- The paper introduces a real-time streaming Transformer Transducer, integrating Transformer-XL and chunk-wise processing to efficiently handle large-scale speech data.
- The methodology leverages a hybrid model with a Transformer encoder and an LSTM predictor, yielding lower latency and improved WER compared to RNN-T.
- Experimental results validate that small look-ahead techniques and INT8 optimization reduce runtime costs without substantially compromising accuracy.
Introduction
The paper presents the development of a real-time streaming Transformer Transducer (T-T) model designed for automatic speech recognition (ASR) on large-scale datasets. Transformer-based end-to-end models have achieved notable success in various domains, including speech recognition. However, their application in real-time scenarios is hindered by high computational costs during inference. The authors address these issues by integrating the Transformer-XL architecture with chunk-wise processing, yielding a streamable model with high accuracy and low latency. The T-T model outperforms the recurrent neural network transducer (RNN-T), and attention-based Encoder-Decoder models in streaming scenarios, with runtime costs optimized by using a small look-ahead buffer.
Model Structure
The study examines the Transducer architecture for ASR, incorporating a Transformer model as the encoder and an LSTM model as the predictor. This choice leverages the speed and memory advantages of LSTM within the predictor while utilizing the transformative capabilities of Transformers in encoding acoustic features. The encoder calculates outputs from input sequences, and the predictor processes previous label sequences. These components are combined in a joint network, with computations expressed as follows:
ft=encoder(x1t)
gu−1=predictor(y1u−1)
ht,u−1=relu(ft+gu−1)
P(yu∣x1t,y1u−1)=softmax(Wo∗ht,u−1)
The Transformer model enhances the sequence modelling capabilities beyond what RNN-T models offer by employing multi-head attention (MHA) and relative positional embeddings, an approach that models the offset between frames to enhance the attention calculation.
Addressing computational cost challenges in streaming scenarios, the paper proposes truncated history and limited future information mechanisms within the attention mask, maintaining efficiency without compromising model accuracy. This mask restricts the right reception field, allowing only configured future frames lookup for computations. Figures illustrate the reception field and mask matrix design.
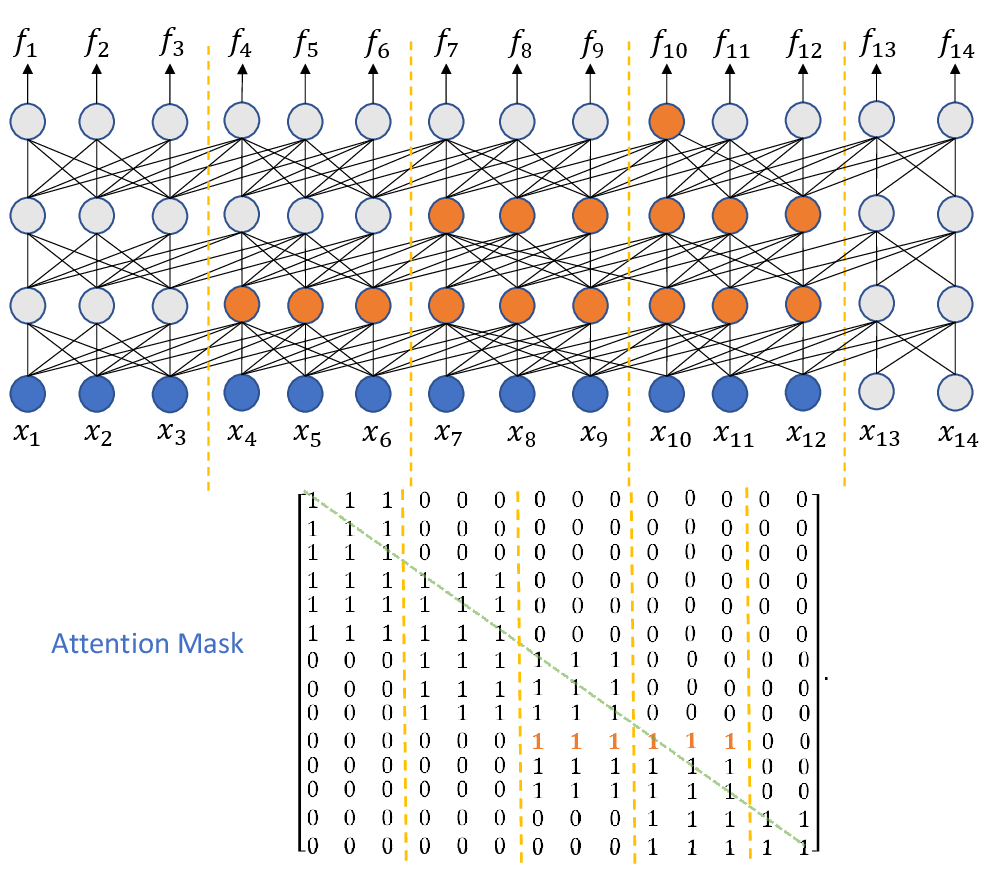
Figure 1: Attention mask for position x10.
Inference Optimizations
For efficient inference, caching accelerates computations by storing key-value pairs and using them in subsequent frames. Chunk-wise computation offers parallel processing benefits and reduces real-time factors in decoder operations, achieving optimal runtime performance by grouping input frames for simultaneous computation.
Experimental Results
Zero Look-ahead Scenario
In zero look-ahead evaluations, the T-T model with truncated history maintains accuracy with reduced runtime costs, outperforming RNN-T in both computational efficiency and word error rate (WER). The results reveal how chunk accumulation significantly increases processing speed relative to single-frame computations.
Small Look-ahead Setting
The T-T model exhibits remarkable consistency between streaming and offline settings, with its performance closely matching full context scenarios, demonstrating its viability for low-latency applications. By leveraging small look-ahead techniques, it achieves accuracy improvements while retaining manageable runtime factors.
8-bit Optimization
INT8 quantization is explored as a memory and computational optimization, presenting a substantial speedup without notable performance degradation, particularly for RNN-T. Although impacting WER slightly for T-T and C-T models, this technique illustrates practical deployment advantages through resource-efficient Inference.
Conclusion
The streaming Transformer Transducer model capitalizes on high-accuracy and low-latency traits, presenting a balanced approach between runtime cost, accuracy, and training efficiency. By integrating Transformer-XL and chunk-wise approaches, the model addresses performance challenges traditionally seen with deep Transformer architectures in real-time applications, positioning T-T and C-T as superior alternatives in streaming speech recognition domains. Future work will focus on further reducing latency without impacting model performance, ensuring its applicability across diverse real-world scenarios, emphasizing continued refinement in attention mechanisms and model optimization strategies.