- The paper establishes a fixed-point formulation for NCELM that guarantees global convergence via Banach's fixed-point theorem.
- The method integrates an NCL penalty into ELM ensembles to promote diversity while ensuring unified convergence.
- Empirical results confirm that tuning the lambda parameter optimizes both convergence speed and ensemble prediction accuracy.
Global Convergence of Negative Correlation Extreme Learning Machine
This essay reviews the "Global convergence of Negative Correlation Extreme Learning Machine" and discusses the mathematical conditions that ensure its global convergence. The central theme focuses on transforming the training process of NCELM into a fixed-point problem, allowing for proof of convergence via Banach's fixed-point theorem.
Introduction to Negative Correlation Extreme Learning Machine
The Negative Correlation Extreme Learning Machine (NCELM) builds upon the existing Extreme Learning Machine (ELM) by integrating Negative Correlation Learning (NCL). The technique involves constructing ensemble learners from base ELM models which are initialized with random hidden layer weights. NCELM leverages NCL by incorporating a penalty for correlation among the ensemble learners, iterating to refine each base model until convergence occurs.
Negative Correlation Learning Framework
The NCELM method applies an NCL penalty to encourage diversity in ensemble outputs. This penalty term, λ, is adjustable and directly influences the degree of correlation allowed between predictions of ensemble members. The paper demonstrates that the application of NCL within ELM requires iteration to correct ensemble outputs, ensuring minimized error and maximized diversity.
Banach Fixed-Point Theorem
The Banach fixed-point theorem provides a foundation for proving convergence. It states that a contraction mapping on a complete metric space has a unique fixed-point. The paper demonstrates that the conditions for NCELM can be reformulated as a contraction mapping, thus validating convergence through this theorem.
By defining a series of mappings and metric spaces, the paper translates the problem of ensemble convergence into a sequence of fixed-point iterations. The key element of this formulation is the matrix inversion process, which updates base learner weights iteratively.
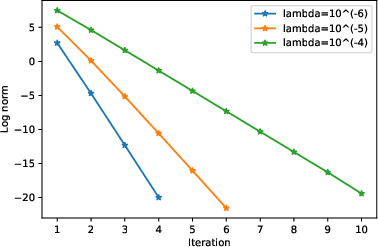
Figure 1: Norm of between the iterations, compared with different values of λ.
The contraction mapping is demonstrated through the modification of the ensemble’s output and each base learner’s parameters. The iterative nature of the solution is framed such that, upon satisfying certain conditions on λ (as verified through illustrative empirical evaluations, such as Figure 1), the ensemble converges to an optimal solution.
Discussion of Convergence Conditions
The paper sets practical bounds on the parameter λ to guarantee that the fixed-point condition holds for NCELM. This ensures that the ensemble does not collapse into suboptimal or disparate outputs, thereby achieving a balanced ensemble with minimal mutual information shared among individual models.
Practical Implications and Numerical Simulation
Empirical validation showcased in the study demonstrates the efficacy of the proposed mathematical constructs. Convergence behavior is ascertained across varying λ values with the norm of coordinate differences between iterations serving as an empirical indicator of convergence velocity.
The NCELM framework merits further exploration across diverse classification tasks to evaluate stability under various hyper-parameter configurations and data distributions.
Conclusion
The NCELM's convergence guarantee provides substantial groundwork for deploying ELM-based ensembles in domains demanding high prediction accuracy and model diversity. The extension of fixed-point theory integrations within ensemble methods suggests broader applicability to other ensemble paradigms, opening avenues for innovation within ensemble learning approaches across computational landscapes. Integrating fixed-point convergence checks into routine ensemble training regimes could optimize computational efficiency while retaining robustness and accuracy.