- The paper introduces a teacher-student framework where a teacher model is overfitted to a simulation track and its optimal policy is transferred to a student model.
- The methodology leverages randomization techniques (e.g., Gaussian noise, HSV shift) during student training to enhance model robustness in varying real-world conditions.
- Experimental results show the student model achieving a 52% completion rate and 0.23-second faster lap times compared to the teacher, significantly reducing the sim-to-real performance gap.
Sim-To-Real Transfer for Miniature Autonomous Car Racing
This paper addresses the challenges of sim-to-real transfer in the context of training deep reinforcement learning (DRL) models for miniature autonomous car racing. The authors propose a novel approach that involves using a teacher-student framework, where a teacher model is initially overfitted to a training track, and its expertise is then transferred to a student model. The key innovation is in enhancing the robustness of the trained models without sacrificing lap time performance.
Problem and Motivation
The paper identifies the sim-to-real gap as a major issue in deploying DRL models trained in simulations to real-world settings. Despite advances in DRL, models often perform suboptimally when shifted from simulated training environments to real-world applications due to discrepancies in environmental conditions such as lighting, texture, and background (Figure 1). This problem is particularly evident in autonomous driving scenarios where unsafe exploratory actions in real environments are impractical.
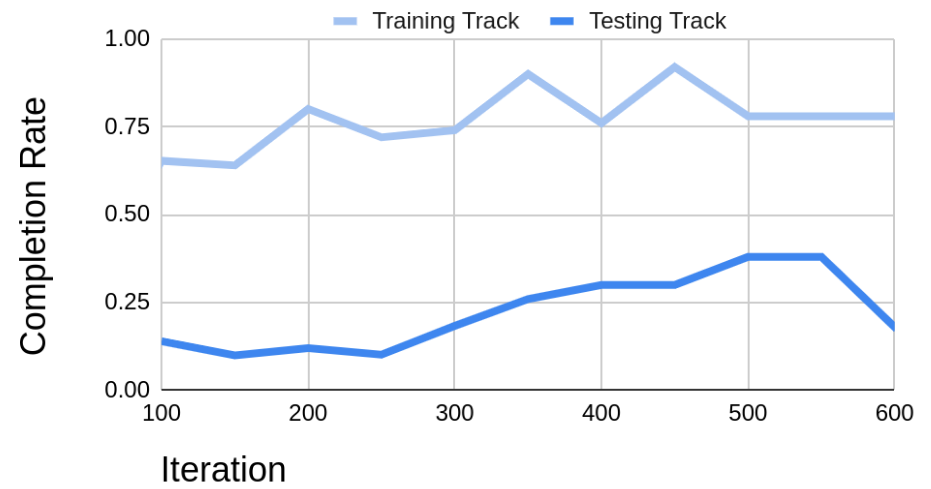
Figure 1: Completion rate of the same model, racing on the training track and the testing track. The horizontal axis represents the iterations of DRL training. This figure shows the performance drop when a model is transferred from the training environment to a different testing environment. At best, the testing track performance still had a 40% difference, which occurs in iteration 550.
Methodology
Teacher-Student Framework
The authors use a two-stage learning process involving a teacher and a student model. The teacher model is trained without randomization to overfit the training environment, with an optimal policy approximated for this setup. This policy serves as a benchmark for high-performance racing dynamics.
Randomization and Robustness
To bridge the sim-to-real gap, the authors introduce a set of randomization functions applied during the student model's training. These functions include Gaussian noise, reflection, HSV shift, salt and pepper noise, and cutout operations on the input images to improve the model's adaptability to varying environmental conditions observed during testing (Figure 2).

Figure 2: Various randomization effects added to observations, where (a) is the original observation. For (g), the red box is not part of the randomized image, and is only added to indicate the cutout area.
The student model is trained to emulate the teacher's actions on the original observations while handling randomized inputs, using a Huber-style loss function for robust behavior cloning.
Experimental Setup and Results
The experiments were conducted using AWS DeepRacer, focusing on tracks with identical shapes but different environmental properties to simulate real-world variability (Figure 3). Key outcomes demonstrate that student models trained with selective randomization outperform the teacher in terms of completion rates without sacrificing lap times.
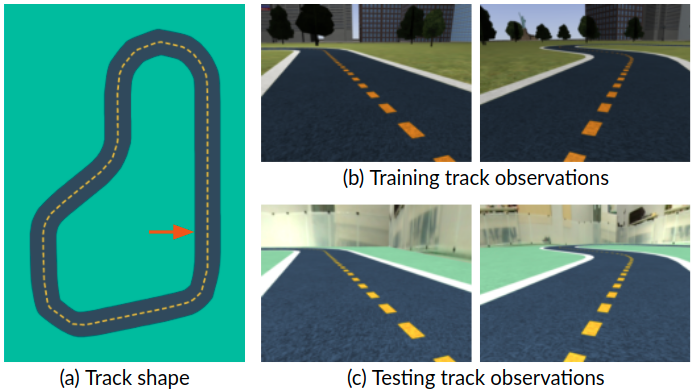
Figure 3: (a) The track shape for both the training and testing tracks. The starting position is indicated by the red arrow. (b) Observations captured on the training track. (c) Observations captured on the testing track.
The best student model achieved a completion rate of 52% compared to the teacher's 18.4%, with a 0.23-second faster average lap time, which is impactful given the 10-12 second lap durations typical in miniature racing.
Conclusion
The paper presents a novel method for achieving sim-to-real transfer in autonomous racing by leveraging a teacher-student model framework enhanced with domain randomization techniques. This method significantly improves the robustness of DRL policies while preserving or even enhancing lap time performance. Future work will extend these approaches to real-world evaluations and investigate adaptations for models using recurrent architectures or leveraging real-world observation data for further domain alignment.
This work is an essential contribution to the field of sim-to-real transfer, particularly in high-performance domains such as autonomous racing, where precision and adaptability are crucial.