- The paper proposes Bourbon, using Greedy Piecewise Linear Regression to apply machine learning selectively on stable LSM components.
- It employs a cost-benefit analyzer to dynamically determine which sstable files benefit from learned indexing, optimizing resource use.
- Evaluation shows lookup improvements between 1.23× and 1.78×, demonstrating enhanced performance in both in-memory and SSD-backed environments.
From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees
The paper "From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees" presents an innovative approach to integrating machine learning into Log-Structured Merge Trees (LSMs) to enhance lookup operations. The authors propose Bourbon, a new LSM design that employs learned indexes to optimize the lookup process, thereby reducing latency and maintaining high throughput even under write-intensive workloads.
Introduction to Learned Indexes in LSMs
Learned indexes have been recognized for their ability to replace traditional indexing structures in databases with machine learning models that predict key locations, offering potential improvements in efficiency and space utilization. The challenge addressed in this paper is the application of learned indexes in LSMs, which are inherently optimized for write-heavy workloads. Traditional learned indexes are typically static and read-optimized, posing difficulties when applied to dynamic data structures like LSMs.
Bourbon's Architecture
Bourbon leverages Greedy Piecewise Linear Regression (PLR) to model key distributions within LSM structures, choosing this approach for its balance between accuracy and computational overhead. The critical insight is applying learning only to parts of the LSM that are stable or rarely modified, namely the lower levels of the tree where data tends to be immutable once written.
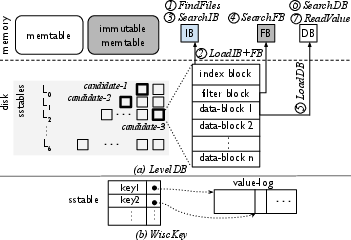
Figure 1: Comparison of data organization and lookup processes in LevelDB and WiscKey.
Initially buffering writes in memory and deferring to static learning on stable levels, Bourbon avoids frequent retraining on higher, volatile levels that are subject to frequent updates.
Implementation Details
Bourbon implements a selective learning strategy, guided by empirical analysis of sstable lifetimes within WiscKey, a precursor LSM system that demonstrated significant performance improvements over traditional databases like LevelDB and RocksDB by separating keys and values. By understanding the behavior and lifetimes of sstable files, Bourbon strategically applies machine learning to maximize lookup efficiency without incurring high resource costs for retraining models unnecessarily.
Bourbon employs a cost-benefit analyzer to decide dynamically which files to learn based on their stability and the frequency of lookups they serve. This ensures that computational resources are efficiently utilized, aligning with the system’s primary goals of performance enhancement and resource optimization.

Figure 2: Latency breakdown for lookup operations with and without learned indexes in memory and storage-backed scenarios.
Evaluation and Results
The evaluation of Bourbon involves a series of experiments comparing lookup performance across synthetic and real-world datasets. Bourbon shows lookup improvements of between 1.23× and 1.78× compared to baseline systems, with the highest gains observed when data is cached in memory or stored on fast storage devices like SSDs. The introduction of learned indexes proves particularly beneficial in memory-intensive environments and emerging storage technologies with low access latencies.
Implications and Future Directions
The findings suggest that Bourbon represents a significant step towards embedding learned models within system architectures that must balance read and write performance. This work opens the door for further exploration into integrating machine learning into broader classes of storage systems, particularly those like B-trees and Bϵ-trees, which also manage write-heavy workloads.
Moreover, the documented guidelines for when and how to apply learning within LSM structures provide a foundation upon which future systems can build, possibly exploring alternative learning models or hybrid approaches that further refine the balance between performance and resource utilization.
Conclusion
Bourbon offers a compelling model for integrating machine learning into LSM trees, particularly for systems where lookup efficiency can markedly impact overall performance. This approach illustrates a shift toward more intelligent indexing within database systems, aligning with the broader trend of adopting machine learning methodologies to enhance traditional data structures. The potential applications of this work extend beyond LSMs, promising future advancements in the efficiency and capability of data storage systems.