4: Enhanced performance metrics for Imagenet classification using tailored negative sample distributions.
Conclusion and Future Directions
The integration of mutual information offers not only theoretical coherence but also practical elevation for contrastive learning algorithms. This paper's insights point toward simpler yet robust designs, focusing on better data transformations and strategic sample choices. The exploration of what constitutes optimal view sets and deeper studies into tightening MI bounds are promising future avenues.
In summary, this research deepens our understanding and capability to harness unlabelled data efficaciously—the broader impact being more accessible and deployable machine learning models.