- The paper presents a novel algorithm that uses rank centrality and kernel density methods to estimate skill distributions with near-optimal error bounds.
- It leverages pairwise competition data from sports and finance to reveal competitive dynamics and performance trends.
- The method balances bias-variance tradeoffs in the kernel density estimation process, providing actionable insights for diverse applications.
Estimation of Skill Distributions
Introduction
The research paper "Estimation of Skill Distributions" (2006.08189) addresses the problem of analyzing skill distributions derived from pairwise competitions among agents, such as individuals or teams. The authors propose a novel algorithm to determine the distribution and estimate skill levels using data from these tournaments. The underlying model revolves around the Bradley-Terry-Luce (BTL) system, which estimates the likelihood of an agent's victory based on skill level ratios. Through a combination of kernel density estimation and rank centrality techniques, the paper achieves near-optimal minimax mean squared error rates under specific model assumptions. The implications of this research extend to various domains, including sports and finance.
Methodology
The approach combines statistical estimation procedures with recent advances in spectral methods for ranking systems, leveraging Parzen-Rosenblatt kernel density estimation. Here are the principal components of the methodology:
- Pairwise Data Sampling: Agents are randomly selected and compete in pairwise matches, generating win-loss data.
- Skill Parameter Estimation: Utilizing the rank centrality algorithm, the method estimates individual skill parameters. This spectral method treats skill parameters as an invariant distribution of a Markov chain, where skill levels determine transition probabilities.
- Kernel Density Estimation: With these skill parameter estimates, the algorithm employs kernel density estimation to deduce the underlying distribution of skills, carefully adjusting bandwidth for bias-variance tradeoffs.
- Minimax Error and Lower Bounds: The paper establishes minimax optimality of their estimation procedure using adapted versions of Fano's method, while also characterizing fundamental limits through information theoretic bounds.
Algorithm
The core algorithm operates in two stages:
- Stage 1: Skill Estimation
Using observations to form a stochastic matrix, rank centrality identifies the leading eigenvector representing estimated skills.
plain text
Estimation of skill using rank centrality:
- Compute observation matrix Z.
- Construct stochastic matrix S from Z.
- Determine invariant distribution via spectral analysis.
1
2
3
|
- **Stage 2: Density Estimation**
Apply kernel methods to derive the skill density, adjusting bandwidth for optimally balancing errors.
|
plain text
Density estimation using kernel methods:
- Set bandwidth h optimally.
- Estimate skill density from derived skill parameters using kernel smoothing.
Experiments and Results
The paper's experimental section illustrates the application of their algorithm to datasets from sports tournaments and mutual fund performance. Below are the main insights:
- Sporting Events: Skill distributions reveal competitive dynamics, such as unexpected matches and tightly contested tournaments, corroborating fan experiences with quantitative data.
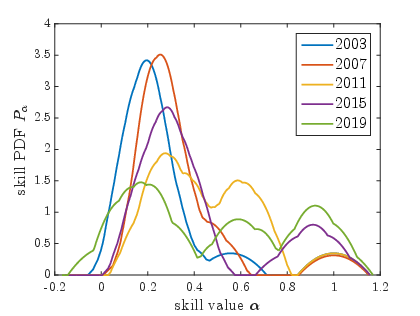
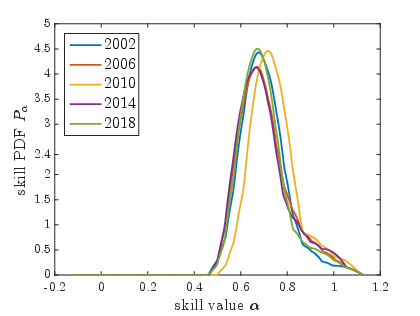
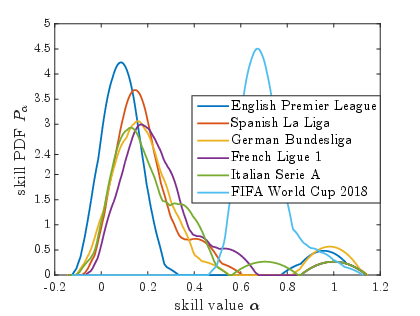
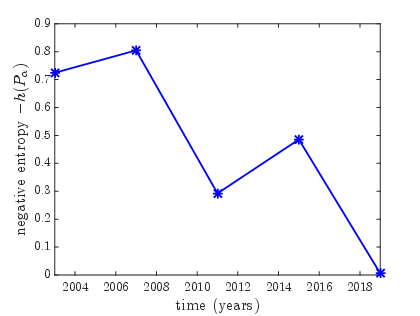
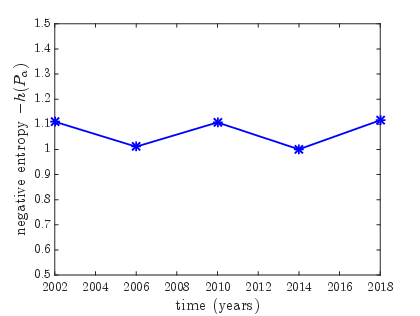
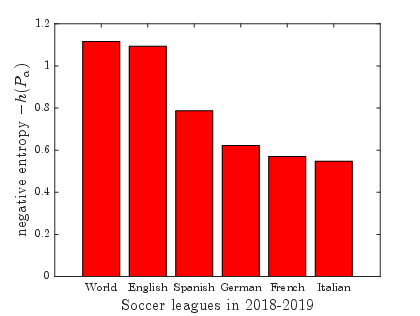
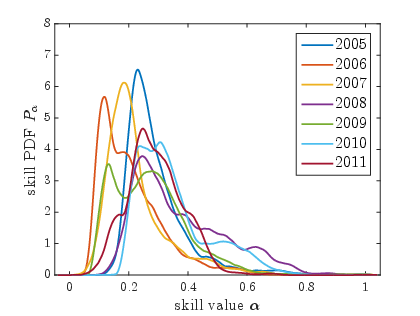
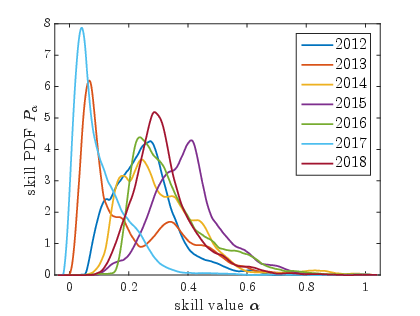
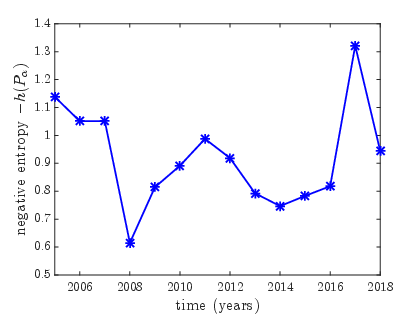
Figure 1: ICC Cricket World Cups
- Mutual Funds: Analysis of financial data shows fluctuations in the skill distribution of funds over time, pinpointing moments like the 2008 financial crisis to observe concordant shifts in fund performance quality.
Implications
This study extends the theoretical framework of skill distribution models into practical datasets, offering profound insights into areas like sports analytics and financial market performance. These results underscore the potential for statistical learning methods such as BTL in diverse real-world applications: predicting game outcomes, assessing competitive fairness, and evaluating team or individual rankings. A broader impact might involve tools for regulatory standards on competitions perceived as skill-based vs. chance-based.
Conclusion
The paper presents a statistically efficient and computationally feasible algorithm to address skill estimation via pairwise data. The findings have practical utility, from sports to financial assessments, providing a robust methodology for evaluating skill distributions and trends. Future work could explore enhanced computational techniques for skill measurement, integrating deeper insights into skill dynamics across varied industries.