- The paper demonstrates that the MBAF layer substantially enhances multi-modal fusion by capturing long-term dependencies using a memory mechanism.
- It introduces an attentive architecture that outperforms naive fusion techniques, achieving higher accuracy on benchmark datasets like IEMOCAP and PhysioNet-CMEBS.
- Extensive ablation studies reveal the sensitivity of memory size and hyperparameter tuning, highlighting the balance between model complexity and performance gains.
Memory Based Fusion for Multi-Modal Deep Learning
This essay provides an expert analysis of the methodologies and empirical findings presented in the paper "Memory Based Fusion for Multi-modal Deep Learning" (2007.08076). The paper introduces a methodical approach for enhancing multi-modal data fusion in deep learning applications using memory-based attentive fusion (MBAF). Emphasizing upon the need to move beyond naive fusion techniques, the authors propose a novel architecture that significantly improves upon the generalization and performance of multi-modal fusion, demonstrating its effectiveness across various datasets and applications.
Introduction to Multi-Modal Fusion Challenges
In the multi-modal learning paradigm, information from different sensors or data streams is combined to improve decision-making, as in applications like autonomous driving, emotion analysis, and biometrics. Traditional approaches utilizing naive fusion methods, such as concatenation or summation, fail to capture long-term dependencies between modalities. These simple fusion techniques can lead to suboptimal performance due to their ignorance of temporal dynamics and historical relationships within the data.
Proposed MBAF Layer
The MBAF layer is designed to address these limitations by incorporating long-term dependencies in the fusion process. At the core of this architecture is an explicit memory mechanism that retains important historical interactions between modalities. This is complemented by attentive processing, which evaluates the relative significance of incoming data features over time and space.
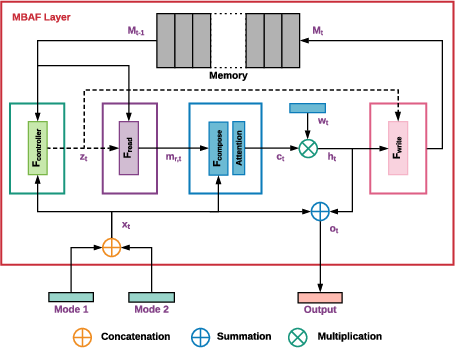
Figure 1: Proposed MBAF layer: Inputs are the dense feature vectors from two modalities, and the output is a feature vector of the same dimension as the concatenation of the input features. The inputs are concatenated and the corresponding memory locations' key is calculated (green box). The resultant key is used to read the memory slot.
The MBAF layer is equipped with modules for controlling, reading, composing, and writing data to and from the memory. The architecture allows for the learning of temporal dependencies, fostering a nuanced understanding of the interplay between different modalities. This sophisticated fusion mechanism outputs a feature vector that integrates both current and historical information, thereby enhancing the subsequent processing layers.
Experimental Evaluation
The authors evaluate the effectiveness of the MBAF layer using two benchmark datasets: the IEMOCAP for emotion recognition and the PhysioNet-CMEBS for physiological signal analysis. The experiments are structured to demonstrate not only the superiority of the MBAF approach over naive fusion but also its universality across domains.
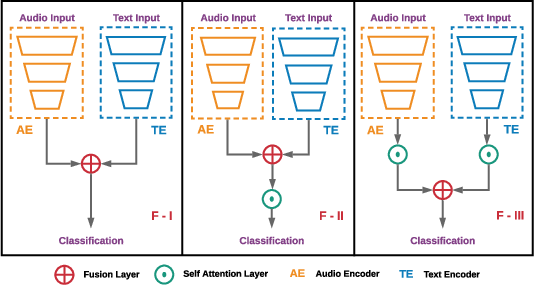
Figure 2: Audio and Text inputs passed through separate encoder networks with resultant dense features processed through the memory-based attentive network (MBAF) for IEMOCAP.
Results on IEMOCAP
The implementation on the IEMOCAP dataset reveals a notable increase in weighted and unweighted accuracy metrics when using MBAF as opposed to naive fusion. This accuracy is a direct consequence of the model's ability to interpret modal data comprehensively, evident from reduced confusion among closely related emotions like 'neutral' and 'happiness.'
Results on PhysioNet-CMEBS
Similarly, the PhysioNet-CMEBS tests indicate a marked improvement in recognizing physiological states. The performance gains are attributed to the MBAF layer's capacity to discern and utilize historical sensor data effectively, which is critical in physiological signal fusion where temporal dependencies are significant.
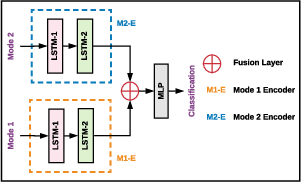
Figure 3: Data from two modalities passed through LSTM architectures and fused via MBAF, with output improvements on PhysioNet-CMEBS.
Ablation Studies and Hyperparameter Sensitivity
Extensive ablation studies conducted as part of the paper reveal the impacts of varying memory size, computational configurations, and hyperparameter tunings. While the memory size directly influences performance, larger memories do not necessarily equate to better results due to the increased complexity in selecting relevant stored information. The experiments also evaluate different methods for memory access, such as naive attention versus cross-attention, with the findings favoring the former due to the pronounced differences in input modalities.
Conclusion
The paper elucidates the advantages of a memory-augmented approach to multi-modal data fusion in deep learning. By strategically leveraging historical data and modality interdependencies, MBAF surpasses traditional methods in accuracy and robustness, as demonstrated in the experiments on IEMOCAP and PhysioNet-CMEBS datasets. This architecture's potential extends to various new applications and challenges in multi-modal machine learning, where understanding time-sensitive data interactions is paramount. Future work could explore the adaptation to real-time systems or further reduction in computational overhead without compromising efficacy.