- The paper demonstrates that standard metrics like ROUGE and BERTScore often capture topic similarity rather than true information overlap.
- It employs a token alignment framework and SCU-based analysis to quantify the disconnect between metric scores and actual summary content.
- The study proposes an interpretable token tuple matching method as an alternative approach to more accurately assess summarization quality.
Introduction
The automatic evaluation of summarization systems is crucial for the development and comparison of summarization models. The prevailing evaluation paradigm is reference-based, with metrics such as ROUGE and, more recently, BERTScore as standard choices. These metrics are widely used, often with the implicit assumption that their scores closely reflect the overlap in information content between candidate and reference summaries—an assumption that underpins both system development and research progress. This paper provides a formal and empirical analysis demonstrating that such metrics do not, in general, accurately measure information overlap, but rather topic similarity. It further introduces a methodology for directly assessing information overlap using interpretable content unit-aligned metrics.
Theoretical Framing: Token Alignment and Metric Design
The analysis begins with a formalization of ROUGE and BERTScore within a common framework based on token alignments. ROUGE-1 considers the count of shared unigrams, thus scoring summaries on direct lexical overlap. BERTScore assigns similarity between contextualized token embeddings, aligning each token in the candidate to its most similar reference counterpart. Both can be viewed as producing an alignment A between candidate and reference tokens, with the metric score being a (possibly weighted) sum over such alignments.
However, the metric score only reflects information overlap if the aligned tokens or spans encode the same informational content—a criterion that is fundamentally different from mere topical coincidence or surface lexical similarity.

Figure 1: Both candidate summaries align with the reference summary along different axes—one by information overlap, the other by topic similarity—underscoring the distinction that current metrics often conflate.
Empirical Dissection: SCU-Based and Category-Based Analyses
The experimental core leverages the Pyramid Method—an annotation technique in which expert annotators exhaustively identify all atomic information units, or "Summary Content Units" (SCUs), in candidate and reference summaries. By comparing where token-level alignments used by ROUGE and BERTScore fall with respect to these SCUs, the study provides strong quantitative evidence that these metric alignments seldom track true information recalls.
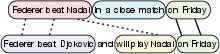
Figure 2: Example token alignment from ROUGE or BERTScore; only 2/5 alignments correspond to actual matches in information content per SCU annotation.
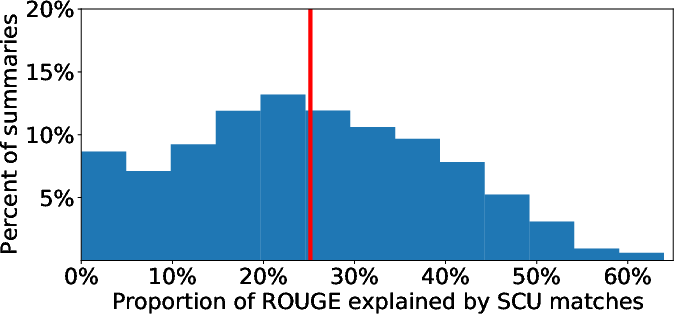
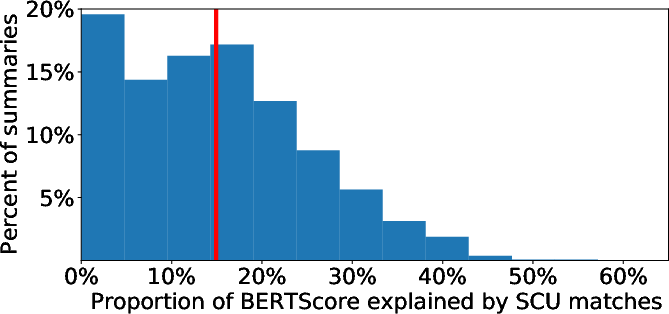
Figure 3: Distribution of the proportion of metric alignments attributable to SCU-matched content; mean proportions are 25% for ROUGE and 15% for BERTScore, indicating that a significant majority of metric credit accrues to non-information-overlapping alignments.
The second empirical analysis moves beyond SCUs and organizes alignments into interpretable syntactic and semantic categories, such as noun phrases, stopwords, part-of-speech tags, and dependency tuples. Contribution analyses reveal that the overwhelming majority of ROUGE and BERTScore alignment weight comes from <noun, stopword, noun-phrase chunk, named-entity> categories (i.e., broad topical placeholders), while dependency tuples—more indicative of actual information (e.g., subject-verb-object)—contribute negligibly.
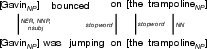
Figure 4: Every metric alignment is mapped to one or more interpretable linguistic categories, quantifying the weight of each content category (e.g., stopwords, named entities, tuples) in the overall metric score.
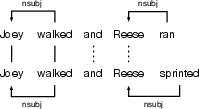
Figure 5: Example of higher-order dependency category (vb+nsubj); only alignments matching complete (verb, subject) structures contribute to the tuple-based information overlap metric.
Metric Extension: Interpretable Token Tuple Matching
To address this mismatch, the paper proposes an alternative, interpretable evaluation approach: define a set of fine-grained token tuples—derived from syntactic and semantic annotation—and compute precision/recall for only those tuples that correspond to real atomic information. This approach, effectively an automatic analog of content selection evaluation using the Pyramid Method, allows direct measurement of information overlap and meaningful system-level comparisons. When applied to state-of-the-art versus baseline summarization models, the information-overlap delta is informative—revealing gains that are missed by standard ROUGE/BERTScore, and also highlighting the significant remaining gap to human performance levels.
Generalization and Diagnostic Implications
The authors extend their findings to ten additional summarization evaluation metrics by analyzing the correlation of each with ROUGE-1 and the Pyramid Method. All metrics show stronger association to ROUGE than the gold-standard information overlap, and their information overlap correlations do not surpass ROUGE by meaningful margins, suggesting that the field has not yet produced a viable, scalable substitute for human content-unit annotation.
Furthermore, responsiveness (quality) judgments in prominent datasets have high system-level correlation with existing metrics despite these metrics failing to measure information overlap. This is attributed to the benchmarking datasets themselves, where topic similarity is an unduly strong surrogate for perceived summary quality, making it difficult to drive further metric innovation simply via such correlation coefficients.
Limitations and Theoretical Implications
The main limitation of the current study is its dependence on datasets and annotation schemas (e.g., TAC, CNN/DailyMail, Pyramid). While results are consistent across these datasets, broader application will require scalable, robust content-unit induction and annotation methods, potentially building on OpenIE and related information extraction advancements.
The findings have weighty theoretical and practical implications:
- Theoretical: Systematic progress towards informative, abstractive summarization is blocked without automatic metrics that reward actual content selection and transformation—not just surface- or topic-level alignment.
- Practical: Practitioners comparing summarization systems should refrain from over-interpreting improvements in ROUGE or BERTScore as corresponding to information gain, and should adopt, at minimum, interpretable, information-specific analytic tools.
Conclusion
The study provides compelling evidence that the most widely used automatic summarization metrics measure topic similarity, not information overlap, and that this disconnect persists across a wide array of metrics. The implications are substantial: it means decades of progress claimed via ROUGE-like metrics must be re-examined in light of what these metrics genuinely measure. The work sets out a path for more semantically-useful system diagnostics and confirms the indispensability of content-unit-aware reference construction (manual or high-quality automatic). Advances in automatic semantic parsing and OpenIE, and further benchmarking using information-centric metrics, are required before the field can operationalize evaluations that truly reflect summary information quality.