- The paper introduces a novel adversarial approach that integrates adversarial examples into contrastive learning to improve negative pair mining.
- It employs FGSM to generate adversarial augmentations and a new scale parameter to balance the adversarial influence within the training process.
- Experimental results demonstrate improved downstream classification accuracy on datasets like CIFAR-10, CIFAR-100, and Tiny ImageNet compared to baselines.
Contrastive Learning with Adversarial Examples
Contrastive learning (CL) techniques are a significant segment of the self-supervised learning (SSL) landscape, focusing on deriving robust visual representations without labeled data. The presented paper, "Contrastive Learning with Adversarial Examples" (CLAE), introduces a novel methodology leveraging adversarial examples to enhance the efficacy of CL by formulating more challenging training pairs and improving negative pair mining.
Motivation and Methodology
Addressing Existing Gaps in Contrastive Learning
Traditional CL methods rely heavily on robust augmentation techniques to form positive pairs, enhancing the learning of invariant instance representations. However, less emphasis has been placed on optimizing the selection of challenging negative pairs, which are crucial for contrastive loss optimization. The paper proposes an adversarial approach to address these deficiencies, focusing on creating pairs that maximize the contrastive loss — formulating both hard negative and more diverse positive pairs.
Adversarial Example Integration
The integration of adversarial examples in CL is framed as a optimization problem, seeking perturbations of input images that increase classifier error likelihood without altering class predictions. This novel use of adversarial perturbations extends beyond traditional use-cases centered around model robustness against attacks. Instead, CLAE aims to improve overall model performance in unsupervised settings.
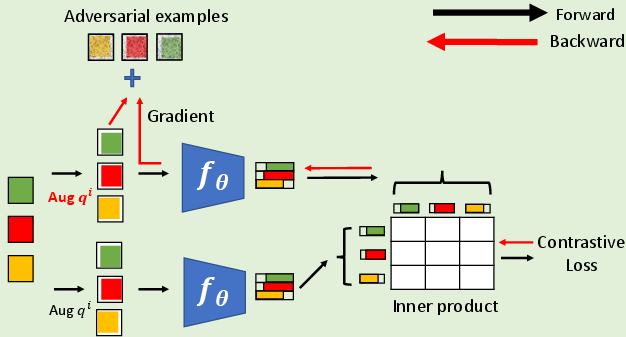
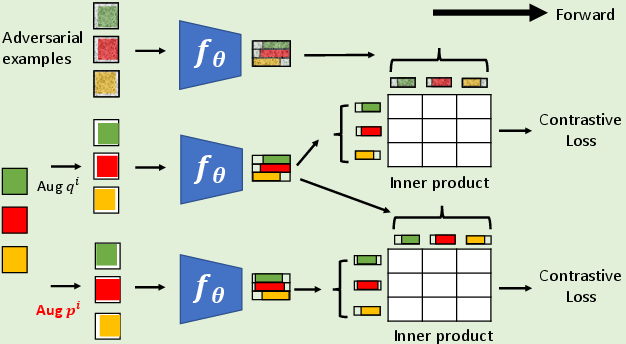
Figure 1: Generation of adversarial augmentations in step 4 of Algorithm.
Implementation Details
CLAE Algorithm
The CLAE algorithm modifies the traditional SSL pipeline by incorporating adversarial training elements. It uses a straightforward FGSM (Fast Gradient Sign Method) attack to generate adversarial examples, further balanced by a novel adversarial augmentation scale parameter (ϵ). This enhances the core contrastive loss function by integrating adversarial perturbations within the learning process.
A novel attribute of CLAE is the embedding of adversarial examples' characteristics into standard SSL tasks without requiring labeled data, ensuring its compatibility with prevalent CL methods.





Figure 2: Adversarial examples computed with the CLAE algorithm.
Dynamics of Adversarial Training
The CLAE framework involves computing gradients that consider the relationship of all examples within a batch, ensuring a holistic adversarial challenge that enhances the contrastive loss. It deploys dual batch normalization strategies to manage the statistics of clean versus adversarial examples effectively.
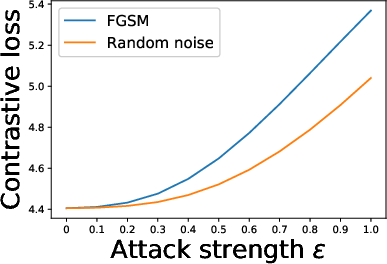
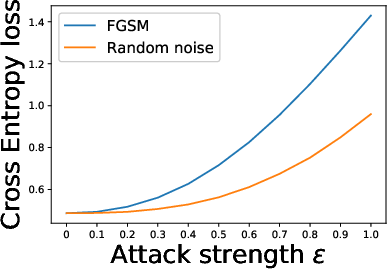
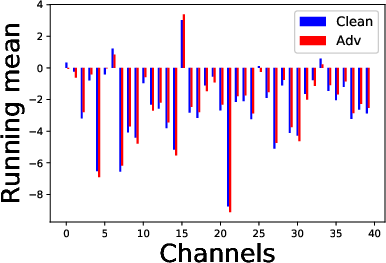
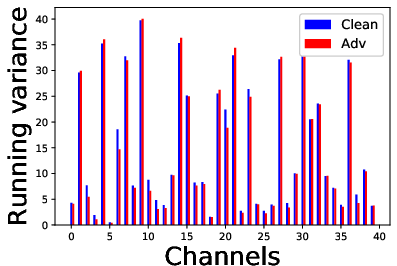
Figure 3: Effect of adversarial and random perturbations on contrastive and cross entropy losses.
Experimental Results
The study evaluates CLAE across datasets such as CIFAR-10, CIFAR-100, and Tiny ImageNet, showcasing improvements in downstream classification accuracy when compared to baselines not using adversarial examples. The results underscore the method's robustness in enhancing the performance of different contrastive learning frameworks, such as Plain, UEL, and SimCLR.
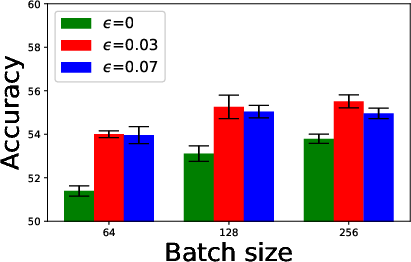
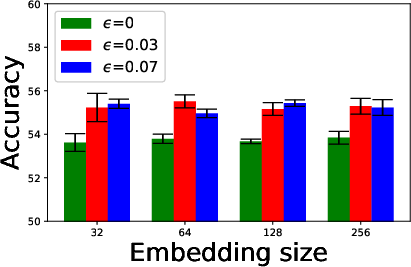
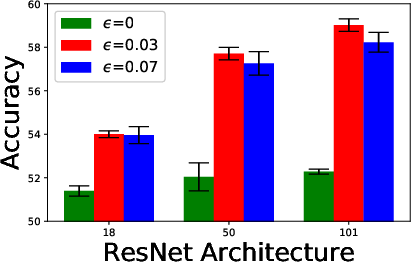
Figure 4: Ablation study of batch sizes, embedding dimensions, and ResNet architectures.
Hyperparameter Impacts
A detailed ablation study explored the influence of variables such as batch size, embedding dimensions, and network architectures. Key findings revealed that larger architectures disproportionately benefit from adversarial training due to their capacity for substantial learning.
Transfer Learning Capabilities
Furthermore, CLAE's transferability was tested across diverse datasets, yielding superior performance, especially in environments lacking direct analogs to training images. This positions CLAE as a versatile tool for broader SSL applications.
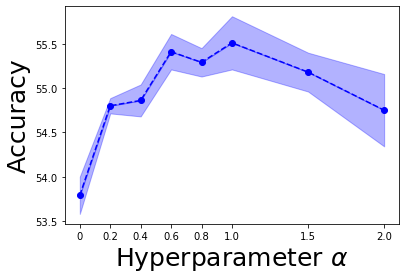
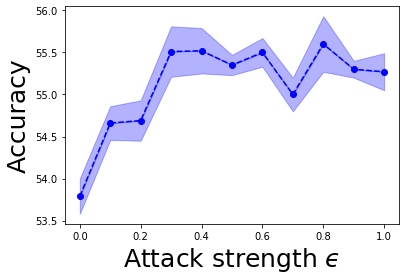
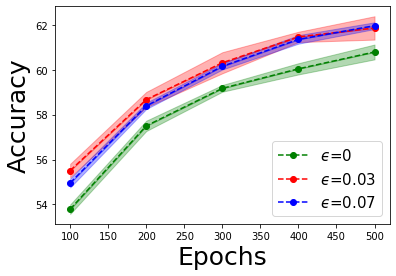
Figure 5: Ablation study for hyperparameter alpha, attack strength epsilon, and longer pretext training.
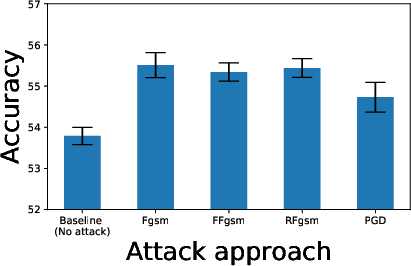
Figure 6: Comparison of transfer learning performance with linear evaluation to other image datasets.
Conclusion
CLAE demonstrates a substantial enhancement over existing unsupervised contrastive learning techniques by incorporating adversarial examples into the training process. This contributes to both the diversity of positive pairs and the difficulty of negative samples, fostering a more robust feature learning. Future research could expand on the adversarial metrics employed and further optimize transformations for varying data modalities, potentially driving even more substantial improvements in self-supervised learning domains.