- The paper introduces a novel online conformance checking method using incremental prefix-alignment computation to enable real-time deviation detection.
- It leverages Apache Kafka and distributed processing to achieve scalability and low latency in handling high-throughput event streams.
- Optimizations such as direct synchronizing and prefix-caching significantly reduce computational overhead and processing delays.
This paper explores a novel approach to online conformance checking using incremental prefix-alignment computation. It presents a distributed, scalable implementation designed to integrate seamlessly with high-throughput, low-latency streaming platforms.
Introduction
In process mining, conformance checking is crucial for ensuring that a process execution adheres to a given process model. Traditional conformance checking approaches are typically offline, focusing on completed process executions. This paper pivots towards online conformance checking, enabling real-time detection of deviations in ongoing processes, allowing for immediate countermeasures.

Figure 1: Idea of online conformance checking. Events are observed over time, e.g., activity "a" was executed for process instance "c_1". Upon receiving an event, we check if the newly observed event causes a deviation with respect to a reference model.
Incremental Prefix-Alignment Computation
The paper introduces a method for incrementally computing prefix-alignments in an event stream context. This method involves extending the synchronous product net (SPN) upon the reception of each new event. Cached intermediate search results are utilized to continue the search without recomputing from scratch, substantially improving efficiency.
Implementation Details
The implementation leverages Apache Kafka for its ability to handle distributed log processing and offers scalability via partitioned processing. This system architecture ensures fault tolerance and aligns with industry standards for robust, scalable streaming data solutions.
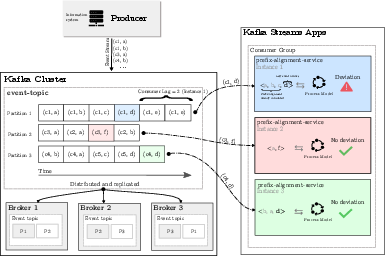
Figure 2: Architecture overview of the proposed implementation.
Key components include Kafka streams for handling distributed data flow, and the prefix-alignment-service instances operate on Kafka partitions to parallelize the conformance checking task across multiple nodes.
Optimizations: Direct Synchronizing and Prefix-Caching
Two significant optimizations enhance the proposed implementation: Direct Synchronizing and Prefix-Caching.
Direct Synchronizing
By identifying opportunities for direct synchronous moves upon event reception, the need for exhaustive shortest path searches is reduced. This method is particularly effective when the incoming event aligns directly with expected transitions, streamlining computational requirements.
Prefix-Caching
Adopted to avoid redundant computations for identical prefixes across different process instances, prefix-caching leverages cache strategies such as TinyLFU to manage memory efficiently. This approach prioritizes storing frequently accessed prefixes, discarding less crucial data when reaching memory constraints.
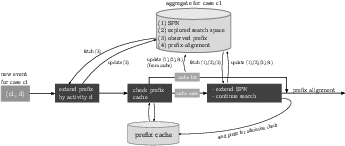
Figure 3: Overview of prefix-caching within our proposed implementation.
Evaluation
The implementation was evaluated using real-life event logs, demonstrating marked improvements in average computation times when employing the proposed optimizations.
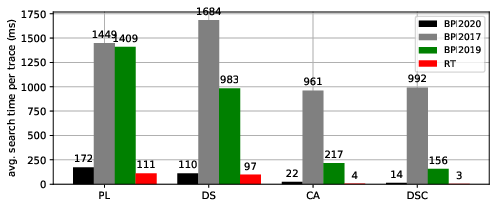
Figure 4: Average computation time (ms) per trace.
The enhancements led to a noticeable reduction in processing delays, crucial for maintaining low consumer lag in high-throughput environments.
Conclusion
The paper's implementation facilitates real-time conformance checking suitable for deployment in industrial streaming data environments. The integration of efficient data handling, aided by incremental and memory-optimized computation strategies, holds promise for enhancing process management in dynamic business settings. Future work will explore optimizing memory management further and refining mechanisms to determine process completion in an online setting.