- The paper presents Slim NoC, a novel network topology that reduces port usage using degree-diameter graphs and non-prime finite fields for improved scalability.
- It demonstrates significant energy and area efficiency gains, with up to 33% area reduction and over 55% improvement in energy-delay product compared to traditional designs.
- The design incorporates advanced microarchitectural enhancements like Elastic Links and Central Buffer Routers to achieve low latency and high throughput under varied loads.
Essay: "Slim NoC: A Low-Diameter On-Chip Network Topology for High Energy Efficiency and Scalability" (2010.10683)
Introduction
The research presented in the paper focuses on advancing on-chip network topologies by introducing "Slim NoC". This network design is aimed at substantially improving energy efficiency and scalability, necessary for chips with thousands of cores. By leveraging concepts from graph and number theory, specifically degree-diameter graphs coupled with non-prime finite fields, the Slim NoC architecture innovatively combines minimal port usage with scalability across a large number of cores.
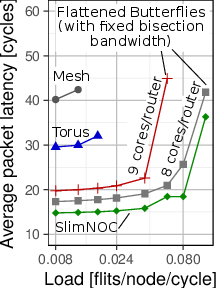
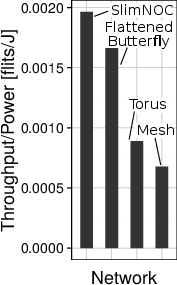
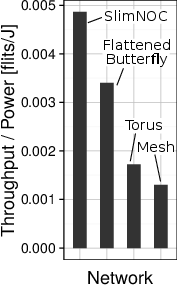
Figure 1: Example advantages of Slim NoC over high- and low-radix NoC topologies (1296 cores); significant improvements in throughput per watt and performance stability.
Design Principles and Architecture
The Slim NoC utilizes a unique combination of degree-diameter limitations and finite fields to produce a low-diameter architecture that effectively reduces the number of ports required. This design consideration translates into significant reductions in static and dynamic power consumption, enhancing both efficiency and scalability.
Network Configuration
A key configuration aspect of Slim NoC involves the deployment of non-prime finite fields to tweak network scalability in alignment with specific architectural constraints such as die dimensions and core count. This results in a structured reduction of switch radix and an optimized setup for maintaining low network diameters and latency across the network.
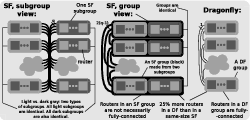
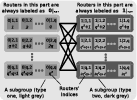
Figure 2: An illustration of the Slim Fly structure and the labeling as well as indices used in the Slim NoC design.
Router Architecture
The Slim NoC’s router architecture incorporates advanced microarchitectural enhancements like Elastic Links and Central Buffer Routers (CBR). By using Elastic Store extensions, the design achieves greater reduction in area and power. Meanwhile, CBRs suppress the need for extensive buffer space and accommodate efficient two-stage routing under low loads.
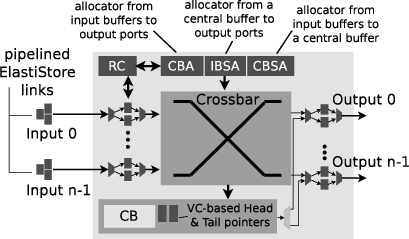
Figure 3: Modifications to the CB router, enhancing Slim NoC’s performance efficiency.
Through extensive experimental evaluations on synthetic and real workloads, the Slim NoC has demonstrated superiority over traditional network topologies like meshes, tori, and high-radix networks:
- Area and Power Efficiency: The network design accomplishes up to 33% less area usage compared to Flattened Butterflies, with significant energy-delay product improvements of over 55%.
- Latency and Throughput: Slim NoC features a low latency advantage due to its minimal diameter, performing exceptionally well under adversarial and varied synthetic loads.
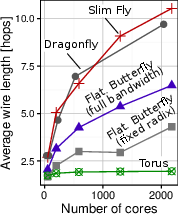
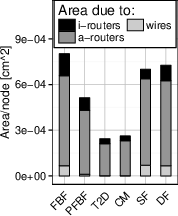
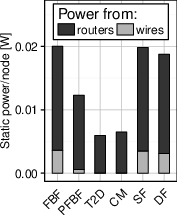
Figure 4: Disadvantages of Slim Fly used straightforwardly as NoCs; analysis showing notable improvements in Slim NoC.
Practical Implications and Future Directions
Slim NoC’s design principles set a precedent for future on-chip network topologies, making them highly adaptable to the scalable demands of next-generation processing units. The utilization of modern microarchitectural strategies and efficient layout models underscores its potential in manufacturing feasible, energy-efficient chips. The paper hints at further exploration in adaptive routing within Slim NoC for even greater performance tailoring and optimization.
Conclusion
The Slim NoC stands out as a sophisticated network topology solution for densely packed multi-core systems, masterfully bridging theoretical rigour with practical networking demands. Its unique combination of low-diameter graphical frameworks and efficient resource utilization presents a significant leap in achieving scalable and energy-efficient on-chip networks. Such innovations are pivotal in fulfilling the requirements of future computing paradigms, emphasizing the synergy between advanced design techniques and contemporary hardware challenges.